 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Regularized PCA
Jan 15, 2026High-dimensional data often exhibit dependencies among variables that violate the isotropic-noise assumption under which principal component analysis (PCA) is optimal. For cases where the noise is not independent and identically distributed across features (i.e., the covariance is not spherical) we introduce Graph Regularized PCA (GR-PCA). It is a graph-based regularization of PCA that incorporates the dependency structure of the data features by learning a sparse precision graph and biasing loadings toward the low-frequency Fourier modes of the corresponding graph Laplacian. Consequently, high-frequency signals are suppressed, while graph-coherent low-frequency ones are preserved, yielding interpretable principal components aligned with conditional relationships. We evaluate GR-PCA on synthetic data spanning diverse graph topologies, signal-to-noise ratios, and sparsity levels. Compared to mainstream alternatives, it concentrates variance on the intended support, produces loadings with lower graph-Laplacian energy, and remains competitive in out-of-sample reconstruction. When high-frequency signals are present, the graph Laplacian penalty prevents overfitting, reducing the reconstruction accuracy but improving structural fidelity. The advantage over PCA is most pronounced when high-frequency signals are graph-correlated, whereas PCA remains competitive when such signals are nearly rotationally invariant. The procedure is simple to implement, modular with respect to the precision estimator, and scalable, providing a practical route to structure-aware dimensionality reduction that improves structural fidelity without sacrificing predictive performance.
Information Filtering Networks: Theoretical Foundations, Generative Methodologies, and Real-World Applications
May 02, 2025
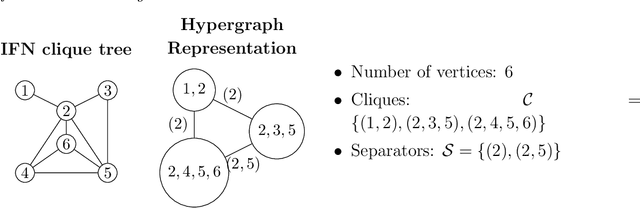
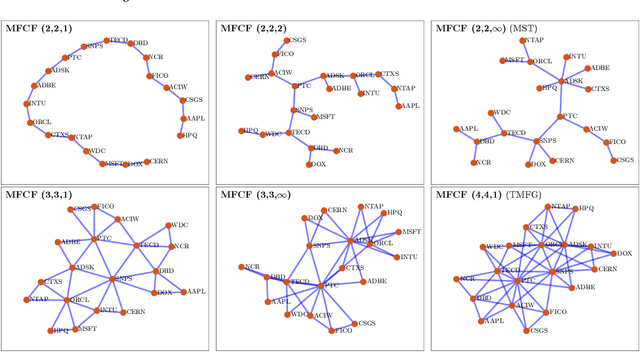
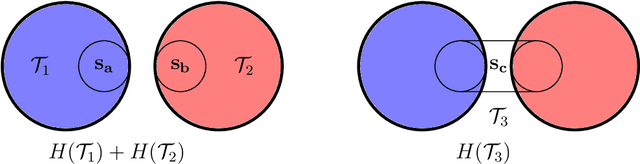
Information Filtering Networks (IFNs) provide a powerful framework for modeling complex systems through globally sparse yet locally dense and interpretable structures that capture multivariate dependencies. This review offers a comprehensive account of IFNs, covering their theoretical foundations, construction methodologies, and diverse applications. Tracing their origins from early network-based models to advanced formulations such as the Triangulated Maximally Filtered Graph (TMFG) and the Maximally Filtered Clique Forest (MFCF), the paper highlights how IFNs address key challenges in high-dimensional data-driven modeling. IFNs and their construction methodologies are intrinsically higher-order networks that generate simplicial complexes-structures that are only now becoming popular in the broader literature. Applications span fields including finance, biology, psychology, and artificial intelligence, where IFNs improve interpretability, computational efficiency, and predictive performance. Special attention is given to their role in graphical modeling, where IFNs enable the estimation of sparse inverse covariance matrices with greater accuracy and scalability than traditional approaches like Graphical LASSO. Finally, the review discusses recent developments that integrate IFNs with machine learning and deep learning, underscoring their potential not only to bridge classical network theory with contemporary data-driven paradigms, but also to shape the architectures of deep learning models themselves.
