 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
Feb 05, 2026Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
A Unified Framework for Rethinking Policy Divergence Measures in GRPO
Feb 05, 2026Reinforcement Learning with Verified Reward (RLVR) has emerged as a critical paradigm for advancing the reasoning capabilities of Large Language Models (LLMs). Most existing RLVR methods, such as GRPO and its variants, ensure stable updates by constraining policy divergence through clipping likelihood ratios. This paper introduces a unified clipping framework that characterizes existing methods via a general notion of policy divergence, encompassing both likelihood ratios and Kullback-Leibler (KL) divergences and extending to alternative measures. The framework provides a principled foundation for systematically analyzing how different policy divergence measures affect exploration and performance. We further identify the KL3 estimator, a variance-reduced Monte Carlo estimator of the KL divergence, as a key policy divergence constraint. We theoretically demonstrate that the KL3-based constraint is mathematically equivalent to an asymmetric ratio-based clipping that reallocates probability mass toward high-confidence actions, promoting stronger exploration while retaining the simplicity of GRPO-style methods. Empirical results on mathematical reasoning benchmarks demonstrate that incorporating the KL3 estimator into GRPO improves both training stability and final performance, highlighting the importance of principled policy divergence constraints in policy optimization.
RASA: Routing-Aware Safety Alignment for Mixture-of-Experts Models
Feb 04, 2026Mixture-of-Experts (MoE) language models introduce unique challenges for safety alignment due to their sparse routing mechanisms, which can enable degenerate optimization behaviors under standard full-parameter fine-tuning. In our preliminary experiments, we observe that naively applying full-parameter safety fine-tuning to MoE models can reduce attack success rates through routing or expert dominance effects, rather than by directly repairing Safety-Critical Experts. To address this challenge, we propose RASA, a routing-aware expert-level alignment framework that explicitly repairs Safety-Critical Experts while preventing routing-based bypasses. RASA identifies experts disproportionately activated by successful jailbreaks, selectively fine-tunes only these experts under fixed routing, and subsequently enforces routing consistency with safety-aligned contexts. Across two representative MoE architectures and a diverse set of jailbreak attacks, RASA achieves near-perfect robustness, strong cross-attack generalization, and substantially reduced over-refusal, while preserving general capabilities on benchmarks such as MMLU, GSM8K, and TruthfulQA. Our results suggest that robust MoE safety alignment benefits from targeted expert repair rather than global parameter updates, offering a practical and architecture-preserving alternative to prior approaches.
OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
Jan 04, 2026Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
A data-physics hybrid generative model for patient-specific post-stroke motor rehabilitation using wearable sensor data
Dec 16, 2025Dynamic prediction of locomotor capacity after stroke is crucial for tailoring rehabilitation, yet current assessments provide only static impairment scores and do not indicate whether patients can safely perform specific tasks such as slope walking or stair climbing. Here, we develop a data-physics hybrid generative framework that reconstructs an individual stroke survivor's neuromuscular control from a single 20 m level-ground walking trial and predicts task-conditioned locomotion across rehabilitation scenarios. The system combines wearable-sensor kinematics, a proportional-derivative physics controller, a population Healthy Motion Atlas, and goal-conditioned deep reinforcement learning with behaviour cloning and generative adversarial imitation learning to generate physically plausible, patient-specific gait simulations for slopes and stairs. In 11 stroke survivors, the personalized controllers preserved idiosyncratic gait patterns while improving joint-angle and endpoint fidelity by 4.73% and 12.10%, respectively, and reducing training time to 25.56% relative to a physics-only baseline. In a multicentre pilot involving 21 inpatients, clinicians who used our locomotion predictions to guide task selection and difficulty obtained larger gains in Fugl-Meyer lower-extremity scores over 28 days of standard rehabilitation than control clinicians (mean change 6.0 versus 3.7 points). These findings indicate that our generative, task-predictive framework can augment clinical decision-making in post-stroke gait rehabilitation and provide a template for dynamically personalized motor recovery strategies.
