 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROP: Circuit Retrieval and Optimization with Parameter Guidance using LLMs
Jul 02, 2025Modern very large-scale integration (VLSI) design requires the implementation of integrated circuits using electronic design automation (EDA) tools. Due to the complexity of EDA algorithms, the vast parameter space poses a huge challenge to chip design optimization, as the combination of even moderate numbers of parameters creates an enormous solution space to explore. Manual parameter selection remains industrial practice despite being excessively laborious and limited by expert experience. To address this issue, we present CROP, the first large language model (LLM)-powered automatic VLSI design flow tuning framework. Our approach includes: (1) a scalable methodology for transforming RTL source code into dense vector representations, (2) an embedding-based retrieval system for matching designs with semantically similar circuits, and (3) a retrieval-augmented generation (RAG)-enhanced LLM-guided parameter search system that constrains the search process with prior knowledge from similar designs. Experiment results demonstrate CROP's ability to achieve superior quality-of-results (QoR) with fewer iterations than existing approaches on industrial designs, including a 9.9% reduction in power consumption.
A Survey of Research in Large Language Models for Electronic Design Automation
Jan 16, 2025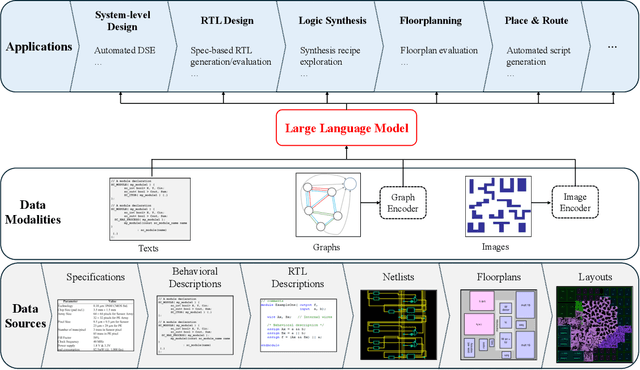
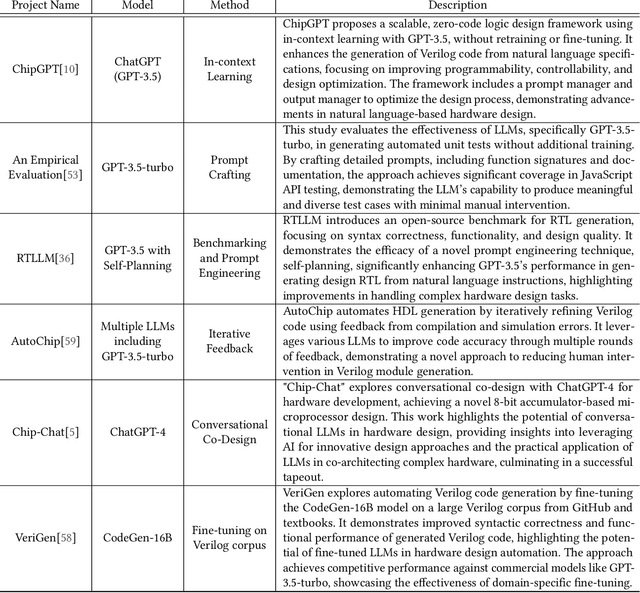
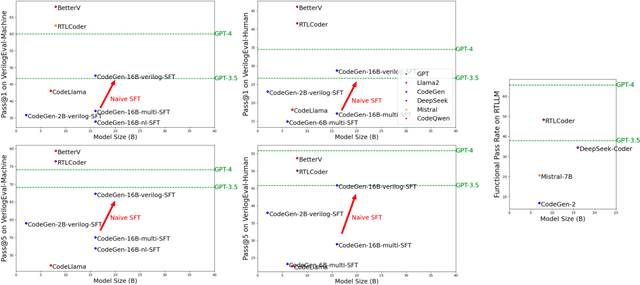
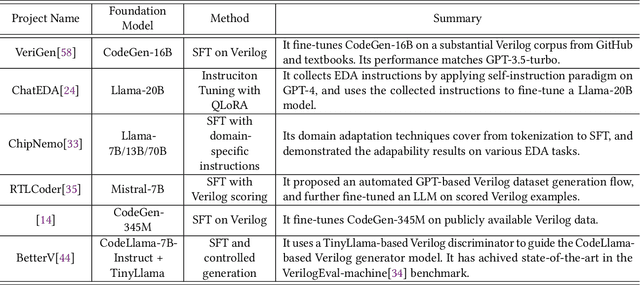
Within the rapidly evolving domain of Electronic Design Automation (EDA), Large Language Models (LLMs) have emerged as transformative technologies, offering unprecedented capabilities for optimizing and automating various aspects of electronic design. This survey provides a comprehensive exploration of LLM applications in EDA, focusing on advancements in model architectures, the implications of varying model sizes, and innovative customization techniques that enable tailored analytical insights. By examining the intersection of LLM capabilities and EDA requirements, the paper highlights the significant impact these models have on extracting nuanced understandings from complex datasets. Furthermore, it addresses the challenges and opportunities in integrating LLMs into EDA workflows, paving the way for future research and application in this dynamic field. Through this detailed analysis, the survey aims to offer valuable insights to professionals in the EDA industry, AI researchers, and anyone interested in the convergence of advanced AI technologies and electronic design.
PANDA: Architecture-Level Power Evaluation by Unifying Analytical and Machine Learning Solutions