Granger Causality Detection with Kolmogorov-Arnold Networks
Dec 19, 2024



Discovering causal relationships in time series data is central in many scientific areas, ranging from economics to climate science. Granger causality is a powerful tool for causality detection. However, its original formulation is limited by its linear form and only recently nonlinear machine-learning generalizations have been introduced. This study contributes to the definition of neural Granger causality models by investigating the application of Kolmogorov-Arnold networks (KANs) in Granger causality detection and comparing their capabilities against multilayer perceptrons (MLP). In this work, we develop a framework called Granger Causality KAN (GC-KAN) along with a tailored training approach designed specifically for Granger causality detection. We test this framework on both Vector Autoregressive (VAR) models and chaotic Lorenz-96 systems, analysing the ability of KANs to sparsify input features by identifying Granger causal relationships, providing a concise yet accurate model for Granger causality detection. Our findings show the potential of KANs to outperform MLPs in discerning interpretable Granger causal relationships, particularly for the ability of identifying sparse Granger causality patterns in high-dimensional settings, and more generally, the potential of AI in causality discovery for the dynamical laws in physical systems.
HLOB -- Information Persistence and Structure in Limit Order Books
May 30, 2024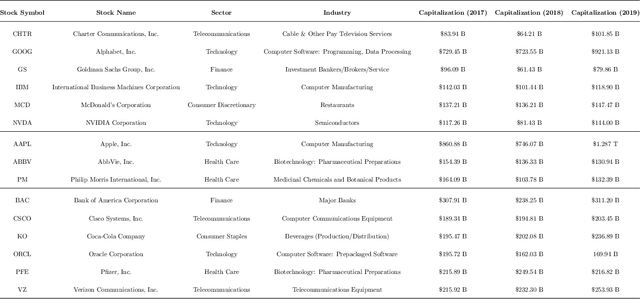
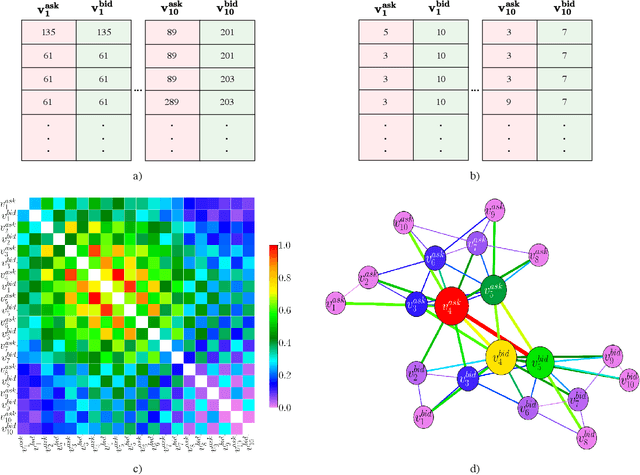

We introduce a novel large-scale deep learning model for Limit Order Book mid-price changes forecasting, and we name it `HLOB'. This architecture (i) exploits the information encoded by an Information Filtering Network, namely the Triangulated Maximally Filtered Graph, to unveil deeper and non-trivial dependency structures among volume levels; and (ii) guarantees deterministic design choices to handle the complexity of the underlying system by drawing inspiration from the groundbreaking class of Homological Convolutional Neural Networks. We test our model against 9 state-of-the-art deep learning alternatives on 3 real-world Limit Order Book datasets, each including 15 stocks traded on the NASDAQ exchange, and we systematically characterize the scenarios where HLOB outperforms state-of-the-art architectures. Our approach sheds new light on the spatial distribution of information in Limit Order Books and on its degradation over increasing prediction horizons, narrowing the gap between microstructural modeling and deep learning-based forecasting in high-frequency financial markets.
