 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark^2: Systematic Evaluation of LLM Benchmarks
Jan 07, 2026The rapid proliferation of benchmarks for evaluating large language models (LLMs) has created an urgent need for systematic methods to assess benchmark quality itself. We propose Benchmark^2, a comprehensive framework comprising three complementary metrics: (1) Cross-Benchmark Ranking Consistency, measuring whether a benchmark produces model rankings aligned with peer benchmarks; (2) Discriminability Score, quantifying a benchmark's ability to differentiate between models; and (3) Capability Alignment Deviation, identifying problematic instances where stronger models fail but weaker models succeed within the same model family. We conduct extensive experiments across 15 benchmarks spanning mathematics, reasoning, and knowledge domains, evaluating 11 LLMs across four model families. Our analysis reveals significant quality variations among existing benchmarks and demonstrates that selective benchmark construction based on our metrics can achieve comparable evaluation performance with substantially reduced test sets.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
Explainable Synthetic Image Detection through Diffusion Timestep Ensembling
Mar 08, 2025Recent advances in diffusion models have enabled the creation of deceptively real images, posing significant security risks when misused. In this study, we reveal that natural and synthetic images exhibit distinct differences in the high-frequency domains of their Fourier power spectra after undergoing iterative noise perturbations through an inverse multi-step denoising process, suggesting that such noise can provide additional discriminative information for identifying synthetic images. Based on this observation, we propose a novel detection method that amplifies these differences by progressively adding noise to the original images across multiple timesteps, and train an ensemble of classifiers on these noised images. To enhance human comprehension, we introduce an explanation generation and refinement module to identify flaws located in AI-generated images. Additionally, we construct two new datasets, GenHard and GenExplain, derived from the GenImage benchmark, providing detection samples of greater difficulty and high-quality rationales for fake images. Extensive experiments show that our method achieves state-of-the-art performance with 98.91% and 95.89% detection accuracy on regular and harder samples, increasing a minimal of 2.51% and 3.46% compared to baselines. Furthermore, our method also generalizes effectively to images generated by other diffusion models. Our code and datasets will be made publicly available.
Layer-Specific Scaling of Positional Encodings for Superior Long-Context Modeling
Mar 06, 2025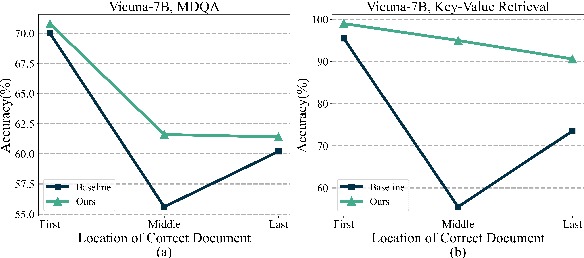



Although large language models (LLMs) have achieved significant progress in handling long-context inputs, they still suffer from the ``lost-in-the-middle'' problem, where crucial information in the middle of the context is often underrepresented or lost. Our extensive experiments reveal that this issue may arise from the rapid long-term decay in Rotary Position Embedding (RoPE). To address this problem, we propose a layer-specific positional encoding scaling method that assigns distinct scaling factors to each layer, slowing down the decay rate caused by RoPE to make the model pay more attention to the middle context. A specially designed genetic algorithm is employed to efficiently select the optimal scaling factors for each layer by incorporating Bezier curves to reduce the search space. Through comprehensive experimentation, we demonstrate that our method significantly alleviates the ``lost-in-the-middle'' problem. Our approach results in an average accuracy improvement of up to 20% on the Key-Value Retrieval dataset. Furthermore, we show that layer-specific interpolation, as opposed to uniform interpolation across all layers, enhances the model's extrapolation capabilities when combined with PI and Dynamic-NTK positional encoding schemes.