Dec 14, 2023



Power efficiency is a critical design objective in modern microprocessor design. To evaluate the impact of architectural-level design decisions, an accurate yet efficient architecture-level power model is desired. However, widely adopted data-independent analytical power models like McPAT and Wattch have been criticized for their unreliable accuracy. While some machine learning (ML) methods have been proposed for architecture-level power modeling, they rely on sufficient known designs for training and perform poorly when the number of available designs is limited, which is typically the case in realistic scenarios. In this work, we derive a general formulation that unifies existing architecture-level power models. Based on the formulation, we propose PANDA, an innovative architecture-level solution that combines the advantages of analytical and ML power models. It achieves unprecedented high accuracy on unknown new designs even when there are very limited designs for training, which is a common challenge in practice. Besides being an excellent power model, it can predict area, performance, and energy accurately. PANDA further supports power prediction for unknown new technology nodes. In our experiments, besides validating the superior performance and the wide range of functionalities of PANDA, we also propose an application scenario, where PANDA proves to identify high-performance design configurations given a power constraint.
EDALearn: A Comprehensive RTL-to-Signoff EDA Benchmark for Democratized and Reproducible ML for EDA Research
Dec 04, 2023



The application of Machine Learning (ML) in Electronic Design Automation (EDA) for Very Large-Scale Integration (VLSI) design has garnered significant research attention. Despite the requirement for extensive datasets to build effective ML models, most studies are limited to smaller, internally generated datasets due to the lack of comprehensive public resources. In response, we introduce EDALearn, the first holistic, open-source benchmark suite specifically for ML tasks in EDA. This benchmark suite presents an end-to-end flow from synthesis to physical implementation, enriching data collection across various stages. It fosters reproducibility and promotes research into ML transferability across different technology nodes. Accommodating a wide range of VLSI design instances and sizes, our benchmark aptly represents the complexity of contemporary VLSI designs. Additionally, we provide an in-depth data analysis, enabling users to fully comprehend the attributes and distribution of our data, which is essential for creating efficient ML models. Our contributions aim to encourage further advances in the ML-EDA domain.
