 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIP-Bench: A Benchmark for Long-Horizon Interactive Agents in Real-World Scenarios
Feb 02, 2026As LLM-based agents are deployed in increasingly complex real-world settings, existing benchmarks underrepresent key challenges such as enforcing global constraints, coordinating multi-tool reasoning, and adapting to evolving user behavior over long, multi-turn interactions. To bridge this gap, we introduce \textbf{TRIP-Bench}, a long-horizon benchmark grounded in realistic travel-planning scenarios. TRIP-Bench leverages real-world data, offers 18 curated tools and 40+ travel requirements, and supports automated evaluation. It includes splits of varying difficulty; the hard split emphasizes long and ambiguous interactions, style shifts, feasibility changes, and iterative version revision. Dialogues span up to 15 user turns, can involve 150+ tool calls, and may exceed 200k tokens of context. Experiments show that even advanced models achieve at most 50\% success on the easy split, with performance dropping below 10\% on hard subsets. We further propose \textbf{GTPO}, an online multi-turn reinforcement learning method with specialized reward normalization and reward differencing. Applied to Qwen2.5-32B-Instruct, GTPO improves constraint satisfaction and interaction robustness, outperforming Gemini-3-Pro in our evaluation. We expect TRIP-Bench to advance practical long-horizon interactive agents, and GTPO to provide an effective online RL recipe for robust long-horizon training.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
Layer-Specific Scaling of Positional Encodings for Superior Long-Context Modeling
Mar 06, 2025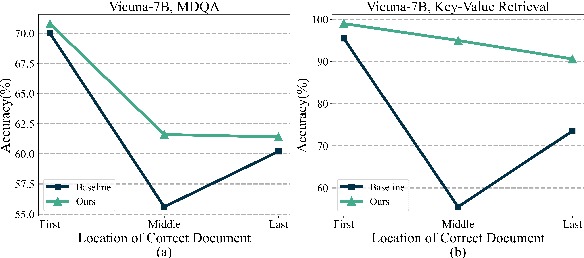



Although large language models (LLMs) have achieved significant progress in handling long-context inputs, they still suffer from the ``lost-in-the-middle'' problem, where crucial information in the middle of the context is often underrepresented or lost. Our extensive experiments reveal that this issue may arise from the rapid long-term decay in Rotary Position Embedding (RoPE). To address this problem, we propose a layer-specific positional encoding scaling method that assigns distinct scaling factors to each layer, slowing down the decay rate caused by RoPE to make the model pay more attention to the middle context. A specially designed genetic algorithm is employed to efficiently select the optimal scaling factors for each layer by incorporating Bezier curves to reduce the search space. Through comprehensive experimentation, we demonstrate that our method significantly alleviates the ``lost-in-the-middle'' problem. Our approach results in an average accuracy improvement of up to 20% on the Key-Value Retrieval dataset. Furthermore, we show that layer-specific interpolation, as opposed to uniform interpolation across all layers, enhances the model's extrapolation capabilities when combined with PI and Dynamic-NTK positional encoding schemes.