Dendritic Localized Learning: Toward Biologically Plausible Algorithm
Jan 17, 2025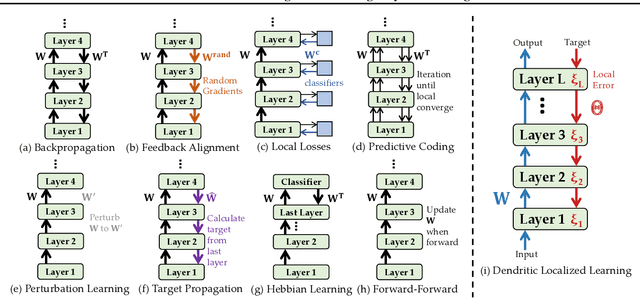
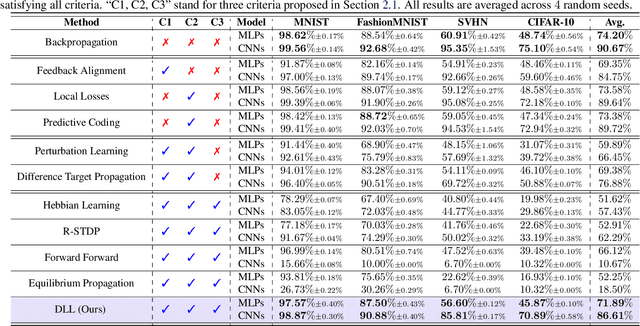
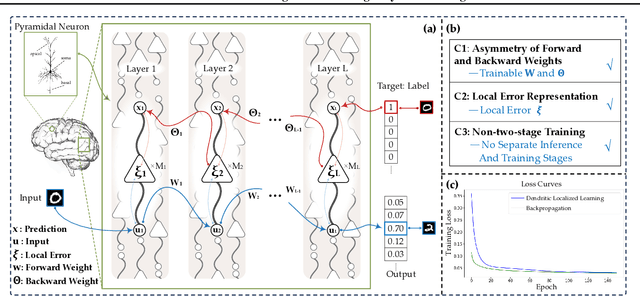

Backpropagation is the foundational algorithm for training neural networks and a key driver of deep learning's success. However, its biological plausibility has been challenged due to three primary limitations: weight symmetry, reliance on global error signals, and the dual-phase nature of training, as highlighted by the existing literature. Although various alternative learning approaches have been proposed to address these issues, most either fail to satisfy all three criteria simultaneously or yield suboptimal results. Inspired by the dynamics and plasticity of pyramidal neurons, we propose Dendritic Localized Learning (DLL), a novel learning algorithm designed to overcome these challenges. Extensive empirical experiments demonstrate that DLL satisfies all three criteria of biological plausibility while achieving state-of-the-art performance among algorithms that meet these requirements. Furthermore, DLL exhibits strong generalization across a range of architectures, including MLPs, CNNs, and RNNs. These results, benchmarked against existing biologically plausible learning algorithms, offer valuable empirical insights for future research. We hope this study can inspire the development of new biologically plausible algorithms for training multilayer networks and advancing progress in both neuroscience and machine learning.
LDA-MIG Detectors for Maritime Targets in Nonhomogeneous Sea Clutter
Sep 26, 2024This paper deals with the problem of detecting maritime targets embedded in nonhomogeneous sea clutter, where limited number of secondary data is available due to the heterogeneity of sea clutter. A class of linear discriminant analysis (LDA)-based matrix information geometry (MIG) detectors is proposed in the supervised scenario. As customary, Hermitian positive-definite (HPD) matrices are used to model the observational sample data, and the clutter covariance matrix of received dataset is estimated as geometric mean of the secondary HPD matrices. Given a set of training HPD matrices with class labels, that are elements of a higher-dimensional HPD matrix manifold, the LDA manifold projection learns a mapping from the higher-dimensional HPD matrix manifold to a lower-dimensional one subject to maximum discrimination. In the current study, the LDA manifold projection, with the cost function maximizing between-class distance while minimizing within-class distance, is formulated as an optimization problem in the Stiefel manifold. Four robust LDA-MIG detectors corresponding to different geometric measures are proposed. Numerical results based on both simulated radar clutter with interferences and real IPIX radar data show the advantage of the proposed LDA-MIG detectors against their counterparts without using LDA as well as the state-of-art maritime target detection methods in nonhomogeneous sea clutter.
* 15 pages, 9 figures
Searching for Best Practices in Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.