 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLOB -- Information Persistence and Structure in Limit Order Books
May 30, 2024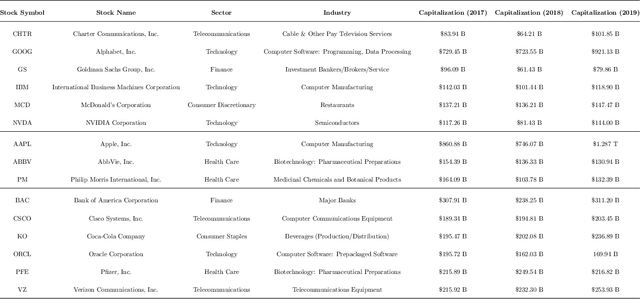
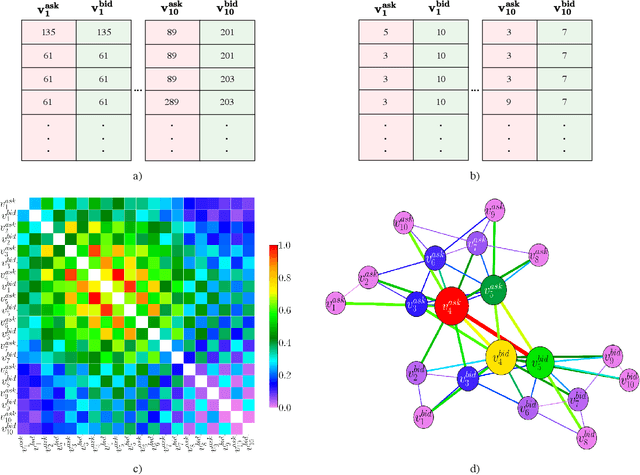

We introduce a novel large-scale deep learning model for Limit Order Book mid-price changes forecasting, and we name it `HLOB'. This architecture (i) exploits the information encoded by an Information Filtering Network, namely the Triangulated Maximally Filtered Graph, to unveil deeper and non-trivial dependency structures among volume levels; and (ii) guarantees deterministic design choices to handle the complexity of the underlying system by drawing inspiration from the groundbreaking class of Homological Convolutional Neural Networks. We test our model against 9 state-of-the-art deep learning alternatives on 3 real-world Limit Order Book datasets, each including 15 stocks traded on the NASDAQ exchange, and we systematically characterize the scenarios where HLOB outperforms state-of-the-art architectures. Our approach sheds new light on the spatial distribution of information in Limit Order Books and on its degradation over increasing prediction horizons, narrowing the gap between microstructural modeling and deep learning-based forecasting in high-frequency financial markets.
Deep Limit Order Book Forecasting
Mar 27, 2024



We exploit cutting-edge deep learning methodologies to explore the predictability of high-frequency Limit Order Book mid-price changes for a heterogeneous set of stocks traded on the NASDAQ exchange. In so doing, we release `LOBFrame', an open-source code base to efficiently process large-scale Limit Order Book data and quantitatively assess state-of-the-art deep learning models' forecasting capabilities. Our results are twofold. We demonstrate that the stocks' microstructural characteristics influence the efficacy of deep learning methods and that their high forecasting power does not necessarily correspond to actionable trading signals. We argue that traditional machine learning metrics fail to adequately assess the quality of forecasts in the Limit Order Book context. As an alternative, we propose an innovative operational framework that evaluates predictions' practicality by focusing on the probability of accurately forecasting complete transactions. This work offers academics and practitioners an avenue to make informed and robust decisions on the application of deep learning techniques, their scope and limitations, effectively exploiting emergent statistical properties of the Limit Order Book.
MindTheDApp: A Toolchain for Complex Network-Driven Structural Analysis of Ethereum-based Decentralised Applications
Oct 03, 2023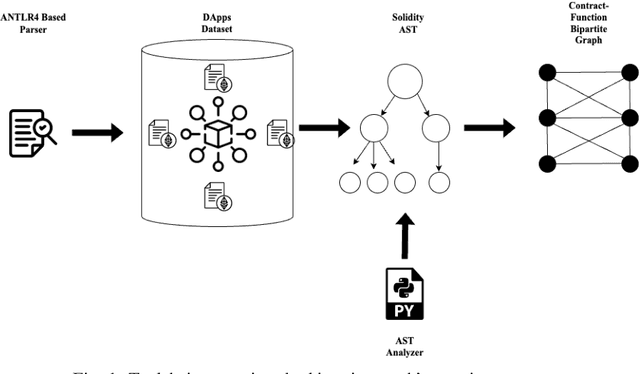

