 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentalSeek-Dx: Towards Progressive Hypothetico-Deductive Reasoning for Real-world Psychiatric Diagnosis
Feb 03, 2026Mental health disorders represent a burgeoning global public health challenge. While Large Language Models (LLMs) have demonstrated potential in psychiatric assessment, their clinical utility is severely constrained by benchmarks that lack ecological validity and fine-grained diagnostic supervision. To bridge this gap, we introduce \textbf{MentalDx Bench}, the first benchmark dedicated to disorder-level psychiatric diagnosis within real-world clinical settings. Comprising 712 de-identified electronic health records annotated by board-certified psychiatrists under ICD-11 guidelines, the benchmark covers 76 disorders across 16 diagnostic categories. Evaluation of 18 LLMs reveals a critical \textit{paradigm misalignment}: strong performance at coarse diagnostic categorization contrasts with systematic failure at disorder-level diagnosis, underscoring a gap between pattern-based modeling and clinical hypothetico-deductive reasoning. In response, we propose \textbf{MentalSeek-Dx}, a medical-specialized LLM trained to internalize this clinical reasoning process through supervised trajectory construction and curriculum-based reinforcement learning. Experiments on MentalDx Bench demonstrate that MentalSeek-Dx achieves state-of-the-art (SOTA) performance with only 14B parameters, establishing a clinically grounded framework for reliable psychiatric diagnosis.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
Effective Length Extrapolation via Dimension-Wise Positional Embeddings Manipulation
Apr 26, 2025Large Language Models (LLMs) often struggle to process and generate coherent context when the number of input tokens exceeds the pre-trained length. Recent advancements in long-context extension have significantly expanded the context window of LLMs but require expensive overhead to train the large-scale models with longer context. In this work, we propose Dimension-Wise Positional Embeddings Manipulation (DPE), a training-free framework to extrapolate the context window of LLMs by diving into RoPE's different hidden dimensions. Instead of manipulating all dimensions equally, DPE detects the effective length for every dimension and finds the key dimensions for context extension. We reuse the original position indices with their embeddings from the pre-trained model and manipulate the key dimensions' position indices to their most effective lengths. In this way, DPE adjusts the pre-trained models with minimal modifications while ensuring that each dimension reaches its optimal state for extrapolation. DPE significantly surpasses well-known baselines such as YaRN and Self-Extend. DPE enables Llama3-8k 8B to support context windows of 128k tokens without continual training and integrates seamlessly with Flash Attention 2. In addition to its impressive extrapolation capability, DPE also dramatically improves the models' performance within training length, such as Llama3.1 70B, by over 18 points on popular long-context benchmarks RULER. When compared with commercial models, Llama 3.1 70B with DPE even achieves better performance than GPT-4-128K.
Machine-assisted writing evaluation: Exploring pre-trained language models in analyzing argumentative moves
Mar 25, 2025The study investigates the efficacy of pre-trained language models (PLMs) in analyzing argumentative moves in a longitudinal learner corpus. Prior studies on argumentative moves often rely on qualitative analysis and manual coding, limiting their efficiency and generalizability. The study aims to: 1) to assess the reliability of PLMs in analyzing argumentative moves; 2) to utilize PLM-generated annotations to illustrate developmental patterns and predict writing quality. A longitudinal corpus of 1643 argumentative texts from 235 English learners in China is collected and annotated into six move types: claim, data, counter-claim, counter-data, rebuttal, and non-argument. The corpus is divided into training, validation, and application sets annotated by human experts and PLMs. We use BERT as one of the implementations of PLMs. The results indicate a robust reliability of PLMs in analyzing argumentative moves, with an overall F1 score of 0.743, surpassing existing models in the field. Additionally, PLM-labeled argumentative moves effectively capture developmental patterns and predict writing quality. Over time, students exhibit an increase in the use of data and counter-claims and a decrease in non-argument moves. While low-quality texts are characterized by a predominant use of claims and data supporting only oneside position, mid- and high-quality texts demonstrate an integrative perspective with a higher ratio of counter-claims, counter-data, and rebuttals. This study underscores the transformative potential of integrating artificial intelligence into language education, enhancing the efficiency and accuracy of evaluating students' writing. The successful application of PLMs can catalyze the development of educational technology, promoting a more data-driven and personalized learning environment that supports diverse educational needs.
Mitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
Mar 19, 2025Recently, multimodal large language models (MLLMs) have demonstrated remarkable performance in visual-language tasks. However, the authenticity of the responses generated by MLLMs is often compromised by object hallucinations. We identify that a key cause of these hallucinations is the model's over-susceptibility to specific image frequency features in detecting objects. In this paper, we introduce Multi-Frequency Perturbations (MFP), a simple, cost-effective, and pluggable method that leverages both low-frequency and high-frequency features of images to perturb visual feature representations and explicitly suppress redundant frequency-domain features during inference, thereby mitigating hallucinations. Experimental results demonstrate that our method significantly mitigates object hallucinations across various model architectures. Furthermore, as a training-time method, MFP can be combined with inference-time methods to achieve state-of-the-art performance on the CHAIR benchmark.
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Feb 25, 2025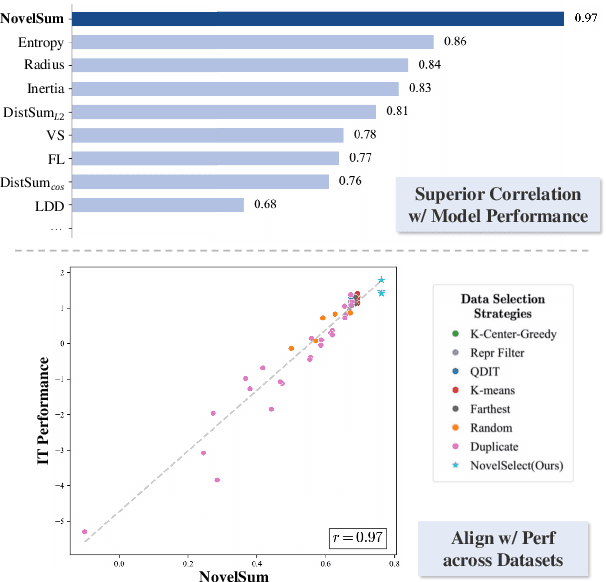
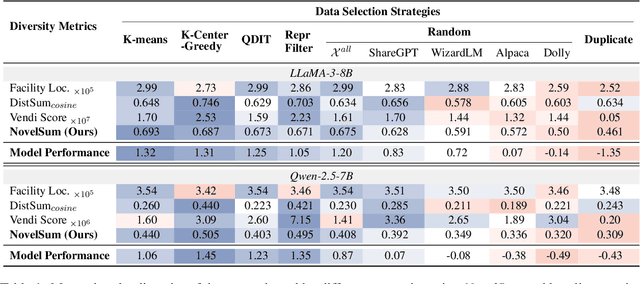
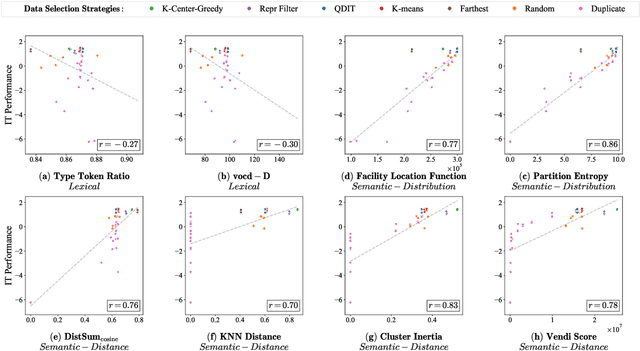
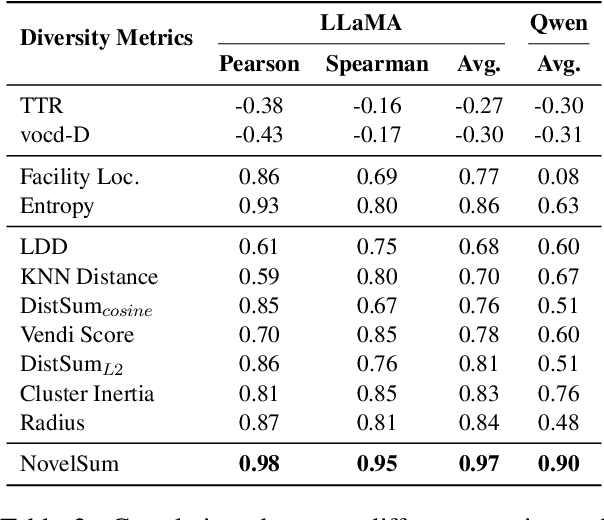
Data diversity is crucial for the instruction tuning of large language models. Existing studies have explored various diversity-aware data selection methods to construct high-quality datasets and enhance model performance. However, the fundamental problem of precisely defining and measuring data diversity remains underexplored, limiting clear guidance for data engineering. To address this, we systematically analyze 11 existing diversity measurement methods by evaluating their correlation with model performance through extensive fine-tuning experiments. Our results indicate that a reliable diversity measure should properly account for both inter-sample differences and the information distribution in the sample space. Building