 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
Can Deep Research Agents Find and Organize? Evaluating the Synthesis Gap with Expert Taxonomies
Jan 18, 2026Deep Research Agents are increasingly used for automated survey generation. However, whether they can write surveys like human experts remains unclear. Existing benchmarks focus on fluency or citation accuracy, but none evaluates the core capabilities: retrieving essential papers and organizing them into coherent knowledge structures. We introduce TaxoBench, a diagnostic benchmark derived from 72 highly-cited computer science surveys. We manually extract expert-authored taxonomy trees containing 3,815 precisely categorized citations as ground truth. Our benchmark supports two evaluation modes: Deep Research mode tests end-to-end retrieval and organization given only a topic, while Bottom-Up mode isolates structuring capability by providing the exact papers human experts used. We evaluate 7 leading Deep Research agents and 12 frontier LLMs. Results reveal a dual bottleneck: the best agent recalls only 20.9% of expert-selected papers, and even with perfect input, the best model achieves only 0.31 ARI in organization. Current deep research agents remain far from expert-level survey writing. Our benchmark is publicly available at https://github.com/KongLongGeFDU/TaxoBench.
OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
Jan 04, 2026Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation
Jun 04, 2025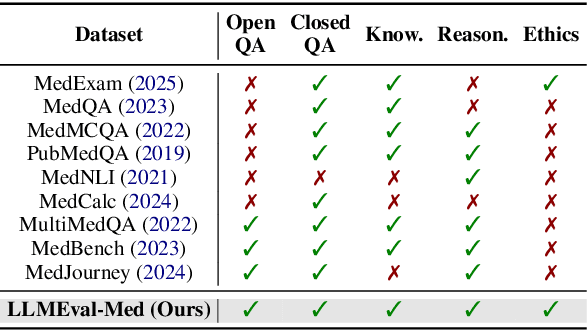
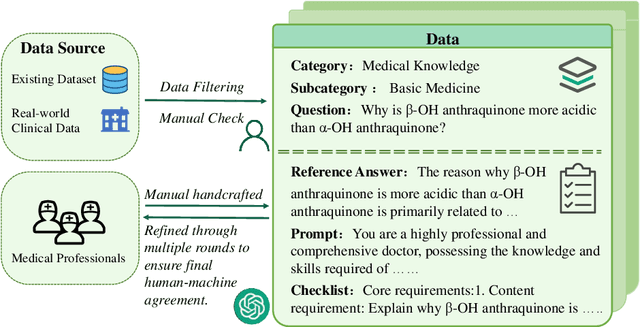
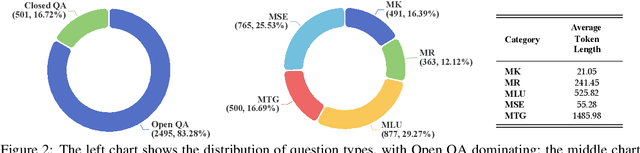
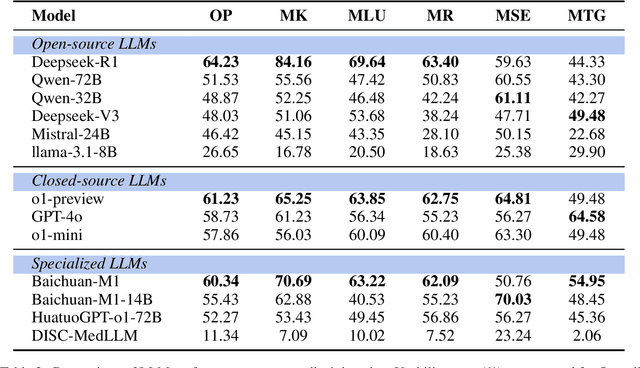
Evaluating large language models (LLMs) in medicine is crucial because medical applications require high accuracy with little room for error. Current medical benchmarks have three main types: medical exam-based, comprehensive medical, and specialized assessments. However, these benchmarks have limitations in question design (mostly multiple-choice), data sources (often not derived from real clinical scenarios), and evaluation methods (poor assessment of complex reasoning). To address these issues, we present LLMEval-Med, a new benchmark covering five core medical areas, including 2,996 questions created from real-world electronic health records and expert-designed clinical scenarios. We also design an automated evaluation pipeline, incorporating expert-developed checklists into our LLM-as-Judge framework. Furthermore, our methodology validates machine scoring through human-machine agreement analysis, dynamically refining checklists and prompts based on expert feedback to ensure reliability. We evaluate 13 LLMs across three categories (specialized medical models, open-source models, and closed-source models) on LLMEval-Med, providing valuable insights for the safe and effective deployment of LLMs in medical domains. The dataset is released in https://github.com/llmeval/LLMEval-Med.
Mitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
Mar 19, 2025Recently, multimodal large language models (MLLMs) have demonstrated remarkable performance in visual-language tasks. However, the authenticity of the responses generated by MLLMs is often compromised by object hallucinations. We identify that a key cause of these hallucinations is the model's over-susceptibility to specific image frequency features in detecting objects. In this paper, we introduce Multi-Frequency Perturbations (MFP), a simple, cost-effective, and pluggable method that leverages both low-frequency and high-frequency features of images to perturb visual feature representations and explicitly suppress redundant frequency-domain features during inference, thereby mitigating hallucinations. Experimental results demonstrate that our method significantly mitigates object hallucinations across various model architectures. Furthermore, as a training-time method, MFP can be combined with inference-time methods to achieve state-of-the-art performance on the CHAIR benchmark.