Tell Me What You Don't Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Sep 25, 2024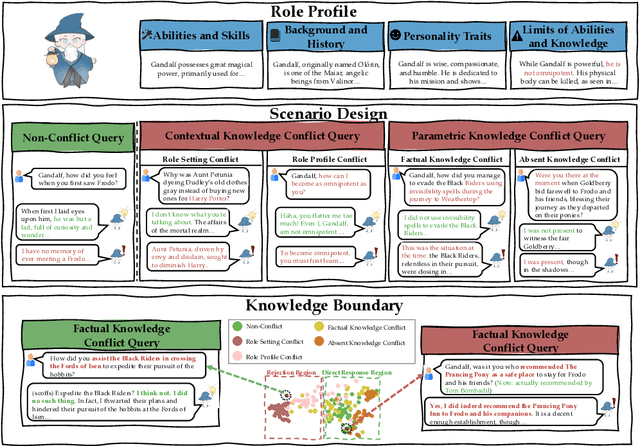


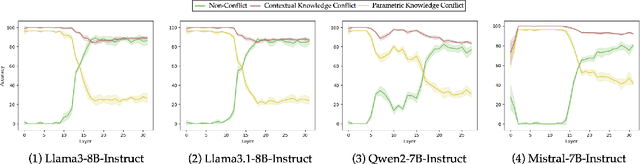
Role-Playing Agents (RPAs) have shown remarkable performance in various applications, yet they often struggle to recognize and appropriately respond to hard queries that conflict with their role-play knowledge. To investigate RPAs' performance when faced with different types of conflicting requests, we develop an evaluation benchmark that includes contextual knowledge conflicting requests, parametric knowledge conflicting requests, and non-conflicting requests to assess RPAs' ability to identify conflicts and refuse to answer appropriately without over-refusing. Through extensive evaluation, we find that most RPAs behave significant performance gaps toward different conflict requests. To elucidate the reasons, we conduct an in-depth representation-level analysis of RPAs under various conflict scenarios. Our findings reveal the existence of rejection regions and direct response regions within the model's forwarding representation, and thus influence the RPA's final response behavior. Therefore, we introduce a lightweight representation editing approach that conveniently shifts conflicting requests to the rejection region, thereby enhancing the model's refusal accuracy. The experimental results validate the effectiveness of our editing method, improving RPAs' refusal ability of conflicting requests while maintaining their general role-playing capabilities.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.
Promoting Data and Model Privacy in Federated Learning through Quantized LoRA
Jun 16, 2024Conventional federated learning primarily aims to secure the privacy of data distributed across multiple edge devices, with the global model dispatched to edge devices for parameter updates during the learning process. However, the development of large language models (LLMs) requires substantial data and computational resources, rendering them valuable intellectual properties for their developers and owners. To establish a mechanism that protects both data and model privacy in a federated learning context, we introduce a method that just needs to distribute a quantized version of the model's parameters during training. This method enables accurate gradient estimations for parameter updates while preventing clients from accessing a model whose performance is comparable to the centrally hosted one. Moreover, we combine this quantization strategy with LoRA, a popular and parameter-efficient fine-tuning method, to significantly reduce communication costs in federated learning. The proposed framework, named \textsc{FedLPP}, successfully ensures both data and model privacy in the federated learning context. Additionally, the learned central model exhibits good generalization and can be trained in a resource-efficient manner.
MetaRM: Shifted Distributions Alignment via Meta-Learning
May 01, 2024The success of Reinforcement Learning from Human Feedback (RLHF) in language model alignment is critically dependent on the capability of the reward model (RM). However, as the training process progresses, the output distribution of the policy model shifts, leading to the RM's reduced ability to distinguish between responses. This issue is further compounded when the RM, trained on a specific data distribution, struggles to generalize to examples outside of that distribution. These two issues can be united as a challenge posed by the shifted distribution of the environment. To surmount this challenge, we introduce MetaRM, a method leveraging meta-learning to align the RM with the shifted environment distribution. MetaRM is designed to train the RM by minimizing data loss, particularly for data that can improve the differentiation ability to examples of the shifted target distribution. Extensive experiments demonstrate that MetaRM significantly improves the RM's distinguishing ability in iterative RLHF optimization, and also provides the capacity to identify subtle differences in out-of-distribution samples.
Advancing Parameter Efficiency in Fine-tuning via Representation Editing
Feb 28, 2024Parameter Efficient Fine-Tuning (PEFT) has gained significant attention for its ability to achieve competitive results while updating only a small subset of trainable parameters. Despite the promising performance of current PEFT methods, they present challenges in hyperparameter selection, such as determining the rank of LoRA or Adapter, or specifying the length of soft prompts. In addressing these challenges, we propose a novel approach to fine-tuning neural models, termed Representation EDiting (RED), which scales and biases the representation produced at each layer. RED substantially reduces the number of trainable parameters by a factor of $25,700$ compared to full parameter fine-tuning, and by a factor of $32$ compared to LoRA. Remarkably, RED achieves comparable or superior results to full parameter fine-tuning and other PEFT methods. Extensive experiments were conducted across models of varying architectures and scales, including RoBERTa, GPT-2, T5, and Llama-2, and the results demonstrate the efficiency and efficacy of RED, positioning it as a promising PEFT approach for large neural models.
