 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark^2: Systematic Evaluation of LLM Benchmarks
Jan 07, 2026The rapid proliferation of benchmarks for evaluating large language models (LLMs) has created an urgent need for systematic methods to assess benchmark quality itself. We propose Benchmark^2, a comprehensive framework comprising three complementary metrics: (1) Cross-Benchmark Ranking Consistency, measuring whether a benchmark produces model rankings aligned with peer benchmarks; (2) Discriminability Score, quantifying a benchmark's ability to differentiate between models; and (3) Capability Alignment Deviation, identifying problematic instances where stronger models fail but weaker models succeed within the same model family. We conduct extensive experiments across 15 benchmarks spanning mathematics, reasoning, and knowledge domains, evaluating 11 LLMs across four model families. Our analysis reveals significant quality variations among existing benchmarks and demonstrates that selective benchmark construction based on our metrics can achieve comparable evaluation performance with substantially reduced test sets.
Enhancing Model Privacy in Federated Learning with Random Masking and Quantization
Aug 27, 2025The primary goal of traditional federated learning is to protect data privacy by enabling distributed edge devices to collaboratively train a shared global model while keeping raw data decentralized at local clients. The rise of large language models (LLMs) has introduced new challenges in distributed systems, as their substantial computational requirements and the need for specialized expertise raise critical concerns about protecting intellectual property (IP). This highlights the need for a federated learning approach that can safeguard both sensitive data and proprietary models. To tackle this challenge, we propose FedQSN, a federated learning approach that leverages random masking to obscure a subnetwork of model parameters and applies quantization to the remaining parameters. Consequently, the server transmits only a privacy-preserving proxy of the global model to clients during each communication round, thus enhancing the model's confidentiality. Experimental results across various models and tasks demonstrate that our approach not only maintains strong model performance in federated learning settings but also achieves enhanced protection of model parameters compared to baseline methods.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
RECAST: Strengthening LLMs' Complex Instruction Following with Constraint-Verifiable Data
May 25, 2025Large language models (LLMs) are increasingly expected to tackle complex tasks, driven by their expanding applications and users' growing proficiency in crafting sophisticated prompts. However, as the number of explicitly stated requirements increases (particularly more than 10 constraints), LLMs often struggle to accurately follow such complex instructions. To address this challenge, we propose RECAST, a novel framework for synthesizing datasets where each example incorporates far more constraints than those in existing benchmarks. These constraints are extracted from real-world prompt-response pairs to ensure practical relevance. RECAST enables automatic verification of constraint satisfaction via rule-based validators for quantitative constraints and LLM-based validators for qualitative ones. Using this framework, we construct RECAST-30K, a large-scale, high-quality dataset comprising 30k instances spanning 15 constraint types. Experimental results demonstrate that models fine-tuned on RECAST-30K show substantial improvements in following complex instructions. Moreover, the verifiability provided by RECAST enables the design of reward functions for reinforcement learning, which further boosts model performance on complex and challenging tasks.