Deep Limit Order Book Forecasting
Mar 27, 2024



We exploit cutting-edge deep learning methodologies to explore the predictability of high-frequency Limit Order Book mid-price changes for a heterogeneous set of stocks traded on the NASDAQ exchange. In so doing, we release `LOBFrame', an open-source code base to efficiently process large-scale Limit Order Book data and quantitatively assess state-of-the-art deep learning models' forecasting capabilities. Our results are twofold. We demonstrate that the stocks' microstructural characteristics influence the efficacy of deep learning methods and that their high forecasting power does not necessarily correspond to actionable trading signals. We argue that traditional machine learning metrics fail to adequately assess the quality of forecasts in the Limit Order Book context. As an alternative, we propose an innovative operational framework that evaluates predictions' practicality by focusing on the probability of accurately forecasting complete transactions. This work offers academics and practitioners an avenue to make informed and robust decisions on the application of deep learning techniques, their scope and limitations, effectively exploiting emergent statistical properties of the Limit Order Book.
Unraveling the Enigma of Double Descent: An In-depth Analysis through the Lens of Learned Feature Space
Oct 20, 2023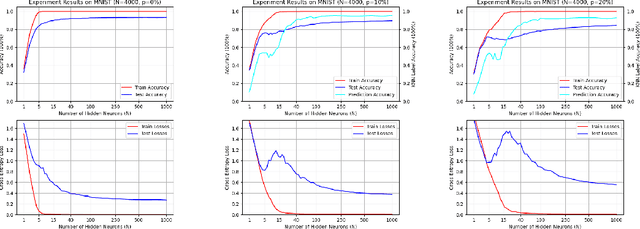
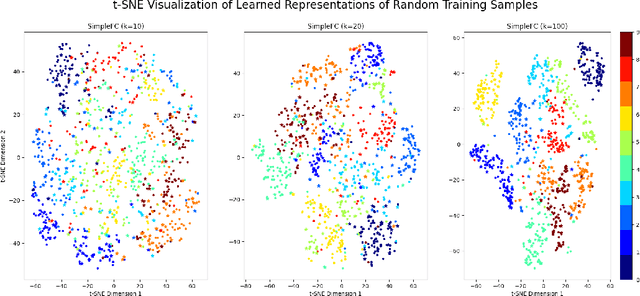
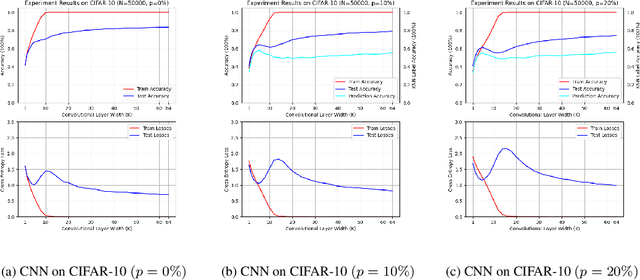
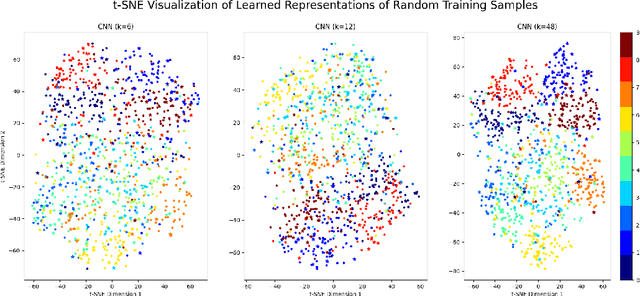
Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory to account for its occurrence in deep learning remains yet to be established. In this study, we revisit the phenomenon of double descent and demonstrate that its occurrence is strongly influenced by the presence of noisy data. Through conducting a comprehensive analysis of the feature space of learned representations, we unveil that double descent arises in imperfect models trained with noisy data. We argue that double descent is a consequence of the model first learning the noisy data until interpolation and then adding implicit regularization via over-parameterization acquiring therefore capability to separate the information from the noise. We postulate that double descent should never occur in well-regularized models.
