 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamming Attention Distillation: Binarizing Keys and Queries for Efficient Long-Context Transformers
Feb 03, 2025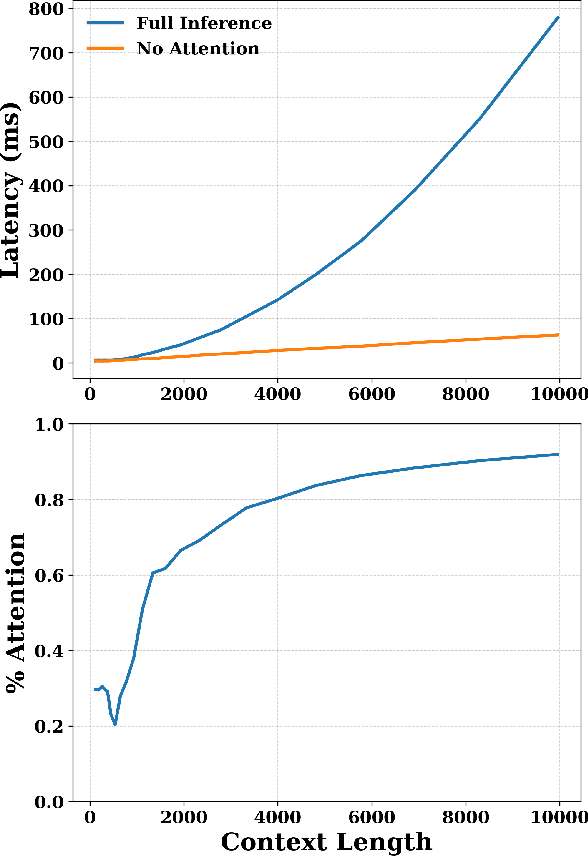
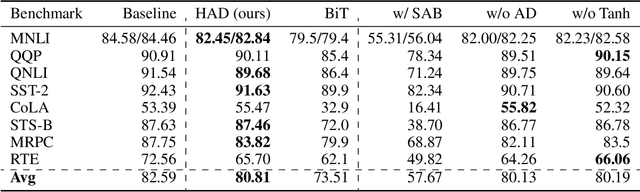
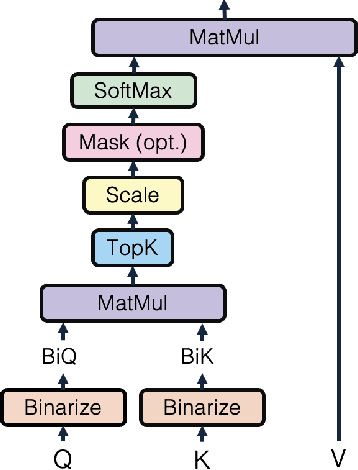
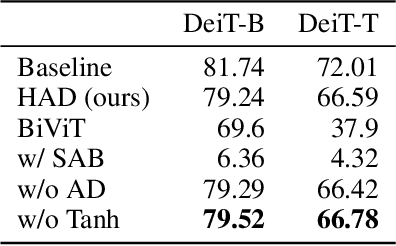
Pre-trained transformer models with extended context windows are notoriously expensive to run at scale, often limiting real-world deployment due to their high computational and memory requirements. In this paper, we introduce Hamming Attention Distillation (HAD), a novel framework that binarizes keys and queries in the attention mechanism to achieve significant efficiency gains. By converting keys and queries into {-1, +1} vectors and replacing dot-product operations with efficient Hamming distance computations, our method drastically reduces computational overhead. Additionally, we incorporate attention matrix sparsification to prune low-impact activations, which further reduces the cost of processing long-context sequences. \par Despite these aggressive compression strategies, our distilled approach preserves a high degree of representational power, leading to substantially improved accuracy compared to prior transformer binarization methods. We evaluate HAD on a range of tasks and models, including the GLUE benchmark, ImageNet, and QuALITY, demonstrating state-of-the-art performance among binarized Transformers while drastically reducing the computational costs of long-context inference. \par We implement HAD in custom hardware simulations, demonstrating superior performance characteristics compared to a custom hardware implementation of standard attention. HAD achieves just $\mathbf{1.78}\%$ performance losses on GLUE compared to $9.08\%$ in state-of-the-art binarization work, and $\mathbf{2.5}\%$ performance losses on ImageNet compared to $12.14\%$, all while targeting custom hardware with a $\mathbf{79}\%$ area reduction and $\mathbf{87}\%$ power reduction compared to its standard attention counterpart.