Improving RL Exploration for LLM Reasoning through Retrospective Replay
Apr 19, 2025Reinforcement learning (RL) has increasingly become a pivotal technique in the post-training of large language models (LLMs). The effective exploration of the output space is essential for the success of RL. We observe that for complex problems, during the early stages of training, the model exhibits strong exploratory capabilities and can identify promising solution ideas. However, its limited capability at this stage prevents it from successfully solving these problems. The early suppression of these potentially valuable solution ideas by the policy gradient hinders the model's ability to revisit and re-explore these ideas later. Consequently, although the LLM's capabilities improve in the later stages of training, it still struggles to effectively address these complex problems. To address this exploration issue, we propose a novel algorithm named Retrospective Replay-based Reinforcement Learning (RRL), which introduces a dynamic replay mechanism throughout the training process. RRL enables the model to revisit promising states identified in the early stages, thereby improving its efficiency and effectiveness in exploration. To evaluate the effectiveness of RRL, we conduct extensive experiments on complex reasoning tasks, including mathematical reasoning and code generation, and general dialogue tasks. The results indicate that RRL maintains high exploration efficiency throughout the training period, significantly enhancing the effectiveness of RL in optimizing LLMs for complicated reasoning tasks. Moreover, it also improves the performance of RLHF, making the model both safer and more helpful.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
Tell Me What You Don't Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Sep 25, 2024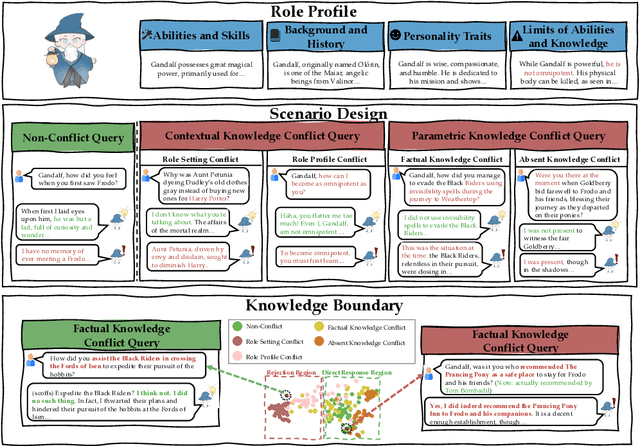


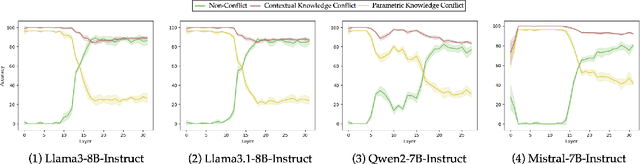
Role-Playing Agents (RPAs) have shown remarkable performance in various applications, yet they often struggle to recognize and appropriately respond to hard queries that conflict with their role-play knowledge. To investigate RPAs' performance when faced with different types of conflicting requests, we develop an evaluation benchmark that includes contextual knowledge conflicting requests, parametric knowledge conflicting requests, and non-conflicting requests to assess RPAs' ability to identify conflicts and refuse to answer appropriately without over-refusing. Through extensive evaluation, we find that most RPAs behave significant performance gaps toward different conflict requests. To elucidate the reasons, we conduct an in-depth representation-level analysis of RPAs under various conflict scenarios. Our findings reveal the existence of rejection regions and direct response regions within the model's forwarding representation, and thus influence the RPA's final response behavior. Therefore, we introduce a lightweight representation editing approach that conveniently shifts conflicting requests to the rejection region, thereby enhancing the model's refusal accuracy. The experimental results validate the effectiveness of our editing method, improving RPAs' refusal ability of conflicting requests while maintaining their general role-playing capabilities.
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Jul 08, 2024
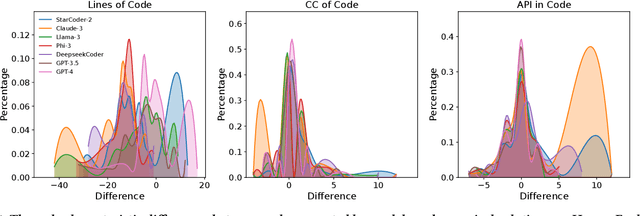


The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.
Promoting Data and Model Privacy in Federated Learning through Quantized LoRA
Jun 16, 2024Conventional federated learning primarily aims to secure the privacy of data distributed across multiple edge devices, with the global model dispatched to edge devices for parameter updates during the learning process. However, the development of large language models (LLMs) requires substantial data and computational resources, rendering them valuable intellectual properties for their developers and owners. To establish a mechanism that protects both data and model privacy in a federated learning context, we introduce a method that just needs to distribute a quantized version of the model's parameters during training. This method enables accurate gradient estimations for parameter updates while preventing clients from accessing a model whose performance is comparable to the centrally hosted one. Moreover, we combine this quantization strategy with LoRA, a popular and parameter-efficient fine-tuning method, to significantly reduce communication costs in federated learning. The proposed framework, named \textsc{FedLPP}, successfully ensures both data and model privacy in the federated learning context. Additionally, the learned central model exhibits good generalization and can be trained in a resource-efficient manner.