 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate-to-Early Training: LET LLMs Learn Earlier, So Faster and Better
Feb 05, 2026As Large Language Models (LLMs) achieve remarkable empirical success through scaling model and data size, pretraining has become increasingly critical yet computationally prohibitive, hindering rapid development. Despite the availability of numerous pretrained LLMs developed at significant computational expense, a fundamental real-world question remains underexplored: \textit{Can we leverage existing small pretrained models to accelerate the training of larger models?} In this paper, we propose a Late-to-Early Training (LET) paradigm that enables LLMs to explicitly learn later knowledge in earlier steps and earlier layers. The core idea is to guide the early layers of an LLM during early training using representations from the late layers of a pretrained (i.e. late training phase) model. We identify two key mechanisms that drive LET's effectiveness: late-to-early-step learning and late-to-early-layer learning. These mechanisms significantly accelerate training convergence while robustly enhancing both language modeling capabilities and downstream task performance, enabling faster training with superior performance. Extensive experiments on 1.4B and 7B parameter models demonstrate LET's efficiency and effectiveness. Notably, when training a 1.4B LLM on the Pile dataset, our method achieves up to 1.6$\times$ speedup with nearly 5\% improvement in downstream task accuracy compared to standard training, even when using a pretrained model with 10$\times$ fewer parameters than the target model.
Mano: Restriking Manifold Optimization for LLM Training
Jan 30, 2026While large language models (LLMs) have emerged as a significant advancement in artificial intelligence, the hardware and computational costs for training LLMs are also significantly burdensome. Among the state-of-the-art optimizers, AdamW relies on diagonal curvature estimates and ignores structural properties, while Muon applies global spectral normalization at the expense of losing curvature information. In this study, we restriked manifold optimization methods for training LLMs, which may address both optimizers' limitations, while conventional manifold optimization methods have been largely overlooked due to the poor performance in large-scale model optimization. By innovatively projecting the momentum onto the tangent space of model parameters and constraining it on a rotational Oblique manifold, we propose a novel, powerful, and efficient optimizer **Mano** that is the first to bridge the performance gap between manifold optimization and modern optimizers. Extensive experiments on the LLaMA and Qwen3 models demonstrate that Mano consistently and significantly outperforms AdamW and Muon even with less memory consumption and computational complexity, respectively, suggesting an expanded Pareto frontier in terms of space and time efficiency.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.
Class-wise Activation Unravelling the Engima of Deep Double Descent
May 13, 2024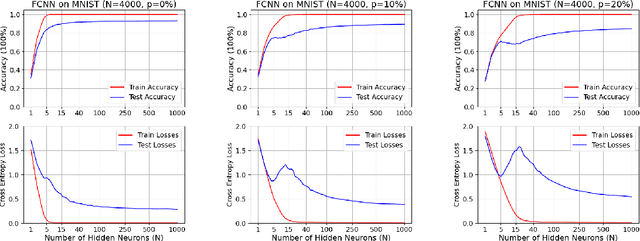



Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory for its occurring mechanism in deep learning remains yet to be established. In this study, we revisited the phenomenon of double descent and discussed the conditions of its occurrence. This paper introduces the concept of class-activation matrices and a methodology for estimating the effective complexity of functions, on which we unveil that over-parameterized models exhibit more distinct and simpler class patterns in hidden activations compared to under-parameterized ones. We further looked into the interpolation of noisy labelled data among clean representations and demonstrated overfitting w.r.t. expressive capacity. By comprehensively analysing hypotheses and presenting corresponding empirical evidence that either validates or contradicts these hypotheses, we aim to provide fresh insights into the phenomenon of double descent and benign over-parameterization and facilitate future explorations. By comprehensively studying different hypotheses and the corresponding empirical evidence either supports or challenges these hypotheses, our goal is to offer new insights into the phenomena of double descent and benign over-parameterization, thereby enabling further explorations in the field. The source code is available at https://github.com/Yufei-Gu-451/sparse-generalization.git.
Unraveling the Enigma of Double Descent: An In-depth Analysis through the Lens of Learned Feature Space
Oct 20, 2023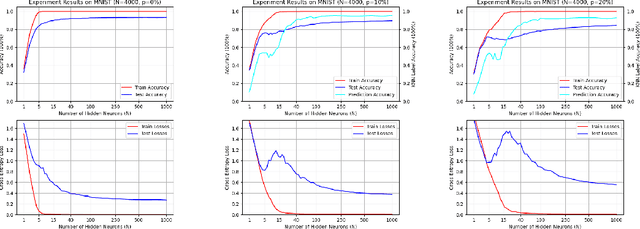
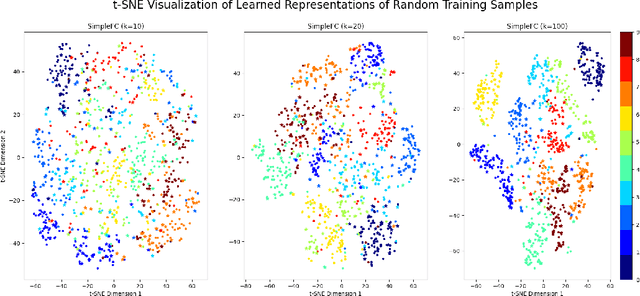
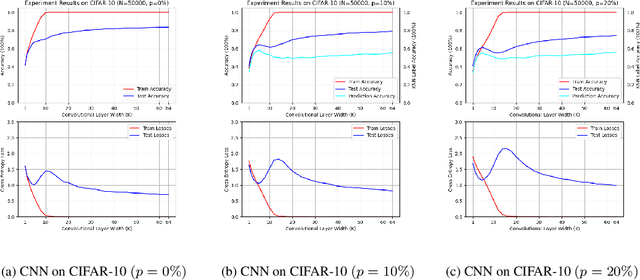
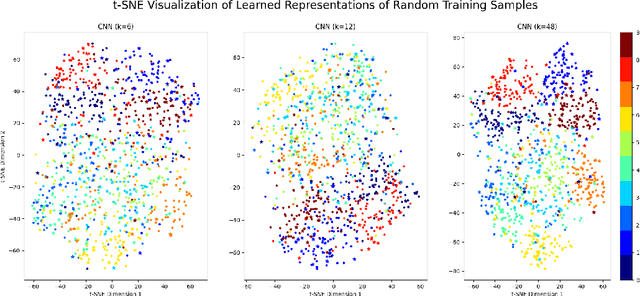
Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory to account for its occurrence in deep learning remains yet to be established. In this study, we revisit the phenomenon of double descent and demonstrate that its occurrence is strongly influenced by the presence of noisy data. Through conducting a comprehensive analysis of the feature space of learned representations, we unveil that double descent arises in imperfect models trained with noisy data. We argue that double descent is a consequence of the model first learning the noisy data until interpolation and then adding implicit regularization via over-parameterization acquiring therefore capability to separate the information from the noise. We postulate that double descent should never occur in well-regularized models.