Towards Collaborative Intelligence: Routability Estimation based on Decentralized Private Data
Mar 30, 2022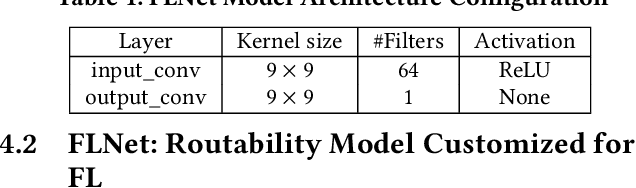
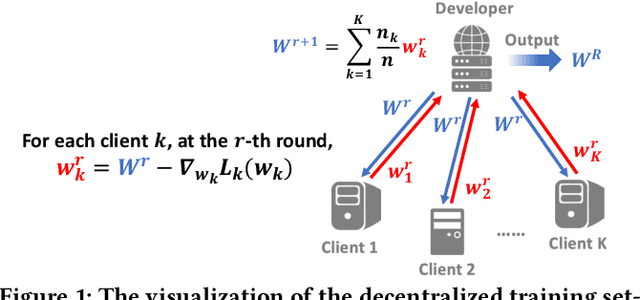
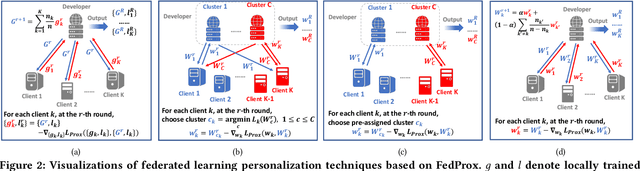
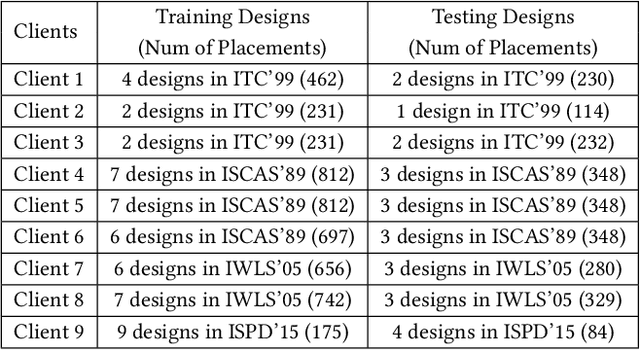
Applying machine learning (ML) in design flow is a popular trend in EDA with various applications from design quality predictions to optimizations. Despite its promise, which has been demonstrated in both academic researches and industrial tools, its effectiveness largely hinges on the availability of a large amount of high-quality training data. In reality, EDA developers have very limited access to the latest design data, which is owned by design companies and mostly confidential. Although one can commission ML model training to a design company, the data of a single company might be still inadequate or biased, especially for small companies. Such data availability problem is becoming the limiting constraint on future growth of ML for chip design. In this work, we propose an Federated-Learning based approach for well-studied ML applications in EDA. Our approach allows an ML model to be collaboratively trained with data from multiple clients but without explicit access to the data for respecting their data privacy. To further strengthen the results, we co-design a customized ML model FLNet and its personalization under the decentralized training scenario. Experiments on a comprehensive dataset show that collaborative training improves accuracy by 11% compared with individual local models, and our customized model FLNet significantly outperforms the best of previous routability estimators in this collaborative training flow.
The Dark Side: Security Concerns in Machine Learning for EDA
Mar 20, 2022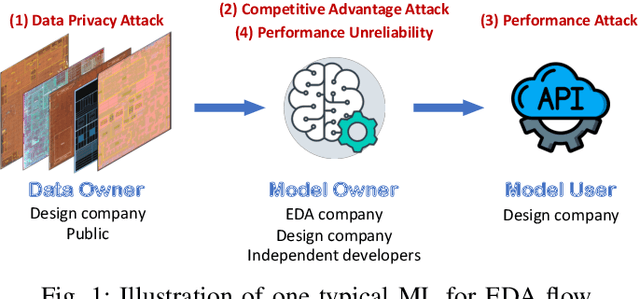
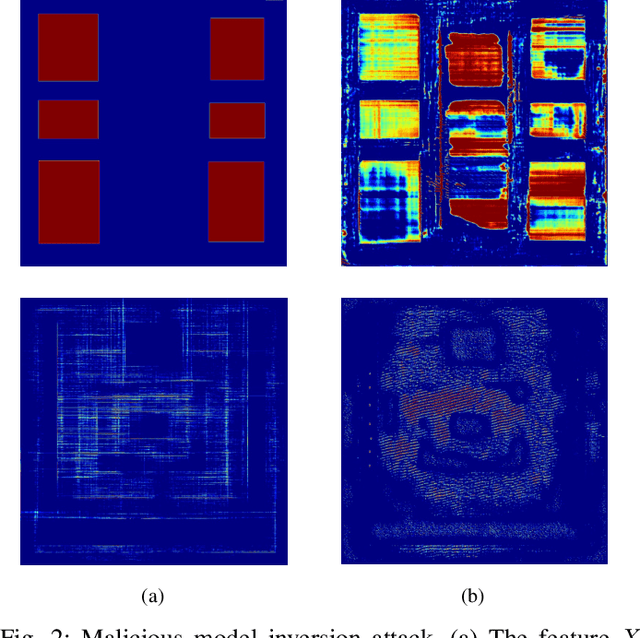

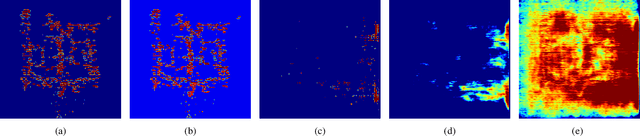
The growing IC complexity has led to a compelling need for design efficiency improvement through new electronic design automation (EDA) methodologies. In recent years, many unprecedented efficient EDA methods have been enabled by machine learning (ML) techniques. While ML demonstrates its great potential in circuit design, however, the dark