Homological Convolutional Neural Networks
Aug 26, 2023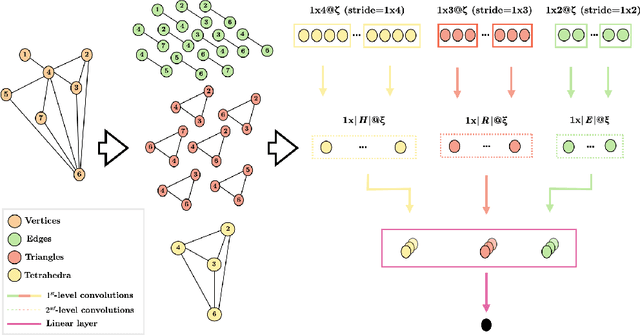

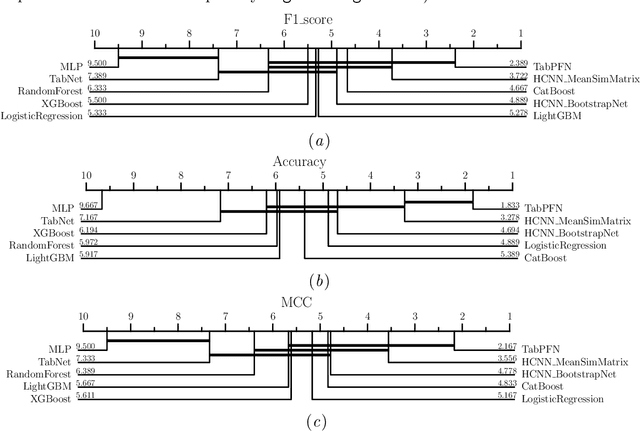

Deep learning methods have demonstrated outstanding performances on classification and regression tasks on homogeneous data types (e.g., image, audio, and text data). However, tabular data still poses a challenge with classic machine learning approaches being often computationally cheaper and equally effective than increasingly complex deep learning architectures. The challenge arises from the fact that, in tabular data, the correlation among features is weaker than the one from spatial or semantic relationships in images or natural languages, and the dependency structures need to be modeled without any prior information. In this work, we propose a novel deep learning architecture that exploits the data structural organization through topologically constrained network representations to gain spatial information from sparse tabular data. The resulting model leverages the power of convolutions and is centered on a limited number of concepts from network topology to guarantee (i) a data-centric, deterministic building pipeline; (ii) a high level of interpretability over the inference process; and (iii) an adequate room for scalability. We test our model on 18 benchmark datasets against 5 classic machine learning and 3 deep learning models demonstrating that our approach reaches state-of-the-art performances on these challenging datasets. The code to reproduce all our experiments is provided at https://github.com/FinancialComputingUCL/HomologicalCNN.
