 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
Neuromorphic Algorithm-hardware Codesign for Temporal Pattern Learning
May 07, 2021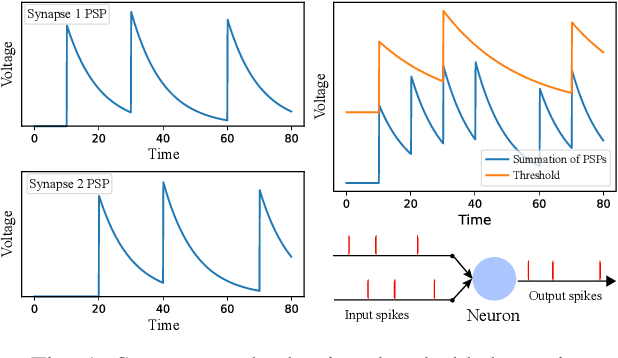
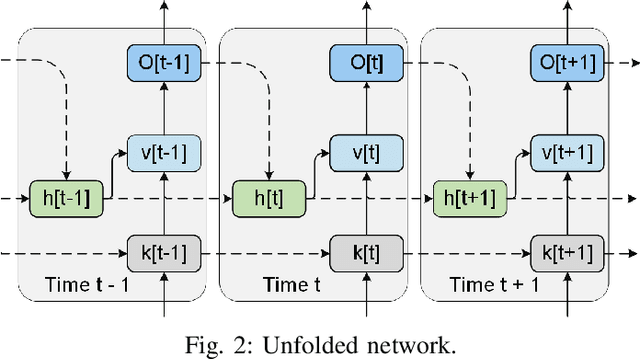
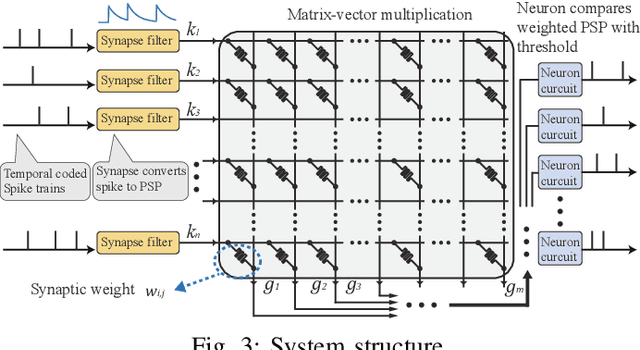
Neuromorphic computing and spiking neural networks (SNN) mimic the behavior of biological systems and have drawn interest for their potential to perform cognitive tasks with high energy efficiency. However, some factors such as temporal dynamics and spike timings prove critical for information processing but are often ignored by existing works, limiting the performance and applications of neuromorphic computing. On one hand, due to the lack of effective SNN training algorithms, it is difficult to utilize the temporal neural dynamics. Many existing algorithms still treat neuron activation statistically. On the other hand, utilizing temporal neural dynamics also poses challenges to hardware design. Synapses exhibit temporal dynamics, serving as memory units that hold historical information, but are often simplified as a connection with weight. Most current models integrate synaptic activations in some storage medium to represent membrane potential and institute a hard reset of membrane potential after the neuron emits a spike. This is done for its simplicity in hardware, requiring only a "clear" signal to wipe the storage medium, but destroys temporal information stored in the neuron. In this work, we derive an efficient training algorithm for Leaky Integrate and Fire neurons, which is capable of training a SNN to learn complex spatial temporal patterns. We achieved competitive accuracy on two complex datasets. We also demonstrate the advantage of our model by a novel temporal pattern association task. Codesigned with this algorithm, we have developed a CMOS circuit implementation for a memristor-based network of neuron and synapses which retains critical neural dynamics with reduced complexity. This circuit implementation of the neuron model is simulated to demonstrate its ability to react to temporal spiking patterns with an adaptive threshold.
RED: A ReRAM-based Deconvolution Accelerator
Jul 05, 2019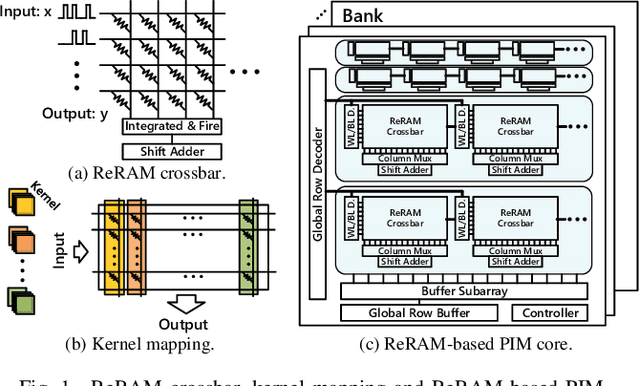

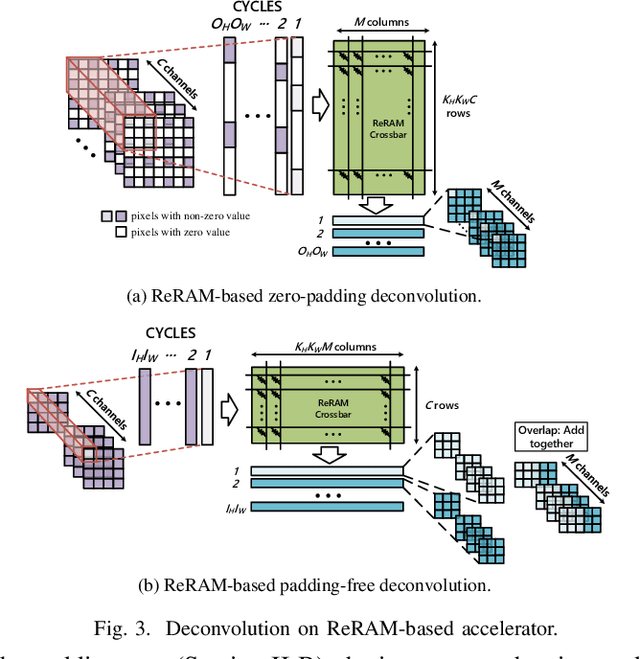
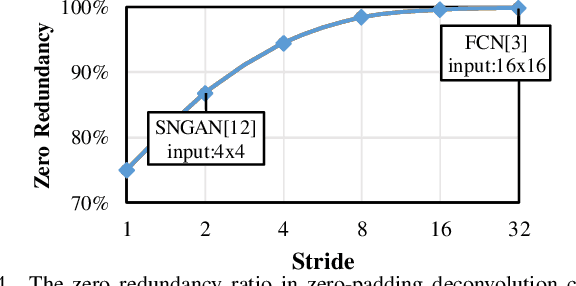
Deconvolution has been widespread in neural networks. For example, it is essential for performing unsupervised learning in generative adversarial networks or constructing fully convolutional networks for semantic segmentation. Resistive RAM (ReRAM)-based processing-in-memory architecture has been widely explored in accelerating convolutional computation and demonstrates good performance. Performing deconvolution on existing ReRAM-based accelerator designs, however, suffers from long latency and high energy consumption because deconvolutional computation includes not only convolution but also extra add-on operations. To realize the more efficient execution for deconvolution, we analyze its computation requirement and propose a ReRAM-based accelerator design, namely, RED. More specific, RED integrates two orthogonal methods, the pixel-wise mapping scheme for reducing redundancy caused by zero-inserting operations and the zero-skipping data flow for increasing the computation parallelism and therefore improving performance. Experimental evaluations show that compared to the state-of-the-art ReRAM-based accelerator, RED can speed up operation 3.69x~1.15x and reduce 8%~88.36% energy consumption.