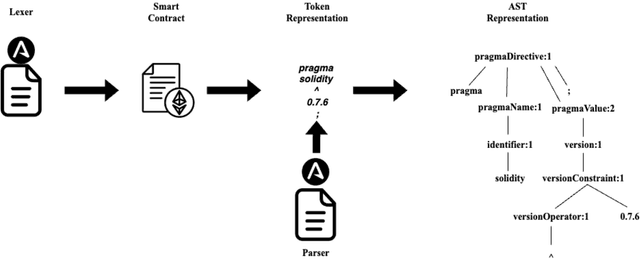
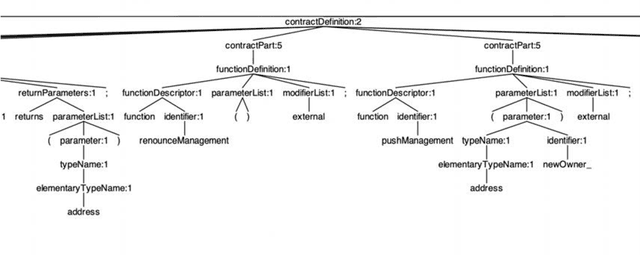
This paper presents MindTheDApp, a toolchain designed specifically for the structural analysis of Ethereum-based Decentralized Applications (DApps), with a distinct focus on a complex network-driven approach. Unlike existing tools, our toolchain combines the power of ANTLR4 and Abstract Syntax Tree (AST) traversal techniques to transform the architecture and interactions within smart contracts into a specialized bipartite graph. This enables advanced network analytics to highlight operational efficiencies within the DApp's architecture. The bipartite graph generated by the proposed tool comprises two sets of nodes: one representing smart contracts, interfaces, and libraries, and the other including functions, events, and modifiers. Edges in the graph connect functions to smart contracts they interact with, offering a granular view of interdependencies and execution flow within the DApp. This network-centric approach allows researchers and practitioners to apply complex network theory in understanding the robustness, adaptability, and intricacies of decentralized systems. Our work contributes to the enhancement of security in smart contracts by allowing the visualisation of the network, and it provides a deep understanding of the architecture and operational logic within DApps. Given the growing importance of smart contracts in the blockchain ecosystem and the emerging application of complex network theory in technology, our toolchain offers a timely contribution to both academic research and practical applications in the field of blockchain technology.
Homological Convolutional Neural Networks
Aug 26, 2023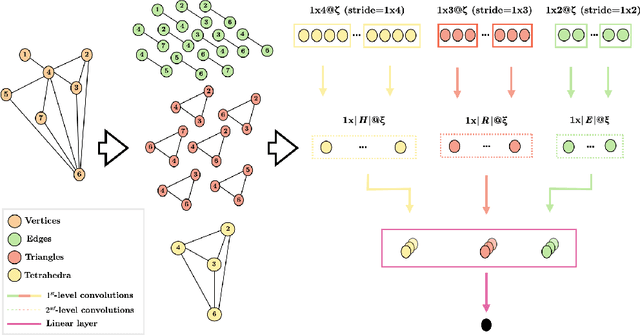

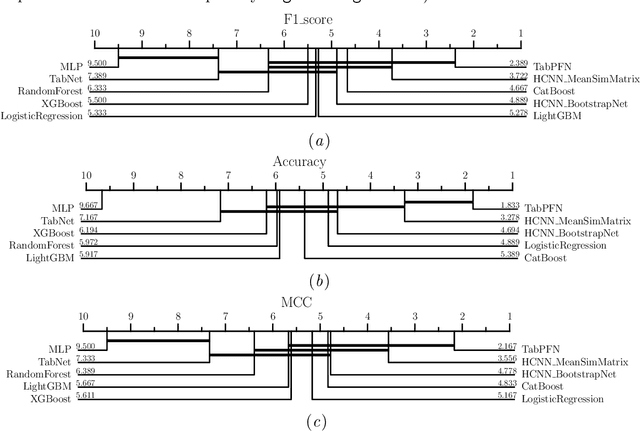

Deep learning methods have demonstrated outstanding performances on classification and regression tasks on homogeneous data types (e.g., image, audio, and text data). However, tabular data still poses a challenge with classic machine learning approaches being often computationally cheaper and equally effective than increasingly complex deep learning architectures. The challenge arises from the fact that, in tabular data, the correlation among features is weaker than the one from spatial or semantic relationships in images or natural languages, and the dependency structures need to be modeled without any prior information. In this work, we propose a novel deep learning architecture that exploits the data structural organization through topologically constrained network representations to gain spatial information from sparse tabular data. The resulting model leverages the power of convolutions and is centered on a limited number of concepts from network topology to guarantee (i) a data-centric, deterministic building pipeline; (ii) a high level of interpretability over the inference process; and (iii) an adequate room for scalability. We test our model on 18 benchmark datasets against 5 classic machine learning and 3 deep learning models demonstrating that our approach reaches state-of-the-art performances on these challenging datasets. The code to reproduce all our experiments is provided at https://github.com/FinancialComputingUCL/HomologicalCNN.
A Preliminary Analysis on the Code Generation Capabilities of GPT-3.5 and Bard AI Models for Java Functions
May 16, 2023
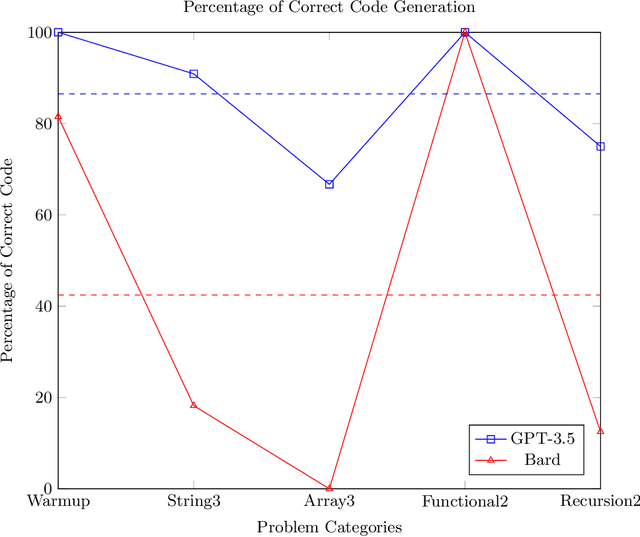


