 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractalCloud: A Fractal-Inspired Architecture for Efficient Large-Scale Point Cloud Processing
Nov 10, 2025Three-dimensional (3D) point clouds are increasingly used in applications such as autonomous driving, robotics, and virtual reality (VR). Point-based neural networks (PNNs) have demonstrated strong performance in point cloud analysis, originally targeting small-scale inputs. However, as PNNs evolve to process large-scale point clouds with hundreds of thousands of points, all-to-all computation and global memory access in point cloud processing introduce substantial overhead, causing $O(n^2)$ computational complexity and memory traffic where n is the number of points}. Existing accelerators, primarily optimized for small-scale workloads, overlook this challenge and scale poorly due to inefficient partitioning and non-parallel architectures. To address these issues, we propose FractalCloud, a fractal-inspired hardware architecture for efficient large-scale 3D point cloud processing. FractalCloud introduces two key optimizations: (1) a co-designed Fractal method for shape-aware and hardware-friendly partitioning, and (2) block-parallel point operations that decompose and parallelize all point operations. A dedicated hardware design with on-chip fractal and flexible parallelism further enables fully parallel processing within limited memory resources. Implemented in 28 nm technology as a chip layout with a core area of 1.5 $mm^2$, FractalCloud achieves 21.7x speedup and 27x energy reduction over state-of-the-art accelerators while maintaining network accuracy, demonstrating its scalability and efficiency for PNN inference.
Phi: Leveraging Pattern-based Hierarchical Sparsity for High-Efficiency Spiking Neural Networks
May 16, 2025Spiking Neural Networks (SNNs) are gaining attention for their energy efficiency and biological plausibility, utilizing 0-1 activation sparsity through spike-driven computation. While existing SNN accelerators exploit this sparsity to skip zero computations, they often overlook the unique distribution patterns inherent in binary activations. In this work, we observe that particular patterns exist in spike activations, which we can utilize to reduce the substantial computation of SNN models. Based on these findings, we propose a novel \textbf{pattern-based hierarchical sparsity} framework, termed \textbf{\textit{Phi}}, to optimize computation. \textit{Phi} introduces a two-level sparsity hierarchy: Level 1 exhibits vector-wise sparsity by representing activations with pre-defined patterns, allowing for offline pre-computation with weights and significantly reducing most runtime computation. Level 2 features element-wise sparsity by complementing the Level 1 matrix, using a highly sparse matrix to further reduce computation while maintaining accuracy. We present an algorithm-hardware co-design approach. Algorithmically, we employ a k-means-based pattern selection method to identify representative patterns and introduce a pattern-aware fine-tuning technique to enhance Level 2 sparsity. Architecturally, we design \textbf{\textit{Phi}}, a dedicated hardware architecture that efficiently processes the two levels of \textit{Phi} sparsity on the fly. Extensive experiments demonstrate that \textit{Phi} achieves a $3.45\times$ speedup and a $4.93\times$ improvement in energy efficiency compared to state-of-the-art SNN accelerators, showcasing the effectiveness of our framework in optimizing SNN computation.
Multi-label feature selection based on binary hashing learning and dynamic graph constraints
Mar 18, 2025



Multi-label learning poses significant challenges in extracting reliable supervisory signals from the label space. Existing approaches often employ continuous pseudo-labels to replace binary labels, improving supervisory information representation. However, these methods can introduce noise from irrelevant labels and lead to unreliable graph structures. To overcome these limitations, this study introduces a novel multi-label feature selection method called Binary Hashing and Dynamic Graph Constraint (BHDG), the first method to integrate binary hashing into multi-label learning. BHDG utilizes low-dimensional binary hashing codes as pseudo-labels to reduce noise and improve representation robustness. A dynamically constrained sample projection space is constructed based on the graph structure of these binary pseudo-labels, enhancing the reliability of the dynamic graph. To further enhance pseudo-label quality, BHDG incorporates label graph constraints and inner product minimization within the sample space. Additionally, an $l_{2,1}$-norm regularization term is added to the objective function to facilitate the feature selection process. The augmented Lagrangian multiplier (ALM) method is employed to optimize binary variables effectively. Comprehensive experiments on 10 benchmark datasets demonstrate that BHDG outperforms ten state-of-the-art methods across six evaluation metrics. BHDG achieves the highest overall performance ranking, surpassing the next-best method by an average of at least 2.7 ranks per metric, underscoring its effectiveness and robustness in multi-label feature selection.