on this, we propose NovelSum, a new diversity metric based on sample-level "novelty." Experiments on both simulated and real-world data show that NovelSum accurately captures diversity variations and achieves a 0.97 correlation with instruction-tuned model performance, highlighting its value in guiding data engineering practices. With NovelSum as an optimization objective, we further develop a greedy, diversity-oriented data selection strategy that outperforms existing approaches, validating both the effectiveness and practical significance of our metric.
Benchmarking Multimodal RAG through a Chart-based Document Question-Answering Generation Framework
Feb 20, 2025Multimodal Retrieval-Augmented Generation (MRAG) enhances reasoning capabilities by integrating external knowledge. However, existing benchmarks primarily focus on simple image-text interactions, overlooking complex visual formats like charts that are prevalent in real-world applications. In this work, we introduce a novel task, Chart-based MRAG, to address this limitation. To semi-automatically generate high-quality evaluation samples, we propose CHARt-based document question-answering GEneration (CHARGE), a framework that produces evaluation data through structured keypoint extraction, crossmodal verification, and keypoint-based generation. By combining CHARGE with expert validation, we construct Chart-MRAG Bench, a comprehensive benchmark for chart-based MRAG evaluation, featuring 4,738 question-answering pairs across 8 domains from real-world documents. Our evaluation reveals three critical limitations in current approaches: (1) unified multimodal embedding retrieval methods struggles in chart-based scenarios, (2) even with ground-truth retrieval, state-of-the-art MLLMs achieve only 58.19% Correctness and 73.87% Coverage scores, and (3) MLLMs demonstrate consistent text-over-visual modality bias during Chart-based MRAG reasoning. The CHARGE and Chart-MRAG Bench are released at https://github.com/Nomothings/CHARGE.git.