This paper evaluates the capability of two state-of-the-art artificial intelligence (AI) models, GPT-3.5 and Bard, in generating Java code given a function description. We sourced the descriptions from CodingBat.com, a popular online platform that provides practice problems to learn programming. We compared the Java code generated by both models based on correctness, verified through the platform's own test cases. The results indicate clear differences in the capabilities of the two models. GPT-3.5 demonstrated superior performance, generating correct code for approximately 90.6% of the function descriptions, whereas Bard produced correct code for 53.1% of the functions. While both models exhibited strengths and weaknesses, these findings suggest potential avenues for the development and refinement of more advanced AI-assisted code generation tools. The study underlines the potential of AI in automating and supporting aspects of software development, although further research is required to fully realize this potential.
On Technical Trading and Social Media Indicators in Cryptocurrencies' Price Classification Through Deep Learning
Feb 17, 2021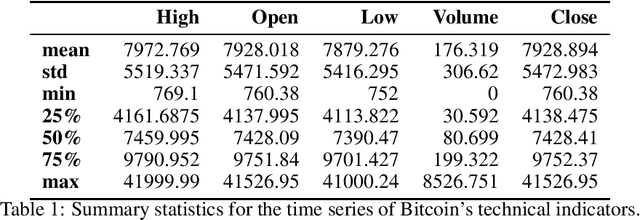
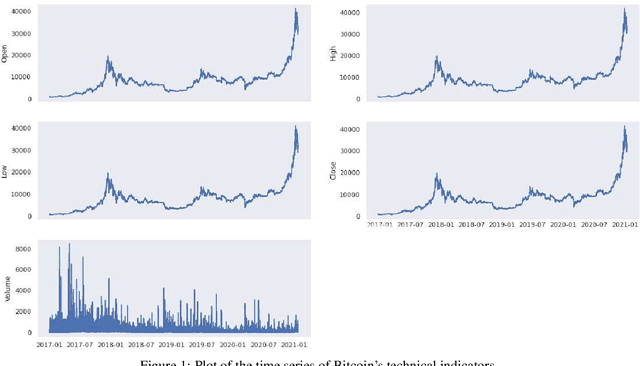
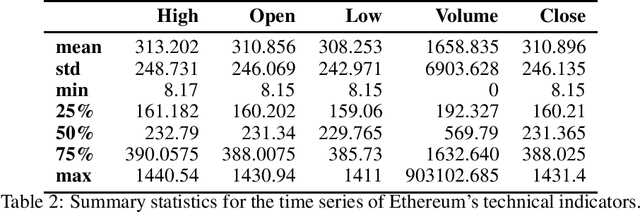
This work aims to analyse the predictability of price movements of cryptocurrencies on both hourly and daily data observed from January 2017 to January 2021, using deep learning algorithms. For our experiments, we used three sets of features: technical, trading and social media indicators, considering a restricted model of only technical indicators and an unrestricted model with technical, trading and social media indicators. We verified whether the consideration of trading and social media indicators, along with the classic technical variables (such as price's returns), leads to a significative improvement in the prediction of cryptocurrencies price's changes. We conducted the study on the two highest cryptocurrencies in volume and value (at the time of the study): Bitcoin and Ethereum. We implemented four different machine learning algorithms typically used in time-series classification problems: Multi Layers Perceptron (MLP), Convolutional Neural Network (CNN), Long Short Term Memory (LSTM) neural network and Attention Long Short Term Memory (ALSTM). We devised the experiments using the advanced bootstrap technique to consider the variance problem on test samples, which allowed us to evaluate a more reliable estimate of the model's performance. Furthermore, the Grid Search technique was used to find the best hyperparameters values for each implemented algorithm. The study shows that, based on the hourly frequency results, the unrestricted model outperforms the restricted one. The addition of the trading indicators to the classic technical indicators improves the accuracy of Bitcoin and Ethereum price's changes prediction, with an increase of accuracy from a range of 51-55% for the restricted model, to 67-84% for the unrestricted model.