Hamming Attention Distillation: Binarizing Keys and Queries for Efficient Long-Context Transformers
Feb 03, 2025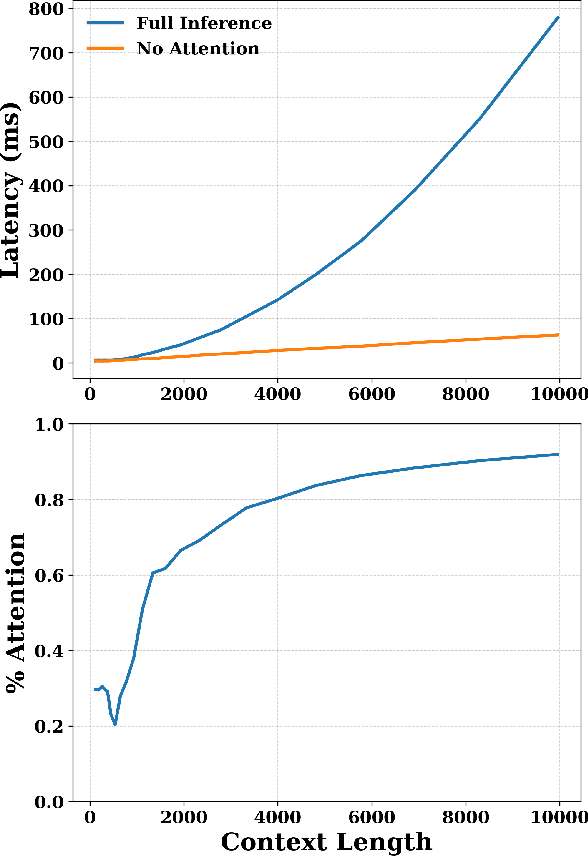
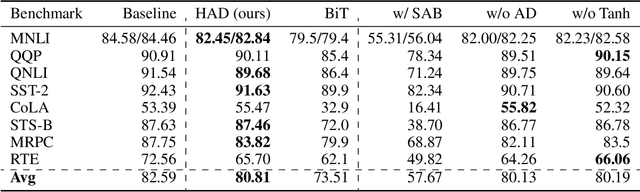
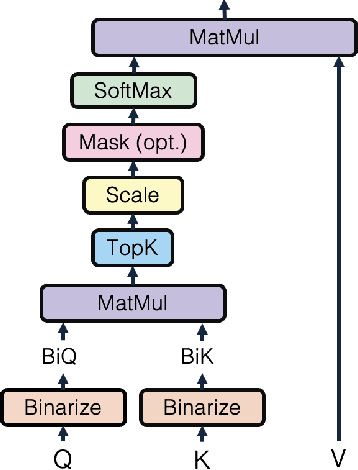
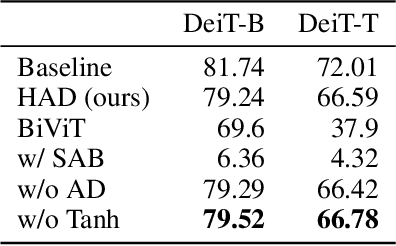
Pre-trained transformer models with extended context windows are notoriously expensive to run at scale, often limiting real-world deployment due to their high computational and memory requirements. In this paper, we introduce Hamming Attention Distillation (HAD), a novel framework that binarizes keys and queries in the attention mechanism to achieve significant efficiency gains. By converting keys and queries into {-1, +1} vectors and replacing dot-product operations with efficient Hamming distance computations, our method drastically reduces computational overhead. Additionally, we incorporate attention matrix sparsification to prune low-impact activations, which further reduces the cost of processing long-context sequences. \par Despite these aggressive compression strategies, our distilled approach preserves a high degree of representational power, leading to substantially improved accuracy compared to prior transformer binarization methods. We evaluate HAD on a range of tasks and models, including the GLUE benchmark, ImageNet, and QuALITY, demonstrating state-of-the-art performance among binarized Transformers while drastically reducing the computational costs of long-context inference. \par We implement HAD in custom hardware simulations, demonstrating superior performance characteristics compared to a custom hardware implementation of standard attention. HAD achieves just $\mathbf{1.78}\%$ performance losses on GLUE compared to $9.08\%$ in state-of-the-art binarization work, and $\mathbf{2.5}\%$ performance losses on ImageNet compared to $12.14\%$, all while targeting custom hardware with a $\mathbf{79}\%$ area reduction and $\mathbf{87}\%$ power reduction compared to its standard attention counterpart.