Synthetic Voices, Real Threats: Evaluating Large Text-to-Speech Models in Generating Harmful Audio
Nov 14, 2025Modern text-to-speech (TTS) systems, particularly those built on Large Audio-Language Models (LALMs), generate high-fidelity speech that faithfully reproduces input text and mimics specified speaker identities. While prior misuse studies have focused on speaker impersonation, this work explores a distinct content-centric threat: exploiting TTS systems to produce speech containing harmful content. Realizing such threats poses two core challenges: (1) LALM safety alignment frequently rejects harmful prompts, yet existing jailbreak attacks are ill-suited for TTS because these systems are designed to faithfully vocalize any input text, and (2) real-world deployment pipelines often employ input/output filters that block harmful text and audio. We present HARMGEN, a suite of five attacks organized into two families that address these challenges. The first family employs semantic obfuscation techniques (Concat, Shuffle) that conceal harmful content within text. The second leverages audio-modality exploits (Read, Spell, Phoneme) that inject harmful content through auxiliary audio channels while maintaining benign textual prompts. Through evaluation across five commercial LALMs-based TTS systems and three datasets spanning two languages, we demonstrate that our attacks substantially reduce refusal rates and increase the toxicity of generated speech. We further assess both reactive countermeasures deployed by audio-streaming platforms and proactive defenses implemented by TTS providers. Our analysis reveals critical vulnerabilities: deepfake detectors underperform on high-fidelity audio; reactive moderation can be circumvented by adversarial perturbations; while proactive moderation detects 57-93% of attacks. Our work highlights a previously underexplored content-centric misuse vector for TTS and underscore the need for robust cross-modal safeguards throughout training and deployment.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation
Jun 04, 2025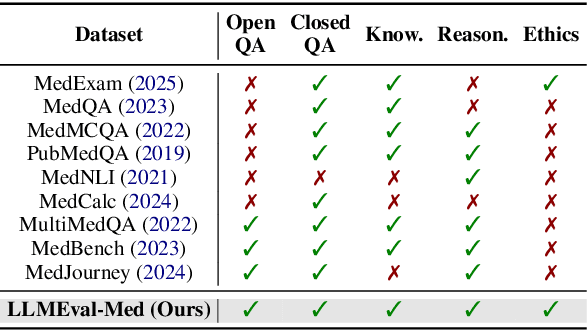
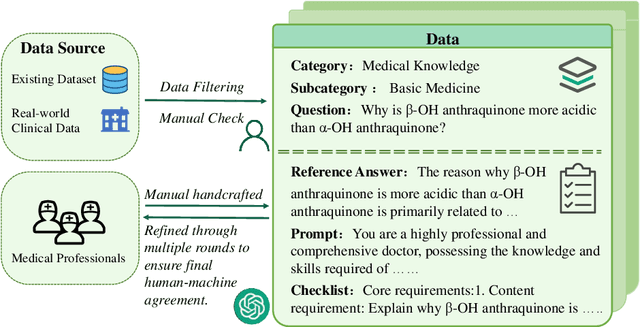
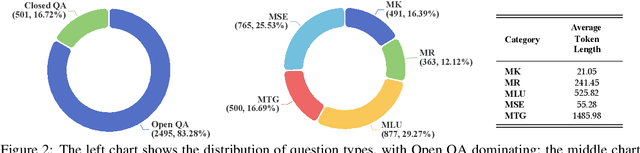
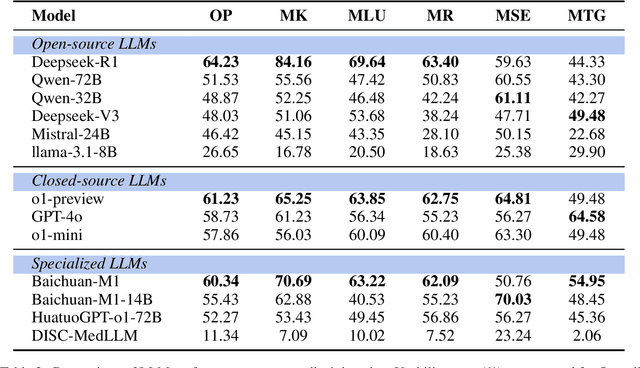
Evaluating large language models (LLMs) in medicine is crucial because medical applications require high accuracy with little room for error. Current medical benchmarks have three main types: medical exam-based, comprehensive medical, and specialized assessments. However, these benchmarks have limitations in question design (mostly multiple-choice), data sources (often not derived from real clinical scenarios), and evaluation methods (poor assessment of complex reasoning). To address these issues, we present LLMEval-Med, a new benchmark covering five core medical areas, including 2,996 questions created from real-world electronic health records and expert-designed clinical scenarios. We also design an automated evaluation pipeline, incorporating expert-developed checklists into our LLM-as-Judge framework. Furthermore, our methodology validates machine scoring through human-machine agreement analysis, dynamically refining checklists and prompts based on expert feedback to ensure reliability. We evaluate 13 LLMs across three categories (specialized medical models, open-source models, and closed-source models) on LLMEval-Med, providing valuable insights for the safe and effective deployment of LLMs in medical domains. The dataset is released in https://github.com/llmeval/LLMEval-Med.
