 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuseRL: Dense Preference Optimization for Heterogeneous Model Fusion
Apr 09, 2025Heterogeneous model fusion enhances the performance of LLMs by integrating the knowledge and capabilities of multiple structurally diverse models. However, existing approaches often rely solely on selecting the best output for each prompt from source models, which underutilizes their full potential due to limited source knowledge and results in sparse optimization signals. To address this limitation, we propose FuseRL, a novel two-stage framework comprising FuseSFT and FusePO to maximize the utilization of source LLMs. FuseSFT establishes a robust initialization by integrating the strengths of heterogeneous source models through weighted supervised fine-tuning (SFT) on diverse outputs for each prompt. FusePO optimizes weighted preferences based on the outputs of multiple source models to enable superior alignment performance. Extensive experiments demonstrate the effectiveness of our framework across various preference alignment methods, including RLOO, DPO, and SimPO. Using Llama-3.1-8B-Instruct as the target model, our approach achieves state-of-the-art performance among 8B LLMs on the AlpacaEval-2 and Arena-Hard benchmarks. Further analysis suggests that FuseSFT regularizes the training process to reduce overfitting, while FusePO introduces dense and diverse signals for preference optimization.
Explainable Synthetic Image Detection through Diffusion Timestep Ensembling
Mar 08, 2025Recent advances in diffusion models have enabled the creation of deceptively real images, posing significant security risks when misused. In this study, we reveal that natural and synthetic images exhibit distinct differences in the high-frequency domains of their Fourier power spectra after undergoing iterative noise perturbations through an inverse multi-step denoising process, suggesting that such noise can provide additional discriminative information for identifying synthetic images. Based on this observation, we propose a novel detection method that amplifies these differences by progressively adding noise to the original images across multiple timesteps, and train an ensemble of classifiers on these noised images. To enhance human comprehension, we introduce an explanation generation and refinement module to identify flaws located in AI-generated images. Additionally, we construct two new datasets, GenHard and GenExplain, derived from the GenImage benchmark, providing detection samples of greater difficulty and high-quality rationales for fake images. Extensive experiments show that our method achieves state-of-the-art performance with 98.91% and 95.89% detection accuracy on regular and harder samples, increasing a minimal of 2.51% and 3.46% compared to baselines. Furthermore, our method also generalizes effectively to images generated by other diffusion models. Our code and datasets will be made publicly available.
Layer-Specific Scaling of Positional Encodings for Superior Long-Context Modeling
Mar 06, 2025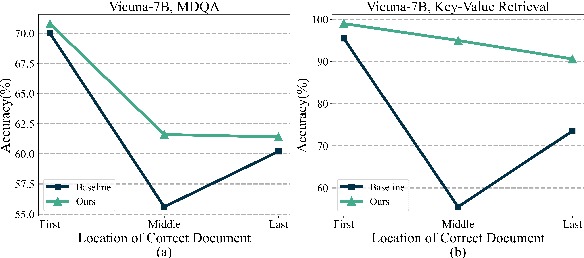



Although large language models (LLMs) have achieved significant progress in handling long-context inputs, they still suffer from the ``lost-in-the-middle'' problem, where crucial information in the middle of the context is often underrepresented or lost. Our extensive experiments reveal that this issue may arise from the rapid long-term decay in Rotary Position Embedding (RoPE). To address this problem, we propose a layer-specific positional encoding scaling method that assigns distinct scaling factors to each layer, slowing down the decay rate caused by RoPE to make the model pay more attention to the middle context. A specially designed genetic algorithm is employed to efficiently select the optimal scaling factors for each layer by incorporating Bezier curves to reduce the search space. Through comprehensive experimentation, we demonstrate that our method significantly alleviates the ``lost-in-the-middle'' problem. Our approach results in an average accuracy improvement of up to 20% on the Key-Value Retrieval dataset. Furthermore, we show that layer-specific interpolation, as opposed to uniform interpolation across all layers, enhances the model's extrapolation capabilities when combined with PI and Dynamic-NTK positional encoding schemes.
Weighted-Reward Preference Optimization for Implicit Model Fusion
Dec 04, 2024



While fusing heterogeneous open-source LLMs with varying architectures and sizes can potentially integrate the strengths of different models, existing fusion methods face significant challenges, such as vocabulary alignment and merging distribution matrices. These procedures are not only complex but also prone to introducing noise and errors. In this paper, we propose an implicit fusion method, Weighted-Reward Preference Optimization (WRPO), which leverages preference optimization between the source LLMs and the target LLM to transfer their capabilities effectively. WRPO eliminates the need for vocabulary alignment and matrix fusion and can be efficiently scaled to accommodate various LLMs. To address distributional deviations between the source and target LLMs, WRPO introduces a progressive adaptation strategy that gradually shifts reliance on preferred examples from the target LLM to the source LLMs. Extensive experiments on the MT-Bench, AlpacaEval-2, and Arena-Hard benchmarks demonstrate that WRPO consistently outperforms existing knowledge fusion methods and various fine-tuning baselines. When applied to LLaMA3-8B-Instruct as the target model, WRPO achieves a length-controlled win rate of 55.9% against GPT-4-Preview-1106 on AlpacaEval-2 and a win rate of 46.2% against GPT-4-0314 on Arena-Hard. Our code is available at \url{https://github.com/SLIT-AI/WRPO}.
ProFuser: Progressive Fusion of Large Language Models
Aug 09, 2024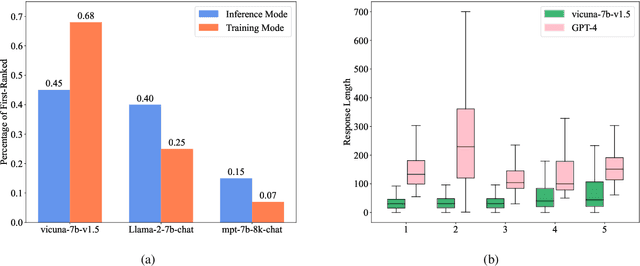
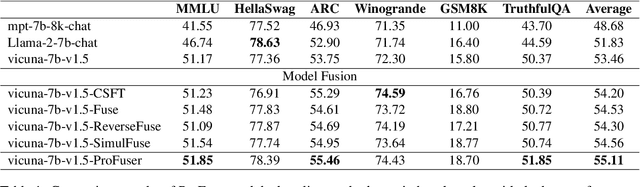