side about security problems, is seldomly discussed. This paper gives a comprehensive and impartial summary of all security concerns we have observed in ML for EDA. Many of them are hidden or neglected by practitioners in this field. In this paper, we first provide our taxonomy to define four major types of security concerns, then we analyze different application scenarios and special properties in ML for EDA. After that, we present our detailed analysis of each security concern with experiments.
Lithography Hotspot Detection via Heterogeneous Federated Learning with Local Adaptation
Jul 30, 2021
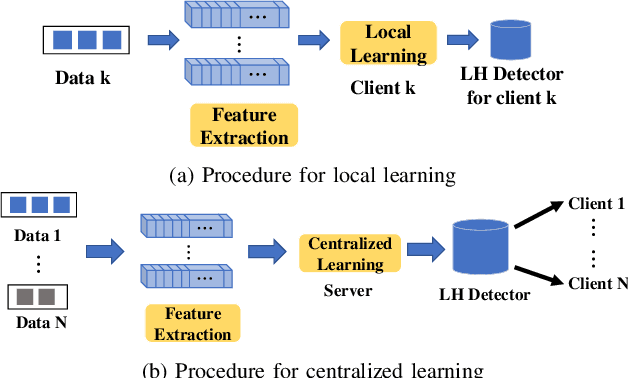
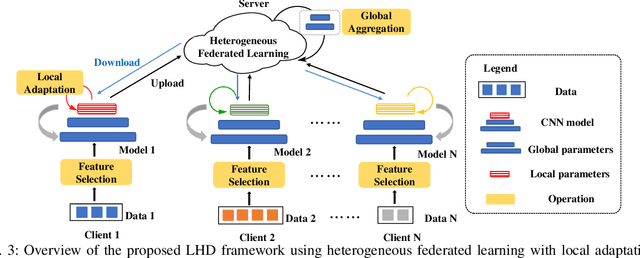
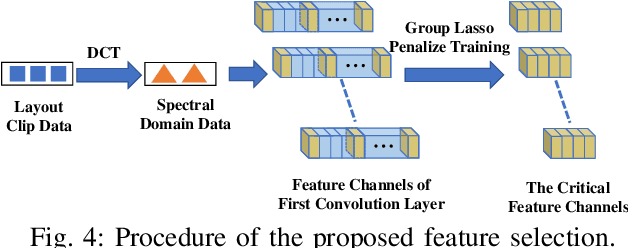
As technology scaling is approaching the physical limit, lithography hotspot detection has become an essential task in design for manufacturability. While the deployment of pattern matching or machine learning in hotspot detection can help save significant simulation time, such methods typically demand for non-trivial quality data to build the model, which most design houses are short of. Moreover, the design houses are also unwilling to directly share such data with the other houses to build a unified model, which can be ineffective for the design house with unique design patterns due to data insufficiency. On the other hand, with data homogeneity in each design house, the locally trained models can be easily over-fitted, losing generalization ability and robustness. In this paper, we propose a heterogeneous federated learning framework for lithography hotspot detection that can address the aforementioned issues. On one hand, the framework can build a more robust centralized global sub-model through heterogeneous knowledge sharing while keeping local data private. On the other hand, the global sub-model can be combined with a local sub-model to better adapt to local data heterogeneity. The experimental results show that the proposed framework can overcome the challenge of non-independent and identically distributed (non-IID) data and heterogeneous communication to achieve very high performance in comparison to other state-of-the-art methods while guaranteeing a good convergence rate in various scenarios.