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
Jul 22, 2024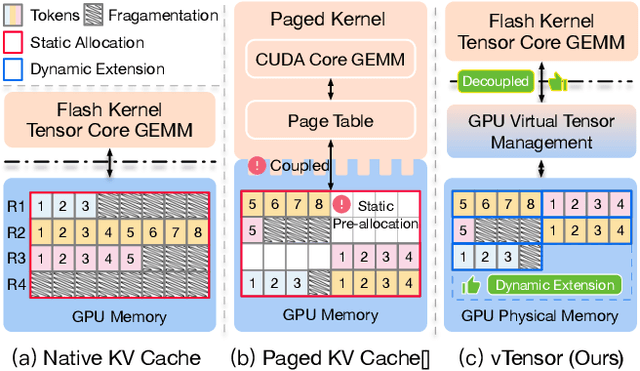

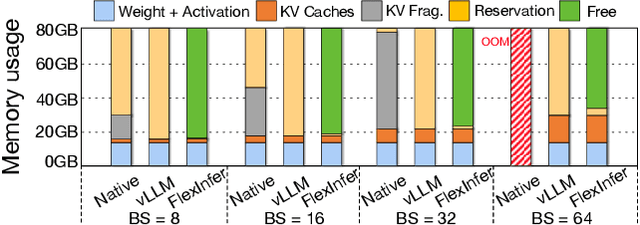
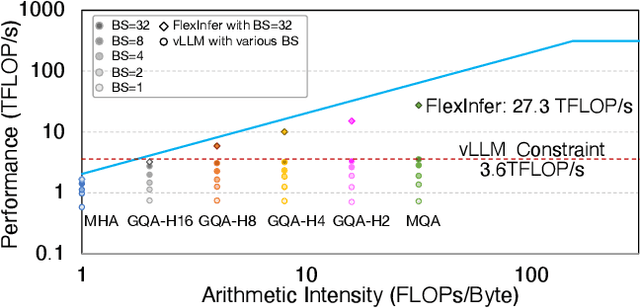
Large Language Models (LLMs) are widely used across various domains, processing millions of daily requests. This surge in demand poses significant challenges in optimizing throughput and latency while keeping costs manageable. The Key-Value (KV) cache, a standard method for retaining previous computations, makes LLM inference highly bounded by memory. While batching strategies can enhance performance, they frequently lead to significant memory fragmentation. Even though cutting-edge systems like vLLM mitigate KV cache fragmentation using paged Attention mechanisms, they still suffer from inefficient memory and computational operations due to the tightly coupled page management and computation kernels. This study introduces the vTensor, an innovative tensor structure for LLM inference based on GPU virtual memory management (VMM). vTensor addresses existing limitations by decoupling computation from memory defragmentation and offering dynamic extensibility. Our framework employs a CPU-GPU heterogeneous approach, ensuring efficient, fragmentation-free memory management while accommodating various computation kernels across different LLM architectures. Experimental results indicate that vTensor achieves an average speedup of 1.86x across different models, with up to 2.42x in multi-turn chat scenarios. Additionally, vTensor provides average speedups of 2.12x and 3.15x in kernel evaluation, reaching up to 3.92x and 3.27x compared to SGLang Triton prefix-prefilling kernels and vLLM paged Attention kernel, respectively. Furthermore, it frees approximately 71.25% (57GB) of memory on the NVIDIA A100 GPU compared to vLLM, enabling more memory-intensive workloads.
A novel feature selection framework for incomplete data
Dec 07, 2023Feature selection on incomplete datasets is an exceptionally challenging task. Existing methods address this challenge by first employing imputation methods to complete the incomplete data and then conducting feature selection based on the imputed data. Since imputation and feature selection are entirely independent steps, the importance of features cannot be considered during imputation. However, in real-world scenarios or datasets, different features have varying degrees of importance. To address this, we propose a novel incomplete data feature selection framework that considers feature importance. The framework mainly consists of two alternating iterative stages: the M-stage and the W-stage. In the M-stage, missing values are imputed based on a given feature importance vector and multiple initial imputation results. In the W-stage, an improved reliefF algorithm is employed to learn the feature importance vector based on the imputed data. Specifically, the feature importance vector obtained in the current iteration of the W-stage serves as input for the next iteration of the M-stage. Experimental results on both artificially generated and real incomplete datasets demonstrate that the proposed method outperforms other approaches significantly.
Iterative missing value imputation based on feature importance
Nov 14, 2023Many datasets suffer from missing values due to various reasons,which not only increases the processing difficulty of related tasks but also reduces the accuracy of classification. To address this problem, the mainstream approach is to use missing value imputation to complete the dataset. Existing imputation methods estimate the missing parts based on the observed values in the original feature space, and they treat all features as equally important during data completion, while in fact different features have different importance. Therefore, we have designed an imputation method that considers feature importance. This algorithm iteratively performs matrix completion and feature importance learning, and specifically, matrix completion is based on a filling loss that incorporates feature importance. Our experimental analysis involves three types of datasets: synthetic datasets with different noisy features and missing values, real-world datasets with artificially generated missing values, and real-world datasets originally containing missing values. The results on these datasets consistently show that the proposed method outperforms the existing five imputation algorithms.To the best of our knowledge, this is the first work that considers feature importance in the imputation model.