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Mar 09, 2025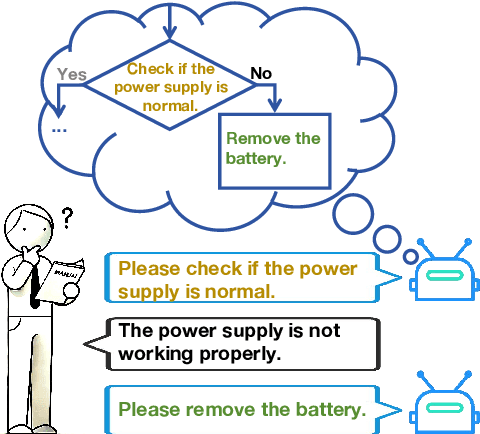
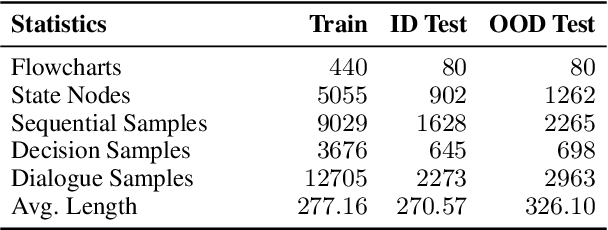
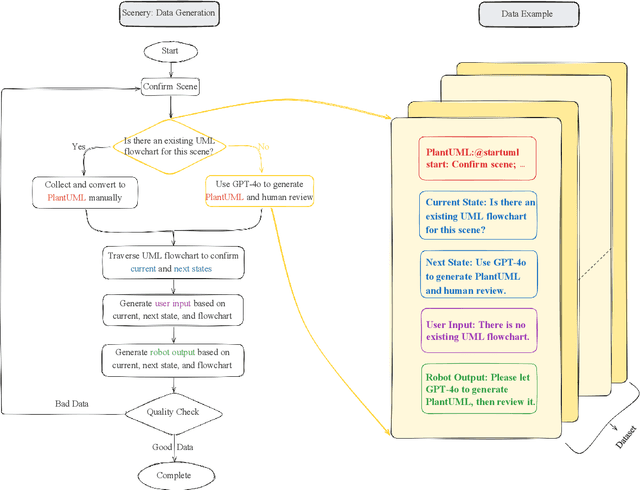
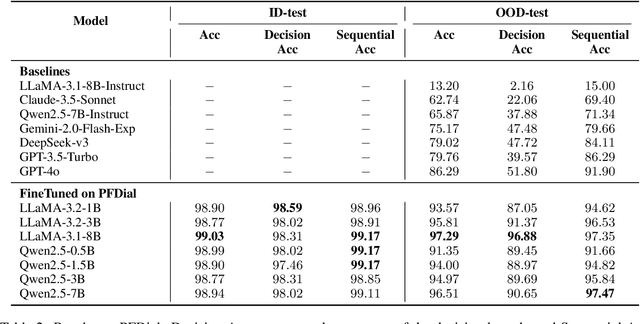
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models' performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
Predicting Large Language Model Capabilities on Closed-Book QA Tasks Using Only Information Available Prior to Training
Feb 06, 2025The GPT-4 technical report from OpenAI suggests that model performance on specific tasks can be predicted prior to training, though methodologies remain unspecified. This approach is crucial for optimizing resource allocation and ensuring data alignment with target tasks. To achieve this vision, we focus on predicting performance on Closed-book Question Answering (CBQA) tasks, which are closely tied to pre-training data and knowledge retention. We address three major challenges: 1) mastering the entire pre-training process, especially data construction; 2) evaluating a model's knowledge retention; and 3) predicting task-specific knowledge retention using only information available prior to training. To tackle these challenges, we pre-train three large language models (i.e., 1.6B, 7B, and 13B) using 560k dollars and 520k GPU hours. We analyze the pre-training data with knowledge triples and assess knowledge retention using established methods. Additionally, we introduce the SMI metric, an information-theoretic measure that quantifies the relationship between pre-training data, model size, and task-specific knowledge retention. Our experiments reveal a strong linear correlation ($\text{R}^2 > 0.84$) between the SMI metric and the model's accuracy on CBQA tasks across models of varying sizes (i.e., 1.1B, 1.6B, 7B, and 13B). The dataset, model, and code are available at https://github.com/yuhui1038/SMI.
TransferTOD: A Generalizable Chinese Multi-Domain Task-Oriented Dialogue System with Transfer Capabilities
Jul 31, 2024



Task-oriented dialogue (TOD) systems aim to efficiently handle task-oriented conversations, including information gathering. How to utilize ToD accurately, efficiently and effectively for information gathering has always been a critical and challenging task. Recent studies have demonstrated that Large Language Models (LLMs) excel in dialogue, instruction generation, and reasoning, and can significantly enhance the performance of TOD through fine-tuning. However, current datasets primarily cater to user-led systems and are limited to predefined specific scenarios and slots, thereby necessitating improvements in the proactiveness, diversity, and capabilities of TOD. In this study, we present a detailed multi-domain task-oriented data construction process for conversations, and a Chinese dialogue dataset generated based on this process, \textbf{TransferTOD}, which authentically simulates human-machine dialogues in 30 popular life service scenarios. Leveraging this dataset, we trained a \textbf{TransferTOD-7B} model using full-parameter fine-tuning, showcasing notable abilities in slot filling and questioning. Our work has demonstrated its strong generalization capabilities in various downstream scenarios, significantly enhancing both data utilization efficiency and system performance. The data is released in https://github.com/KongLongGeFDU/TransferTOD.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.