 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectly Forecasting Belief for Reinforcement Learning with Delays
May 01, 2025Reinforcement learning (RL) with delays is challenging as sensory perceptions lag behind the actual events: the RL agent needs to estimate the real state of its environment based on past observations. State-of-the-art (SOTA) methods typically employ recursive, step-by-step forecasting of states. This can cause the accumulation of compounding errors. To tackle this problem, our novel belief estimation method, named Directly Forecasting Belief Transformer (DFBT), directly forecasts states from observations without incrementally estimating intermediate states step-by-step. We theoretically demonstrate that DFBT greatly reduces compounding errors of existing recursively forecasting methods, yielding stronger performance guarantees. In experiments with D4RL offline datasets, DFBT reduces compounding errors with remarkable prediction accuracy. DFBT's capability to forecast state sequences also facilitates multi-step bootstrapping, thus greatly improving learning efficiency. On the MuJoCo benchmark, our DFBT-based method substantially outperforms SOTA baselines.
Variational Delayed Policy Optimization
May 23, 2024In environments with delayed observation, state augmentation by including actions within the delay window is adopted to retrieve Markovian property to enable reinforcement learning (RL). However, state-of-the-art (SOTA) RL techniques with Temporal-Difference (TD) learning frameworks often suffer from learning inefficiency, due to the significant expansion of the augmented state space with the delay. To improve learning efficiency without sacrificing performance, this work introduces a novel framework called Variational Delayed Policy Optimization (VDPO), which reformulates delayed RL as a variational inference problem. This problem is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. We not only provide a theoretical analysis of VDPO in terms of sample complexity and performance, but also empirically demonstrate that VDPO can achieve consistent performance with SOTA methods, with a significant enhancement of sample efficiency (approximately 50\% less amount of samples) in the MuJoCo benchmark.
Boosting Long-Delayed Reinforcement Learning with Auxiliary Short-Delayed Task
Feb 05, 2024Reinforcement learning is challenging in delayed scenarios, a common real-world situation where observations and interactions occur with delays. State-of-the-art (SOTA) state-augmentation techniques either suffer from the state-space explosion along with the delayed steps, or performance degeneration in stochastic environments. To address these challenges, our novel Auxiliary-Delayed Reinforcement Learning (AD-RL) leverages an auxiliary short-delayed task to accelerate the learning on a long-delayed task without compromising the performance in stochastic environments. Specifically, AD-RL learns the value function in the short-delayed task and then employs it with the bootstrapping and policy improvement techniques in the long-delayed task. We theoretically show that this can greatly reduce the sample complexity compared to directly learning on the original long-delayed task. On deterministic and stochastic benchmarks, our method remarkably outperforms the SOTAs in both sample efficiency and policy performance.
Automatic Routability Predictor Development Using Neural Architecture Search
Dec 03, 2020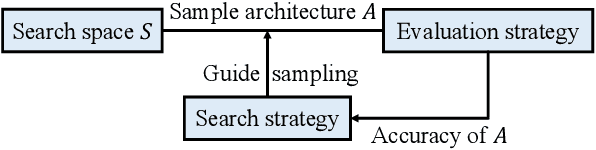
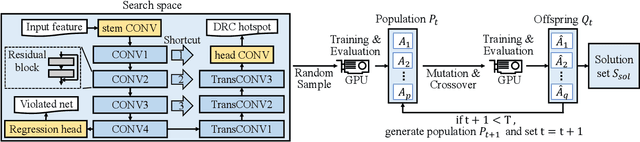
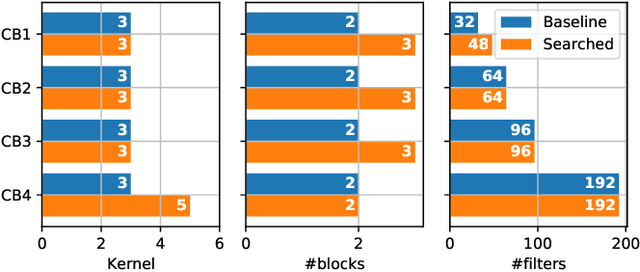
The rise of machine learning technology inspires a boom of its applications in electronic design automation (EDA) and helps improve the degree of automation in chip designs. However, manually crafted machine learning models require extensive human expertise and tremendous engineering efforts. In this work, we leverage neural architecture search (NAS) to automatically develop high-quality neural architectures for routability prediction, which guides cell placement toward routable solutions. Experimental results demonstrate that the automatically generated neural architectures clearly outperform the manual solutions. Compared to the average case of manually designed models, NAS-generated models achieve $5.6\%$ higher Kendall's $\tau$ in predicting the number of nets with DRC violations and $1.95\%$ larger area under ROC curve (ROC-AUC) in DRC hotspots detection.
