 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArithmetic-Mean $μ$P for Modern Architectures: A Unified Learning-Rate Scale for CNNs and ResNets
Oct 05, 2025Choosing an appropriate learning rate remains a key challenge in scaling depth of modern deep networks. The classical maximal update parameterization ($\mu$P) enforces a fixed per-layer update magnitude, which is well suited to homogeneous multilayer perceptrons (MLPs) but becomes ill-posed in heterogeneous architectures where residual accumulation and convolutions introduce imbalance across layers. We introduce Arithmetic-Mean $\mu$P (AM-$\mu$P), which constrains not each individual layer but the network-wide average one-step pre-activation second moment to a constant scale. Combined with a residual-aware He fan-in initialization - scaling residual-branch weights by the number of blocks ($\mathrm{Var}[W]=c/(K\cdot \mathrm{fan\text{-}in})$) - AM-$\mu$P yields width-robust depth laws that transfer consistently across depths. We prove that, for one- and two-dimensional convolutional networks, the maximal-update learning rate satisfies $\eta^\star(L)\propto L^{-3/2}$; with zero padding, boundary effects are constant-level as $N\gg k$. For standard residual networks with general conv+MLP blocks, we establish $\eta^\star(L)=\Theta(L^{-3/2})$, with $L$ the minimal depth. Empirical results across a range of depths confirm the $-3/2$ scaling law and enable zero-shot learning-rate transfer, providing a unified and practical LR principle for convolutional and deep residual networks without additional tuning overhead.
MM-IFEngine: Towards Multimodal Instruction Following
Apr 10, 2025The Instruction Following (IF) ability measures how well Multi-modal Large Language Models (MLLMs) understand exactly what users are telling them and whether they are doing it right. Existing multimodal instruction following training data is scarce, the benchmarks are simple with atomic instructions, and the evaluation strategies are imprecise for tasks demanding exact output constraints. To address this, we present MM-IFEngine, an effective pipeline to generate high-quality image-instruction pairs. Our MM-IFEngine pipeline yields large-scale, diverse, and high-quality training data MM-IFInstruct-23k, which is suitable for Supervised Fine-Tuning (SFT) and extended as MM-IFDPO-23k for Direct Preference Optimization (DPO). We further introduce MM-IFEval, a challenging and diverse multi-modal instruction-following benchmark that includes (1) both compose-level constraints for output responses and perception-level constraints tied to the input images, and (2) a comprehensive evaluation pipeline incorporating both rule-based assessment and judge model. We conduct SFT and DPO experiments and demonstrate that fine-tuning MLLMs on MM-IFInstruct-23k and MM-IFDPO-23k achieves notable gains on various IF benchmarks, such as MM-IFEval (+10.2$\%$), MIA (+7.6$\%$), and IFEval (+12.3$\%$). The full data and evaluation code will be released on https://github.com/SYuan03/MM-IFEngine.
InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model
Jan 21, 2025


Despite the promising performance of Large Vision Language Models (LVLMs) in visual understanding, they occasionally generate incorrect outputs. While reward models (RMs) with reinforcement learning or test-time scaling offer the potential for improving generation quality, a critical gap remains: publicly available multi-modal RMs for LVLMs are scarce, and the implementation details of proprietary models are often unclear. We bridge this gap with InternLM-XComposer2.5-Reward (IXC-2.5-Reward), a simple yet effective multi-modal reward model that aligns LVLMs with human preferences. To ensure the robustness and versatility of IXC-2.5-Reward, we set up a high-quality multi-modal preference corpus spanning text, image, and video inputs across diverse domains, such as instruction following, general understanding, text-rich documents, mathematical reasoning, and video understanding. IXC-2.5-Reward achieves excellent results on the latest multi-modal reward model benchmark and shows competitive performance on text-only reward model benchmarks. We further demonstrate three key applications of IXC-2.5-Reward: (1) Providing a supervisory signal for RL training. We integrate IXC-2.5-Reward with Proximal Policy Optimization (PPO) yields IXC-2.5-Chat, which shows consistent improvements in instruction following and multi-modal open-ended dialogue; (2) Selecting the best response from candidate responses for test-time scaling; and (3) Filtering outlier or noisy samples from existing image and video instruction tuning training data. To ensure reproducibility and facilitate further research, we have open-sourced all model weights and training recipes at https://github.com/InternLM/InternLM-XComposer
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Jul 08, 2024
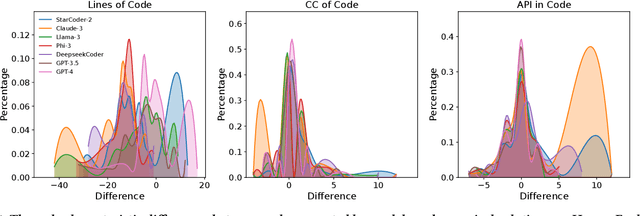


The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.