Accelerating Generic Graph Neural Networks via Architecture, Compiler, Partition Method Co-Design
Aug 16, 2023Graph neural networks (GNNs) have shown significant accuracy improvements in a variety of graph learning domains, sparking considerable research interest. To translate these accuracy improvements into practical applications, it is essential to develop high-performance and efficient hardware acceleration for GNN models. However, designing GNN accelerators faces two fundamental challenges: the high bandwidth requirement of GNN models and the diversity of GNN models. Previous works have addressed the first challenge by using more expensive memory interfaces to achieve higher bandwidth. For the second challenge, existing works either support specific GNN models or have generic designs with poor hardware utilization. In this work, we tackle both challenges simultaneously. First, we identify a new type of partition-level operator fusion, which we utilize to internally reduce the high bandwidth requirement of GNNs. Next, we introduce partition-level multi-threading to schedule the concurrent processing of graph partitions, utilizing different hardware resources. To further reduce the extra on-chip memory required by multi-threading, we propose fine-grained graph partitioning to generate denser graph partitions. Importantly, these three methods make no assumptions about the targeted GNN models, addressing the challenge of model variety. We implement these methods in a framework called SwitchBlade, consisting of a compiler, a graph partitioner, and a hardware accelerator. Our evaluation demonstrates that SwitchBlade achieves an average speedup of $1.85\times$ and energy savings of $19.03\times$ compared to the NVIDIA V100 GPU. Additionally, SwitchBlade delivers performance comparable to state-of-the-art specialized accelerators.
AdaptGear: Accelerating GNN Training via Adaptive Subgraph-Level Kernels on GPUs
May 27, 2023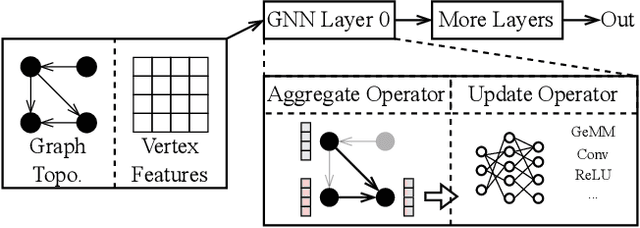
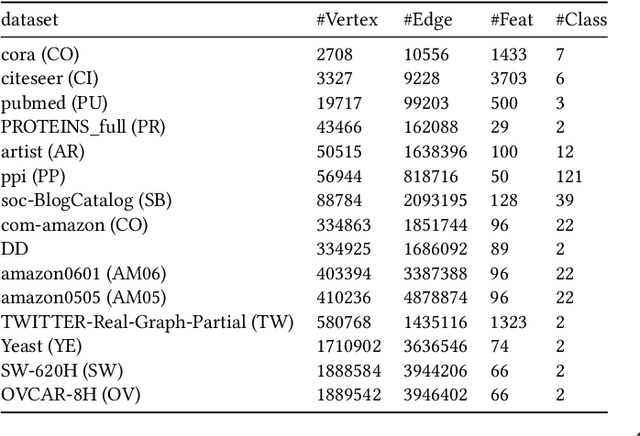
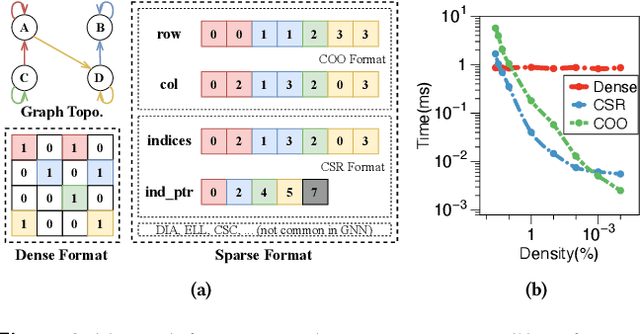

Graph neural networks (GNNs) are powerful tools for exploring and learning from graph structures and features. As such, achieving high-performance execution for GNNs becomes crucially important. Prior works have proposed to explore the sparsity (i.e., low density) in the input graph to accelerate GNNs, which uses the full-graph-level or block-level sparsity format. We show that they fail to balance the sparsity benefit and kernel execution efficiency. In this paper, we propose a novel system, referred to as AdaptGear, that addresses the challenge of optimizing GNNs performance by leveraging kernels tailored to the density characteristics at the subgraph level. Meanwhile, we also propose a method that dynamically chooses the optimal set of kernels for a given input graph. Our evaluation shows that AdaptGear can achieve a significant performance improvement, up to $6.49 \times$ ($1.87 \times$ on average), over the state-of-the-art works on two mainstream NVIDIA GPUs across various datasets.