A Game Theoretical Error-Correction Framework for Secure Traffic-Sign Classification
Jan 30, 2019
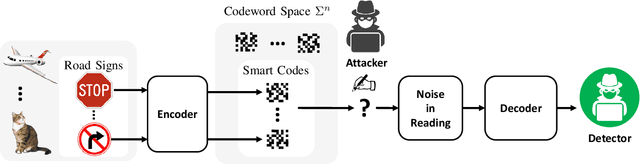
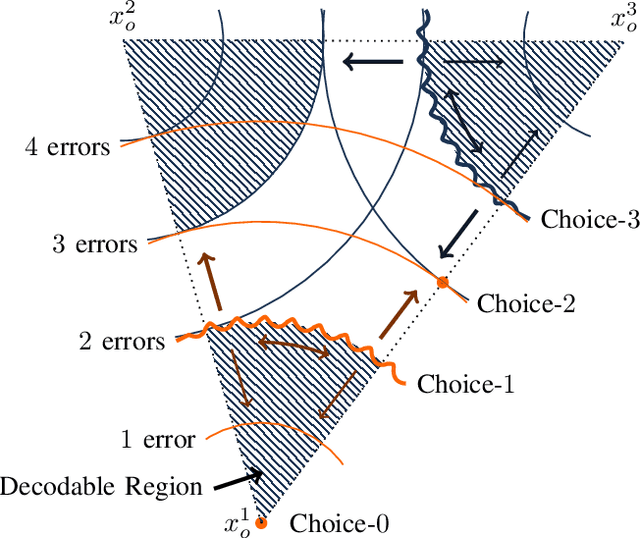
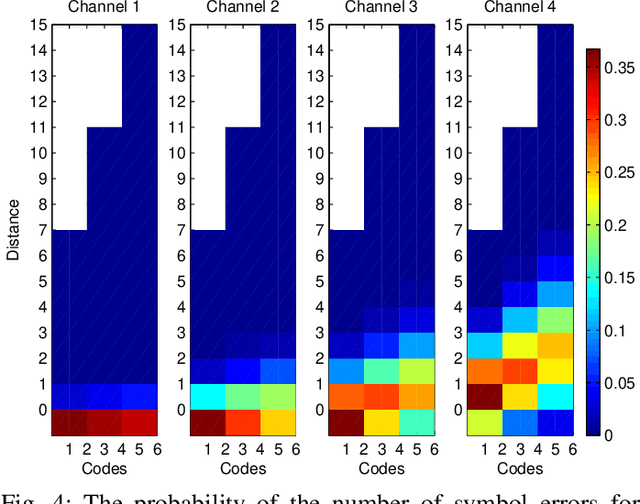
We introduce a game theoretical error-correction framework to design classification algorithms that are reliable even in adversarial environments, with a specific focus on traffic-sign classification. Machine learning algorithms possess inherent vulnerabilities against maliciously crafted inputs especially at high dimensional input spaces. We seek to achieve reliable and timely performance in classification by redesigning the input space physically to significantly lower dimensions. Traffic-sign classification is an important use-case enabling the redesign of the inputs since traffic-signs have already been designed for their easy recognition by human drivers. We encode the original input samples to, e.g., strings of bits, through error-correction methods that can provide certain distance guarantees in-between any two different encoded inputs. And we model the interaction between the defense and the adversary as a game. Then, we analyze the underlying game using the concept of hierarchical equilibrium, where the defense strategies are designed by taking into account the best possible attack against them. At large scale, for computational simplicity, we provide an approximate solution, where we transform the problem into an efficient linear program with substantially small size compared to the original size of the entire input space. Finally, we examine the performance of the proposed scheme over different traffic-sign classification scenarios.
Reliable Intersection Control in Non-cooperative Environments
Feb 22, 2018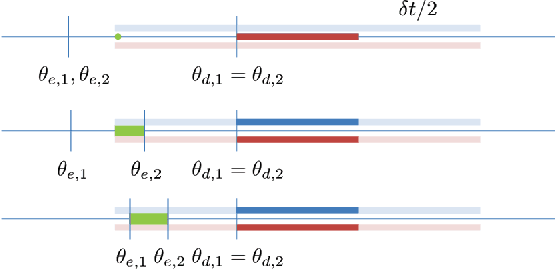
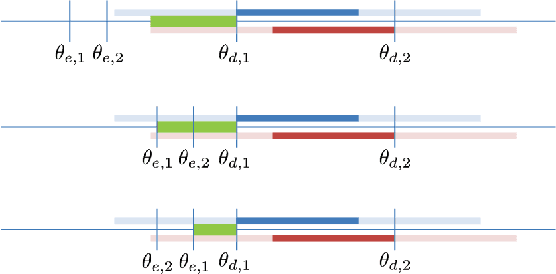
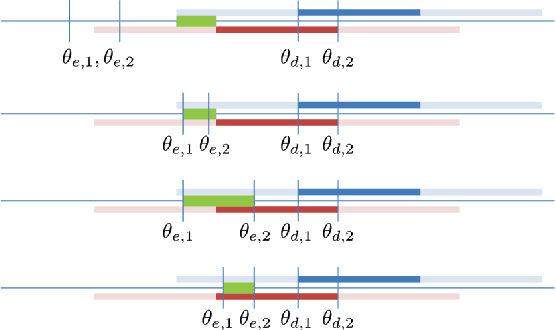
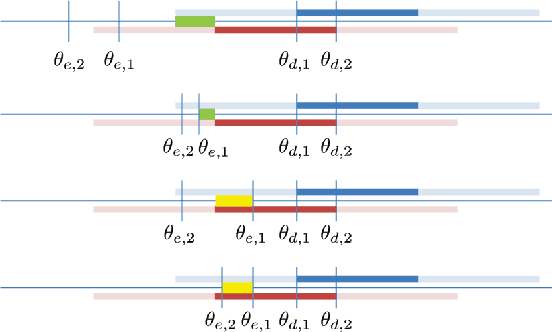
We propose a reliable intersection control mechanism for strategic autonomous and connected vehicles (agents) in non-cooperative environments. Each agent has access to his/her earliest possible and desired passing times, and reports a passing time to the intersection manager, who allocates the intersection temporally to the agents in a First-Come-First-Serve basis. However, the agents might have conflicting interests and can take actions strategically. To this end, we analyze the strategic behaviors of the agents and formulate Nash equilibria for all possible scenarios. Furthermore, among all Nash equilibria we identify a socially optimal equilibrium that leads to a fair intersection allocation, and correspondingly we describe a strategy-proof intersection mechanism, which achieves reliable intersection control such that the strategic agents do not have any incentive to misreport their passing times strategically.