Homological Neural Networks: A Sparse Architecture for Multivariate Complexity
Jun 27, 2023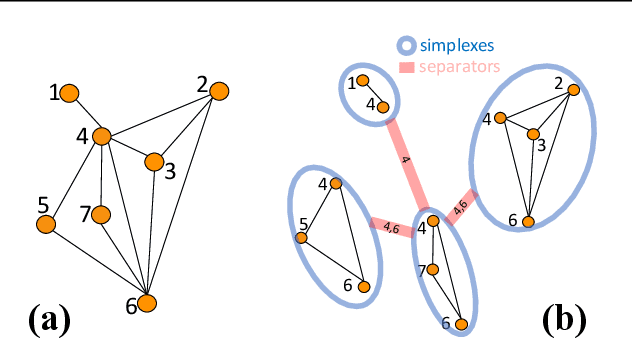
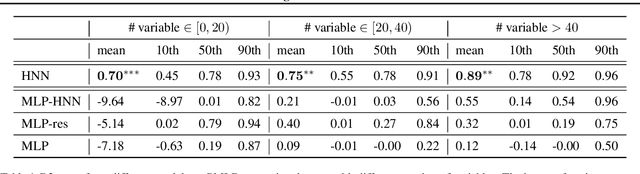
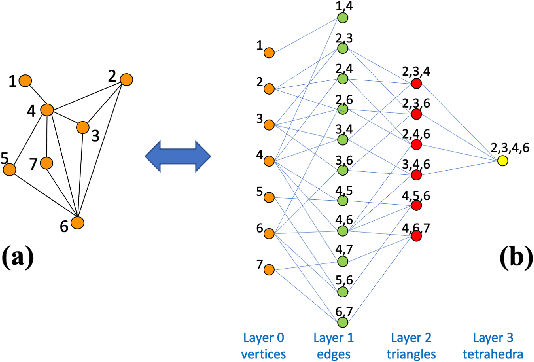
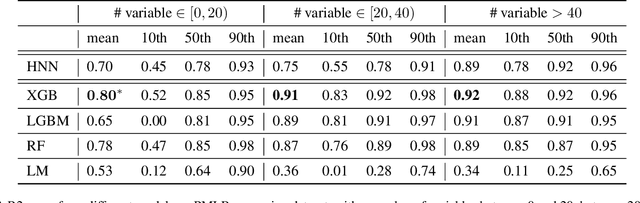
The rapid progress of Artificial Intelligence research came with the development of increasingly complex deep learning models, leading to growing challenges in terms of computational complexity, energy efficiency and interpretability. In this study, we apply advanced network-based information filtering techniques to design a novel deep neural network unit characterized by a sparse higher-order graphical architecture built over the homological structure of underlying data. We demonstrate its effectiveness in two application domains which are traditionally challenging for deep learning: tabular data and time series regression problems. Results demonstrate the advantages of this novel design which can tie or overcome the results of state-of-the-art machine learning and deep learning models using only a fraction of parameters.
Topological Feature Selection: A Graph-Based Filter Feature Selection Approach
Feb 19, 2023



In this paper, we introduce a novel unsupervised, graph-based filter feature selection technique which exploits the power of topologically constrained network representations. We model dependency structures among features using a family of chordal graphs (the Triangulated Maximally Filtered Graph), and we maximise the likelihood of features' relevance by studying their relative position inside the network. Such an approach presents three aspects that are particularly satisfactory compared to its alternatives: (i) it is highly tunable and easily adaptable to the nature of input data; (ii) it is fully explainable, maintaining, at the same time, a remarkable level of simplicity; (iii) it is computationally cheaper compared to its alternatives. We test our algorithm on 16 benchmark datasets from different applicative domains showing that it outperforms or matches the current state-of-the-art under heterogeneous evaluation conditions.
