 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROP: Circuit Retrieval and Optimization with Parameter Guidance using LLMs
Jul 02, 2025Modern very large-scale integration (VLSI) design requires the implementation of integrated circuits using electronic design automation (EDA) tools. Due to the complexity of EDA algorithms, the vast parameter space poses a huge challenge to chip design optimization, as the combination of even moderate numbers of parameters creates an enormous solution space to explore. Manual parameter selection remains industrial practice despite being excessively laborious and limited by expert experience. To address this issue, we present CROP, the first large language model (LLM)-powered automatic VLSI design flow tuning framework. Our approach includes: (1) a scalable methodology for transforming RTL source code into dense vector representations, (2) an embedding-based retrieval system for matching designs with semantically similar circuits, and (3) a retrieval-augmented generation (RAG)-enhanced LLM-guided parameter search system that constrains the search process with prior knowledge from similar designs. Experiment results demonstrate CROP's ability to achieve superior quality-of-results (QoR) with fewer iterations than existing approaches on industrial designs, including a 9.9% reduction in power consumption.
A Survey of Research in Large Language Models for Electronic Design Automation
Jan 16, 2025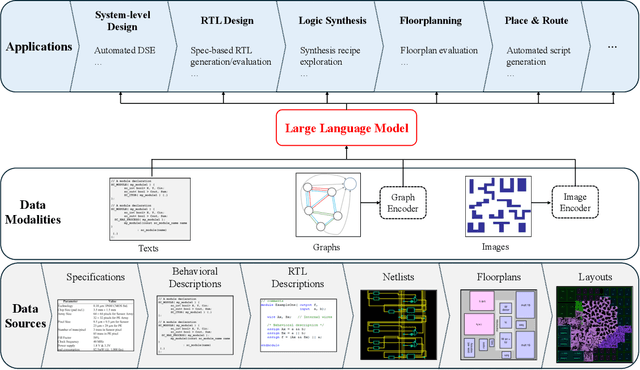
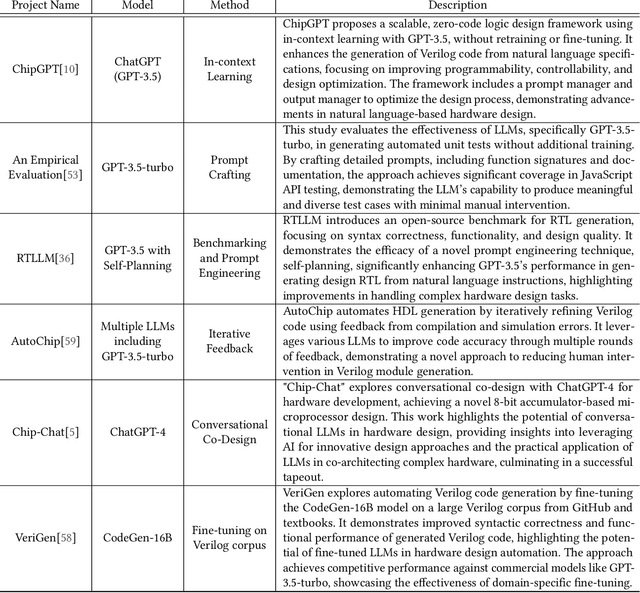
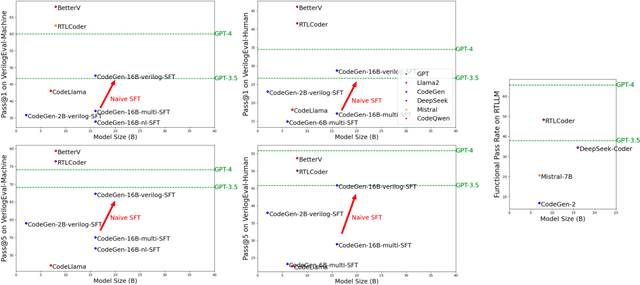
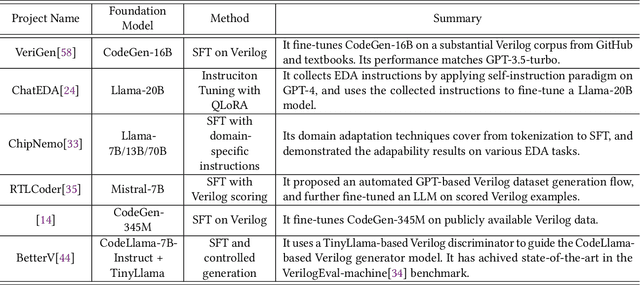
Within the rapidly evolving domain of Electronic Design Automation (EDA), Large Language Models (LLMs) have emerged as transformative technologies, offering unprecedented capabilities for optimizing and automating various aspects of electronic design. This survey provides a comprehensive exploration of LLM applications in EDA, focusing on advancements in model architectures, the implications of varying model sizes, and innovative customization techniques that enable tailored analytical insights. By examining the intersection of LLM capabilities and EDA requirements, the paper highlights the significant impact these models have on extracting nuanced understandings from complex datasets. Furthermore, it addresses the challenges and opportunities in integrating LLMs into EDA workflows, paving the way for future research and application in this dynamic field. Through this detailed analysis, the survey aims to offer valuable insights to professionals in the EDA industry, AI researchers, and anyone interested in the convergence of advanced AI technologies and electronic design.
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
PatternPaint: Generating Layout Patterns Using Generative AI and Inpainting Techniques
Sep 02, 2024



Generation of VLSI layout patterns is essential for a wide range of Design For Manufacturability (DFM) studies. In this study, we investigate the potential of generative machine learning models for creating design rule legal metal layout patterns. Our results demonstrate that the proposed model can generate legal patterns in complex design rule settings and achieves a high diversity score. The designed system, with its flexible settings, supports both pattern generation with localized changes, and design rule violation correction. Our methodology is validated on Intel 18A Process Design Kit (PDK) and can produce a wide range of DRC-compliant pattern libraries with only 20 starter patterns.
PANDA: Architecture-Level Power Evaluation by Unifying Analytical and Machine Learning Solutions
Dec 14, 2023Power efficiency is a critical design objective in modern microprocessor design. To evaluate the impact of architectural-level design decisions, an accurate yet efficient architecture-level power model is desired. However, widely adopted data-independent analytical power models like McPAT and Wattch have been criticized for their unreliable accuracy. While some machine learning (ML) methods have been proposed for architecture-level power modeling, they rely on sufficient known designs for training and perform poorly when the number of available designs is limited, which is typically the case in realistic scenarios. In this work, we derive a general formulation that unifies existing architecture-level power models. Based on the formulation, we propose PANDA, an innovative architecture-level solution that combines the advantages of analytical and ML power models. It achieves unprecedented high accuracy on unknown new designs even when there are very limited designs for training, which is a common challenge in practice. Besides being an excellent power model, it can predict area, performance, and energy accurately. PANDA further supports power prediction for unknown new technology nodes. In our experiments, besides validating the superior performance and the wide range of functionalities of PANDA, we also propose an application scenario, where PANDA proves to identify high-performance design configurations given a power constraint.