MonoSparse-CAM: Harnessing Monotonicity and Sparsity for Enhanced Tree Model Processing on CAMs
Jul 12, 2024



Despite significant advancements in AI driven by neural networks, tree-based machine learning (TBML) models excel on tabular data. These models exhibit promising energy efficiency, and high performance, particularly when accelerated on analog content-addressable memory (aCAM) arrays. However, optimizing their hardware deployment, especially in leveraging TBML model structure and aCAM circuitry, remains challenging. In this paper, we introduce MonoSparse-CAM, a novel content-addressable memory (CAM) based computing optimization technique. MonoSparse-CAM efficiently leverages TBML model sparsity and CAM array circuits, enhancing processing performance. Our experiments show that MonoSparse-CAM reduces energy consumption by up to 28.56x compared to raw processing and 18.51x compared to existing deployment optimization techniques. Additionally, it consistently achieves at least 1.68x computational efficiency over current methods. By enabling energy-efficient CAM-based computing while preserving performance regardless of the array sparsity, MonoSparse-CAM addresses the high energy consumption problem of CAM which hinders processing of large arrays. Our contributions are twofold: we propose MonoSparse-CAM as an effective deployment optimization solution for CAM-based computing, and we investigate the impact of TBML model structure on array sparsity. This work provides crucial insights for energy-efficient TBML on hardware, highlighting a significant advancement in sustainable AI technologies.
Biologically Plausible Learning on Neuromorphic Hardware Architectures
Dec 29, 2022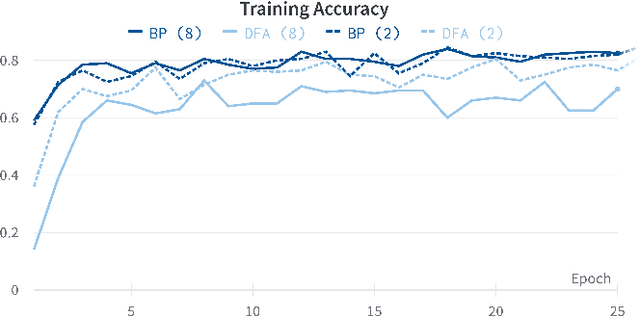
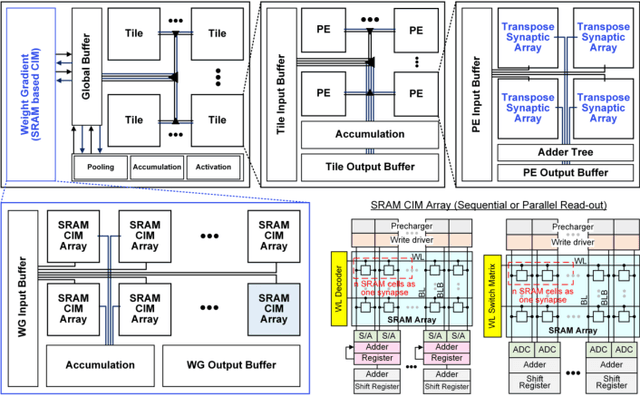
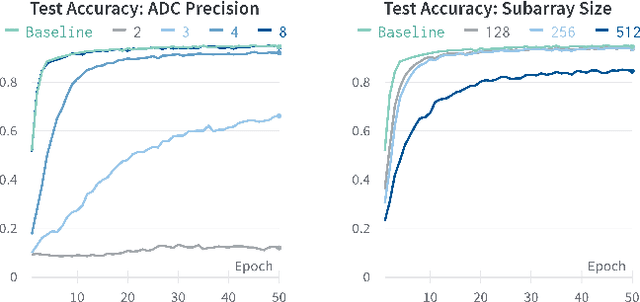
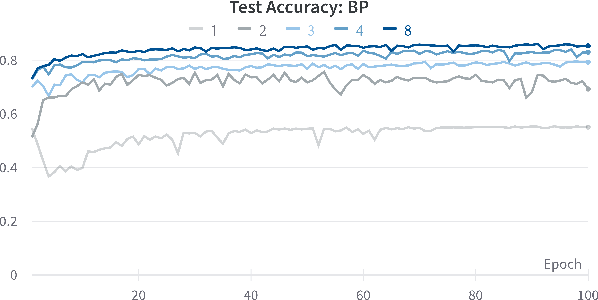
With an ever-growing number of parameters defining increasingly complex networks, Deep Learning has led to several breakthroughs surpassing human performance. As a result, data movement for these millions of model parameters causes a growing imbalance known as the memory wall. Neuromorphic computing is an emerging paradigm that confronts this imbalance by performing computations directly in analog memories. On the software side, the sequential Backpropagation algorithm prevents efficient parallelization and thus fast convergence. A novel method, Direct Feedback Alignment, resolves inherent layer dependencies by directly passing the error from the output to each layer. At the intersection of hardware/software co-design, there is a demand for developing algorithms that are tolerable to hardware nonidealities. Therefore, this work explores the interrelationship of implementing bio-plausible learning in-situ on neuromorphic hardware, emphasizing energy, area, and latency constraints. Using the benchmarking framework DNN+NeuroSim, we investigate the impact of hardware nonidealities and quantization on algorithm performance, as well as how network topologies and algorithm-level design choices can scale latency, energy and area consumption of a chip. To the best of our knowledge, this work is the first to compare the impact of different learning algorithms on Compute-In-Memory-based hardware and vice versa. The best results achieved for accuracy remain Backpropagation-based, notably when facing hardware imperfections. Direct Feedback Alignment, on the other hand, allows for significant speedup due to parallelization, reducing training time by a factor approaching N for N-layered networks.