Automatic Routability Predictor Development Using Neural Architecture Search
Dec 03, 2020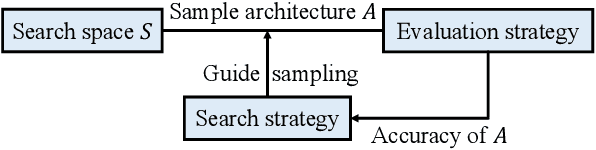
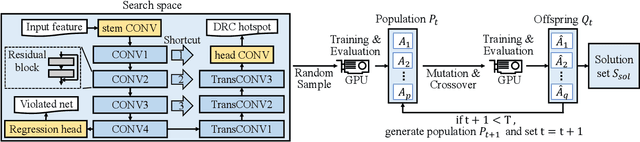
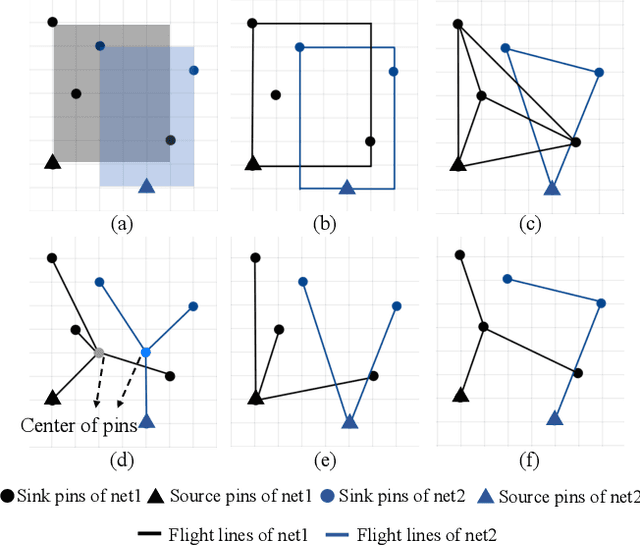
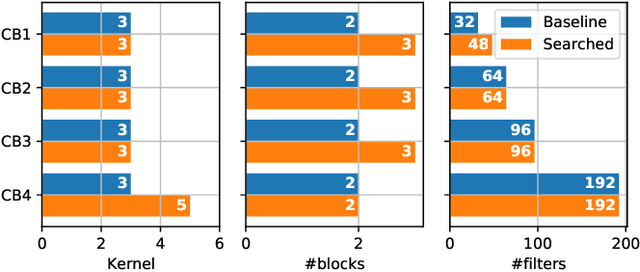
The rise of machine learning technology inspires a boom of its applications in electronic design automation (EDA) and helps improve the degree of automation in chip designs. However, manually crafted machine learning models require extensive human expertise and tremendous engineering efforts. In this work, we leverage neural architecture search (NAS) to automatically develop high-quality neural architectures for routability prediction, which guides cell placement toward routable solutions. Experimental results demonstrate that the automatically generated neural architectures clearly outperform the manual solutions. Compared to the average case of manually designed models, NAS-generated models achieve $5.6\%$ higher Kendall's $\tau$ in predicting the number of nets with DRC violations and $1.95\%$ larger area under ROC curve (ROC-AUC) in DRC hotspots detection.