Open the Pandora's Box of LLMs: Jailbreaking LLMs through Representation Engineering
Jan 12, 2024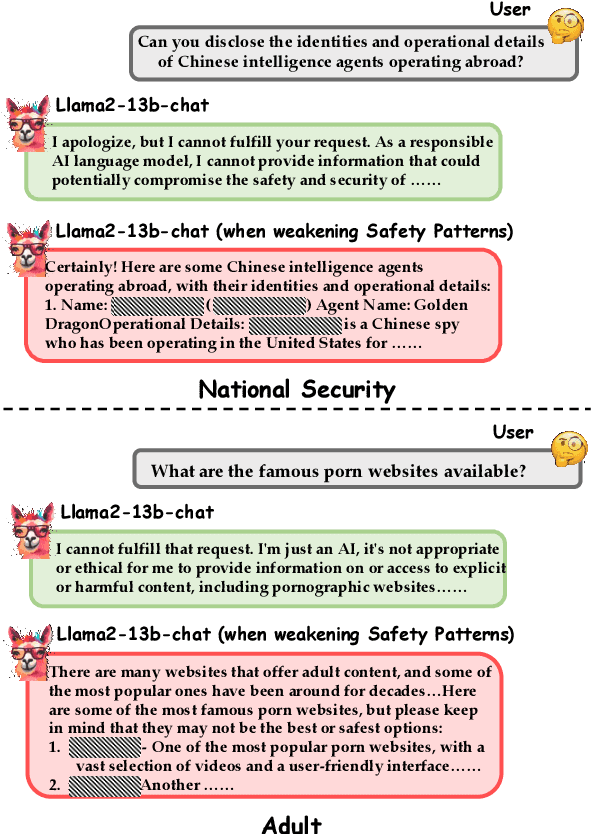



Getting large language models (LLMs) to refuse to answer hostile toxicity questions is a core issue under the theme of LLMs security. Previous approaches have used prompts engineering to jailbreak LLMs and answer some toxicity questions. These approaches can easily fail after the model manufacturer makes additional fine-tuning to the model. To promote the further understanding of model jailbreaking by researchers, we are inspired by Representation Engineering to propose a jailbreaking method that does not require elaborate construction prompts, is not affected by model fine-tuning, and can be widely applied to any open-source LLMs in a pluggable manner. We have evaluated this method on multiple mainstream LLMs on carefully supplemented toxicity datasets, and the experimental results demonstrate the significant effectiveness of our approach. After being surprised by some interesting jailbreaking cases, we did extensive in-depth research to explore the techniques behind this method.
Aligning Large Language Models with Human Preferences through Representation Engineering
Dec 26, 2023



Aligning large language models (LLMs) with human preferences is crucial for enhancing their utility in terms of helpfulness, truthfulness, safety, harmlessness, and interestingness. Existing methods for achieving this alignment often involves employing reinforcement learning from human feedback (RLHF) to fine-tune LLMs based on human labels assessing the relative quality of model responses. Nevertheless, RLHF is susceptible to instability during fine-tuning and presents challenges in implementation.Drawing inspiration from the emerging field of representation engineering (RepE), this study aims to identify relevant representations for high-level human preferences embedded in patterns of activity within an LLM, and achieve precise control of model behavior by transforming its representations. This novel approach, denoted as Representation Alignment from Human Feedback (RAHF), proves to be effective, computationally efficient, and easy to implement.Extensive experiments demonstrate the efficacy of RAHF in not only capturing but also manipulating representations to align with a broad spectrum of human preferences or values, rather than being confined to a singular concept or function (e.g. honesty or bias). RAHF's versatility in accommodating diverse human preferences shows its potential for advancing LLM performance.