Neuromorphic Algorithm-hardware Codesign for Temporal Pattern Learning
May 07, 2021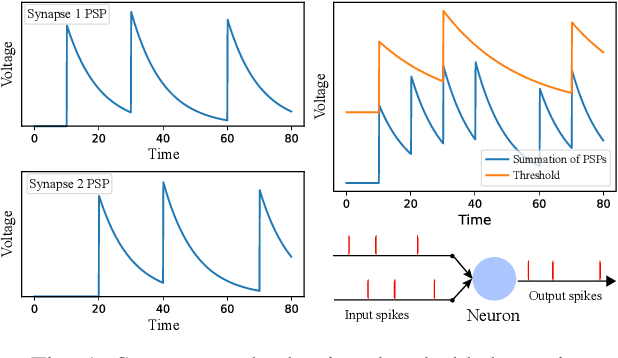
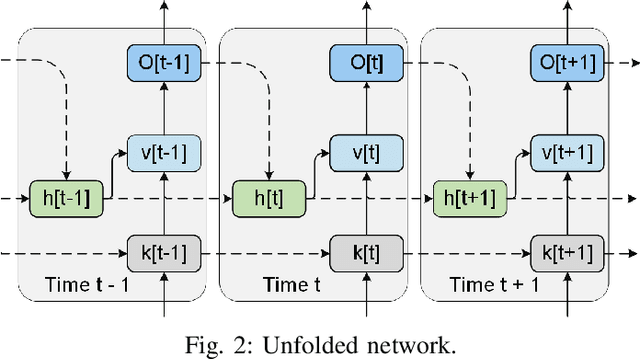
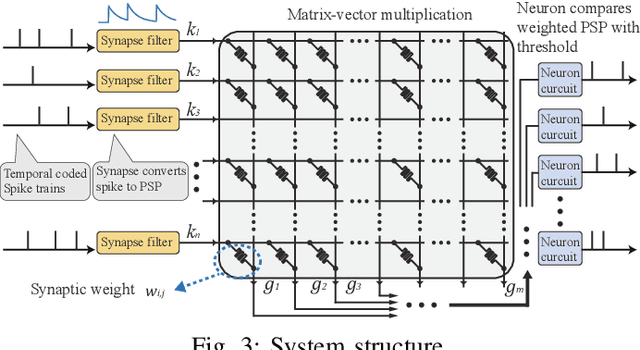
Neuromorphic computing and spiking neural networks (SNN) mimic the behavior of biological systems and have drawn interest for their potential to perform cognitive tasks with high energy efficiency. However, some factors such as temporal dynamics and spike timings prove critical for information processing but are often ignored by existing works, limiting the performance and applications of neuromorphic computing. On one hand, due to the lack of effective SNN training algorithms, it is difficult to utilize the temporal neural dynamics. Many existing algorithms still treat neuron activation statistically. On the other hand, utilizing temporal neural dynamics also poses challenges to hardware design. Synapses exhibit temporal dynamics, serving as memory units that hold historical information, but are often simplified as a connection with weight. Most current models integrate synaptic activations in some storage medium to represent membrane potential and institute a hard reset of membrane potential after the neuron emits a spike. This is done for its simplicity in hardware, requiring only a "clear" signal to wipe the storage medium, but destroys temporal information stored in the neuron. In this work, we derive an efficient training algorithm for Leaky Integrate and Fire neurons, which is capable of training a SNN to learn complex spatial temporal patterns. We achieved competitive accuracy on two complex datasets. We also demonstrate the advantage of our model by a novel temporal pattern association task. Codesigned with this algorithm, we have developed a CMOS circuit implementation for a memristor-based network of neuron and synapses which retains critical neural dynamics with reduced complexity. This circuit implementation of the neuron model is simulated to demonstrate its ability to react to temporal spiking patterns with an adaptive threshold.