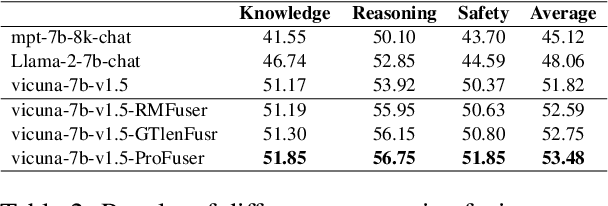
While fusing the capacities and advantages of various large language models (LLMs) offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during the training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including vicuna-7b-v1.5, Llama-2-7b-chat, and mpt-7b-8k-chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.
Searching for Best Practices in Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.
PsyCoT: Psychological Questionnaire as Powerful Chain-of-Thought for Personality Detection
Nov 05, 2023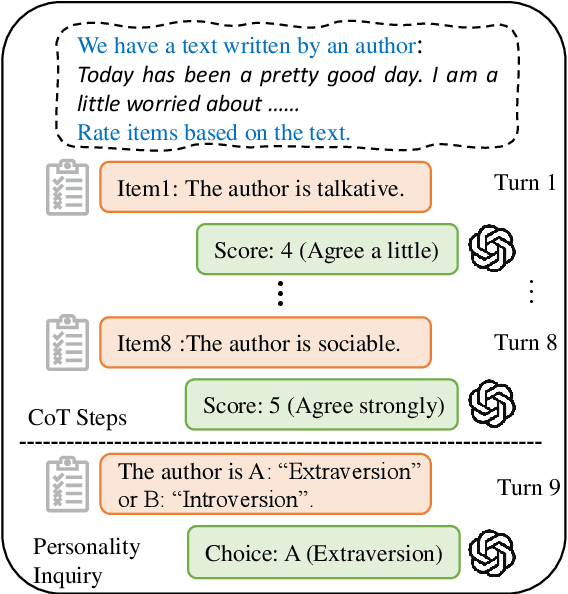
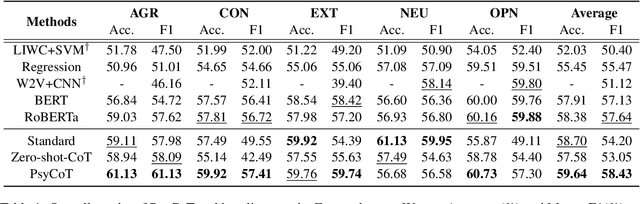

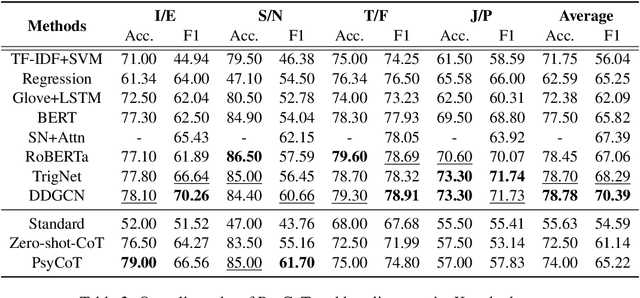
Recent advances in large language models (LLMs), such as ChatGPT, have showcased remarkable zero-shot performance across various NLP tasks. However, the potential of LLMs in personality detection, which involves identifying an individual's personality from their written texts, remains largely unexplored. Drawing inspiration from Psychological Questionnaires, which are carefully designed by psychologists to evaluate individual personality traits through a series of targeted items, we argue that these items can be regarded as a collection of well-structured chain-of-thought (CoT) processes. By incorporating these processes, LLMs can enhance their capabilities to make more reasonable inferences on personality from textual input. In light of this, we propose a novel personality detection method, called PsyCoT, which mimics the way individuals complete psychological questionnaires in a multi-turn dialogue manner. In particular, we employ a LLM as an AI assistant with a specialization in text analysis. We prompt the assistant to rate individual items at each turn and leverage the historical rating results to derive a conclusive personality preference. Our experiments demonstrate that PsyCoT significantly improves the performance and robustness of GPT-3.5 in personality detection, achieving an average F1 score improvement of 4.23/10.63 points on two benchmark datasets compared to the standard prompting method. Our code is available at https://github.com/TaoYang225/PsyCoT.
Dual-Feedback Knowledge Retrieval for Task-Oriented Dialogue Systems
Oct 23, 2023Efficient knowledge retrieval plays a pivotal role in ensuring the success of end-to-end task-oriented dialogue systems by facilitating the selection of relevant information necessary to fulfill user requests. However, current approaches generally integrate knowledge retrieval and response generation, which poses scalability challenges when dealing with extensive knowledge bases. Taking inspiration from open-domain question answering, we propose a retriever-generator architecture that harnesses a retriever to retrieve pertinent knowledge and a generator to generate system responses.~Due to the lack of retriever training labels, we propose relying on feedback from the generator as pseudo-labels to train the retriever. To achieve this, we introduce a dual-feedback mechanism that generates both positive and negative feedback based on the output of the generator. Our method demonstrates superior performance in task-oriented dialogue tasks, as evidenced by experimental results on three benchmark datasets.