Regime-based Implied Stochastic Volatility Model for Crypto Option Pricing
Aug 15, 2022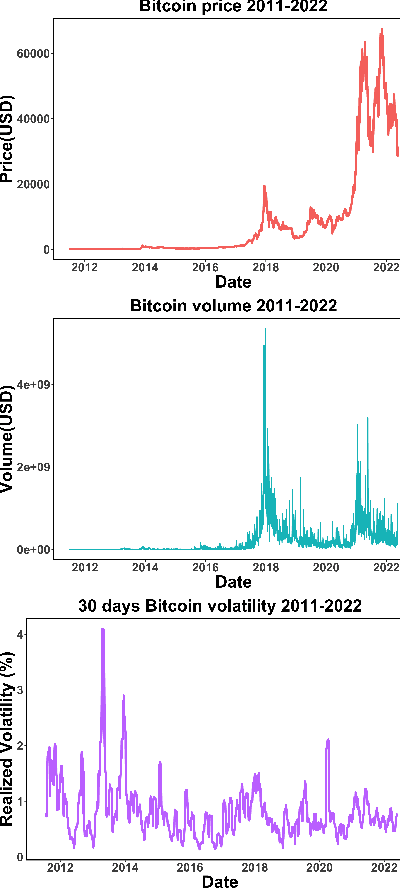
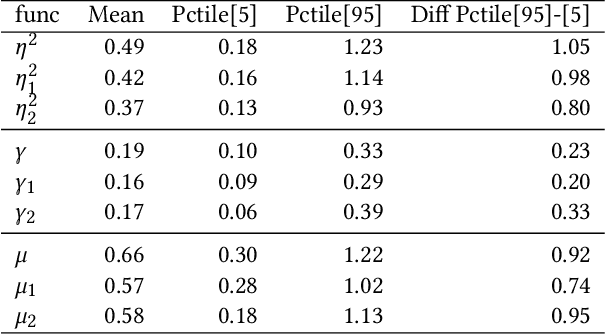
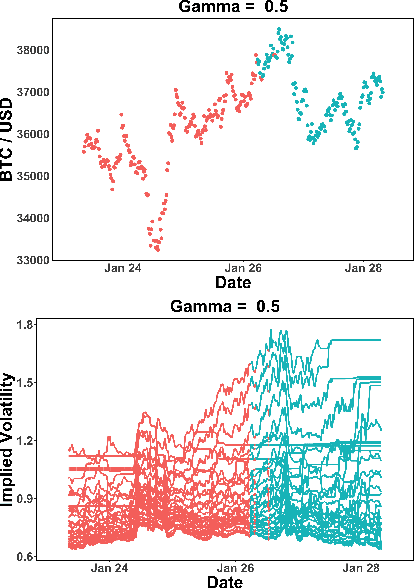
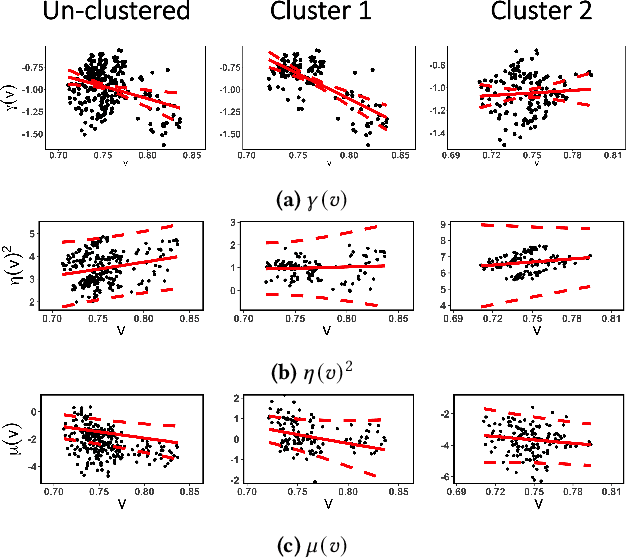
The increasing adoption of Digital Assets (DAs), such as Bitcoin (BTC), rises the need for accurate option pricing models. Yet, existing methodologies fail to cope with the volatile nature of the emerging DAs. Many models have been proposed to address the unorthodox market dynamics and frequent disruptions in the microstructure caused by the non-stationarity, and peculiar statistics, in DA markets. However, they are either prone to the curse of dimensionality, as additional complexity is required to employ traditional theories, or they overfit historical patterns that may never repeat. Instead, we leverage recent advances in market regime (MR) clustering with the Implied Stochastic Volatility Model (ISVM). Time-regime clustering is a temporal clustering method, that clusters the historic evolution of a market into different volatility periods accounting for non-stationarity. ISVM can incorporate investor expectations in each of the sentiment-driven periods by using implied volatility (IV) data. In this paper, we applied this integrated time-regime clustering and ISVM method (termed MR-ISVM) to high-frequency data on BTC options at the popular trading platform Deribit. We demonstrate that MR-ISVM contributes to overcome the burden of complex adaption to jumps in higher order characteristics of option pricing models. This allows us to price the market based on the expectations of its participants in an adaptive fashion.