Latent Distribution Decoupling: A Probabilistic Framework for Uncertainty-Aware Multimodal Emotion Recognition
Feb 19, 2025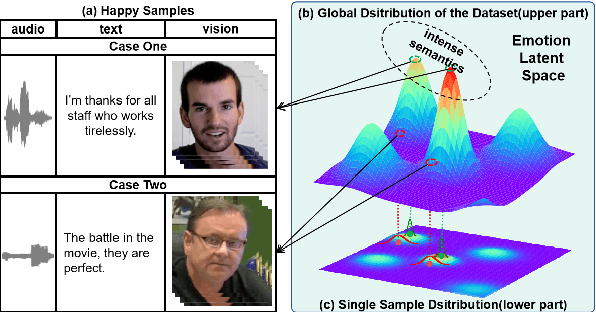
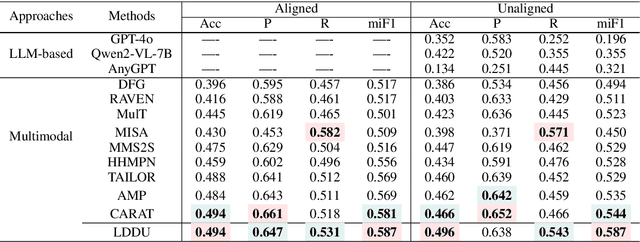
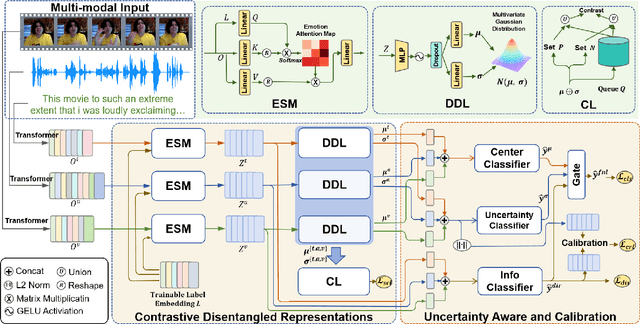
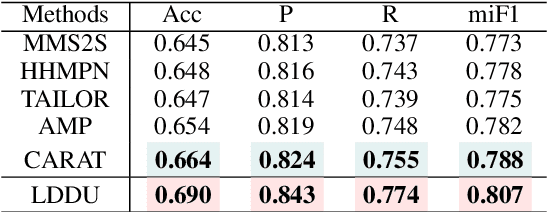
Multimodal multi-label emotion recognition (MMER) aims to identify the concurrent presence of multiple emotions in multimodal data. Existing studies primarily focus on improving fusion strategies and modeling modality-to-label dependencies. However, they often overlook the impact of \textbf{aleatoric uncertainty}, which is the inherent noise in the multimodal data and hinders the effectiveness of modality fusion by introducing ambiguity into feature representations. To address this issue and effectively model aleatoric uncertainty, this paper proposes Latent emotional Distribution Decomposition with Uncertainty perception (LDDU) framework from a novel perspective of latent emotional space probabilistic modeling. Specifically, we introduce a contrastive disentangled distribution mechanism within the emotion space to model the multimodal data, allowing for the extraction of semantic features and uncertainty. Furthermore, we design an uncertainty-aware fusion multimodal method that accounts for the dispersed distribution of uncertainty and integrates distribution information. Experimental results show that LDDU achieves state-of-the-art performance on the CMU-MOSEI and M$^3$ED datasets, highlighting the importance of uncertainty modeling in MMER. Code is available at https://github.com/201983290498/lddu\_mmer.git.
TL-Training: A Task-Feature-Based Framework for Training Large Language Models in Tool Use
Dec 20, 2024



Large language models (LLMs) achieve remarkable advancements by leveraging tools to interact with external environments, a critical step toward generalized AI. However, the standard supervised fine-tuning (SFT) approach, which relies on large-scale datasets, often overlooks task-specific characteristics in tool use, leading to performance bottlenecks. To address this issue, we analyze three existing LLMs and uncover key insights: training data can inadvertently impede tool-use behavior, token importance is distributed unevenly, and errors in tool calls fall into a small set of distinct categories. Building on these findings, we propose TL-Training, a task-feature-based framework that mitigates the effects of suboptimal training data, dynamically adjusts token weights to prioritize key tokens during SFT, and incorporates a robust reward mechanism tailored to error categories, optimized through proximal policy optimization. We validate TL-Training by training CodeLLaMA-2-7B and evaluating it on four diverse open-source test sets. Our results demonstrate that the LLM trained by our method matches or surpasses both open- and closed-source LLMs in tool-use performance using only 1,217 training data points. Additionally, our method enhances robustness in noisy environments and improves general task performance, offering a scalable and efficient paradigm for tool-use training in LLMs. The code and data are available at https://github.com/Junjie-Ye/TL-Training.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.