Self-Destructive Language Model
May 18, 2025


Harmful fine-tuning attacks pose a major threat to the security of large language models (LLMs), allowing adversaries to compromise safety guardrails with minimal harmful data. While existing defenses attempt to reinforce LLM alignment, they fail to address models' inherent "trainability" on harmful data, leaving them vulnerable to stronger attacks with increased learning rates or larger harmful datasets. To overcome this critical limitation, we introduce SEAM, a novel alignment-enhancing defense that transforms LLMs into self-destructive models with intrinsic resilience to misalignment attempts. Specifically, these models retain their capabilities for legitimate tasks while exhibiting substantial performance degradation when fine-tuned on harmful data. The protection is achieved through a novel loss function that couples the optimization trajectories of benign and harmful data, enhanced with adversarial gradient ascent to amplify the self-destructive effect. To enable practical training, we develop an efficient Hessian-free gradient estimate with theoretical error bounds. Extensive evaluation across LLMs and datasets demonstrates that SEAM creates a no-win situation for adversaries: the self-destructive models achieve state-of-the-art robustness against low-intensity attacks and undergo catastrophic performance collapse under high-intensity attacks, rendering them effectively unusable. (warning: this paper contains potentially harmful content generated by LLMs.)
AutoRAN: Weak-to-Strong Jailbreaking of Large Reasoning Models
May 16, 2025This paper presents AutoRAN, the first automated, weak-to-strong jailbreak attack framework targeting large reasoning models (LRMs). At its core, AutoRAN leverages a weak, less-aligned reasoning model to simulate the target model's high-level reasoning structures, generates narrative prompts, and iteratively refines candidate prompts by incorporating the target model's intermediate reasoning steps. We evaluate AutoRAN against state-of-the-art LRMs including GPT-o3/o4-mini and Gemini-2.5-Flash across multiple benchmark datasets (AdvBench, HarmBench, and StrongReject). Results demonstrate that AutoRAN achieves remarkable success rates (approaching 100%) within one or a few turns across different LRMs, even when judged by a robustly aligned external model. This work reveals that leveraging weak reasoning models can effectively exploit the critical vulnerabilities of much more capable reasoning models, highlighting the need for improved safety measures specifically designed for reasoning-based models. The code for replicating AutoRAN and running records are available at: (https://github.com/JACKPURCELL/AutoRAN-public). (warning: this paper contains potentially harmful content generated by LRMs.)