 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFFR: Spatial-Frequency Feature Reconstruction for Multispectral Aerial Object Detection
Nov 17, 2025Recent multispectral object detection methods have primarily focused on spatial-domain feature fusion based on CNNs or Transformers, while the potential of frequency-domain feature remains underexplored. In this work, we propose a novel Spatial and Frequency Feature Reconstruction method (SFFR) method, which leverages the spatial-frequency feature representation mechanisms of the Kolmogorov-Arnold Network (KAN) to reconstruct complementary representations in both spatial and frequency domains prior to feature fusion. The core components of SFFR are the proposed Frequency Component Exchange KAN (FCEKAN) module and Multi-Scale Gaussian KAN (MSGKAN) module. The FCEKAN introduces an innovative selective frequency component exchange strategy that effectively enhances the complementarity and consistency of cross-modal features based on the frequency feature of RGB and IR images. The MSGKAN module demonstrates excellent nonlinear feature modeling capability in the spatial domain. By leveraging multi-scale Gaussian basis functions, it effectively captures the feature variations caused by scale changes at different UAV flight altitudes, significantly enhancing the model's adaptability and robustness to scale variations. It is experimentally validated that our proposed FCEKAN and MSGKAN modules are complementary and can effectively capture the frequency and spatial semantic features respectively for better feature fusion. Extensive experiments on the SeaDroneSee, DroneVehicle and DVTOD datasets demonstrate the superior performance and significant advantages of the proposed method in UAV multispectral object perception task. Code will be available at https://github.com/qchenyu1027/SFFR.
IRDFusion: Iterative Relation-Map Difference guided Feature Fusion for Multispectral Object Detection
Sep 11, 2025Current multispectral object detection methods often retain extraneous background or noise during feature fusion, limiting perceptual performance.To address this, we propose an innovative feature fusion framework based on cross-modal feature contrastive and screening strategy, diverging from conventional approaches. The proposed method adaptively enhances salient structures by fusing object-aware complementary cross-modal features while suppressing shared background interference.Our solution centers on two novel, specially designed modules: the Mutual Feature Refinement Module (MFRM) and the Differential Feature Feedback Module (DFFM). The MFRM enhances intra- and inter-modal feature representations by modeling their relationships, thereby improving cross-modal alignment and discriminative power.Inspired by feedback differential amplifiers, the DFFM dynamically computes inter-modal differential features as guidance signals and feeds them back to the MFRM, enabling adaptive fusion of complementary information while suppressing common-mode noise across modalities. To enable robust feature learning, the MFRM and DFFM are integrated into a unified framework, which is formally formulated as an Iterative Relation-Map Differential Guided Feature Fusion mechanism, termed IRDFusion. IRDFusion enables high-quality cross-modal fusion by progressively amplifying salient relational signals through iterative feedback, while suppressing feature noise, leading to significant performance gains.In extensive experiments on FLIR, LLVIP and M$^3$FD datasets, IRDFusion achieves state-of-the-art performance and consistently outperforms existing methods across diverse challenging scenarios, demonstrating its robustness and effectiveness. Code will be available at https://github.com/61s61min/IRDFusion.git.
PropVG: End-to-End Proposal-Driven Visual Grounding with Multi-Granularity Discrimination
Sep 05, 2025Recent advances in visual grounding have largely shifted away from traditional proposal-based two-stage frameworks due to their inefficiency and high computational complexity, favoring end-to-end direct reference paradigms. However, these methods rely exclusively on the referred target for supervision, overlooking the potential benefits of prominent prospective targets. Moreover, existing approaches often fail to incorporate multi-granularity discrimination, which is crucial for robust object identification in complex scenarios. To address these limitations, we propose PropVG, an end-to-end proposal-based framework that, to the best of our knowledge, is the first to seamlessly integrate foreground object proposal generation with referential object comprehension without requiring additional detectors. Furthermore, we introduce a Contrastive-based Refer Scoring (CRS) module, which employs contrastive learning at both sentence and word levels to enhance the capability in understanding and distinguishing referred objects. Additionally, we design a Multi-granularity Target Discrimination (MTD) module that fuses object- and semantic-level information to improve the recognition of absent targets. Extensive experiments on gRefCOCO (GREC/GRES), Ref-ZOM, R-RefCOCO, and RefCOCO (REC/RES) benchmarks demonstrate the effectiveness of PropVG. The codes and models are available at https://github.com/Dmmm1997/PropVG.
DeRIS: Decoupling Perception and Cognition for Enhanced Referring Image Segmentation through Loopback Synergy
Jul 02, 2025Referring Image Segmentation (RIS) is a challenging task that aims to segment objects in an image based on natural language expressions. While prior studies have predominantly concentrated on improving vision-language interactions and achieving fine-grained localization, a systematic analysis of the fundamental bottlenecks in existing RIS frameworks remains underexplored. To bridge this gap, we propose DeRIS, a novel framework that decomposes RIS into two key components: perception and cognition. This modular decomposition facilitates a systematic analysis of the primary bottlenecks impeding RIS performance. Our findings reveal that the predominant limitation lies not in perceptual deficiencies, but in the insufficient multi-modal cognitive capacity of current models. To mitigate this, we propose a Loopback Synergy mechanism, which enhances the synergy between the perception and cognition modules, thereby enabling precise segmentation while simultaneously improving robust image-text comprehension. Additionally, we analyze and introduce a simple non-referent sample conversion data augmentation to address the long-tail distribution issue related to target existence judgement in general scenarios. Notably, DeRIS demonstrates inherent adaptability to both non- and multi-referents scenarios without requiring specialized architectural modifications, enhancing its general applicability. The codes and models are available at https://github.com/Dmmm1997/DeRIS.
Vision Remember: Alleviating Visual Forgetting in Efficient MLLM with Vision Feature Resample
Jun 04, 2025In this work, we study the Efficient Multimodal Large Language Model. Redundant vision tokens consume a significant amount of computational memory and resources. Therefore, many previous works compress them in the Vision Projector to reduce the number of vision tokens. However, simply compressing in the Vision Projector can lead to the loss of visual information, especially for tasks that rely on fine-grained spatial relationships, such as OCR and Chart \& Table Understanding. To address this problem, we propose Vision Remember, which is inserted between the LLM decoder layers to allow vision tokens to re-memorize vision features. Specifically, we retain multi-level vision features and resample them with the vision tokens that have interacted with the text token. During the resampling process, each vision token only attends to a local region in vision features, which is referred to as saliency-enhancing local attention. Saliency-enhancing local attention not only improves computational efficiency but also captures more fine-grained contextual information and spatial relationships within the region. Comprehensive experiments on multiple visual understanding benchmarks validate the effectiveness of our method when combined with various Efficient Vision Projectors, showing performance gains without sacrificing efficiency. Based on Vision Remember, LLaVA-VR with only 2B parameters is also superior to previous representative MLLMs such as Tokenpacker-HD-7B and DeepSeek-VL-7B.
Improving underwater semantic segmentation with underwater image quality attention and muti-scale aggregation attention
Mar 30, 2025Underwater image understanding is crucial for both submarine navigation and seabed exploration. However, the low illumination in underwater environments degrades the imaging quality, which in turn seriously deteriorates the performance of underwater semantic segmentation, particularly for outlining the object region boundaries. To tackle this issue, we present UnderWater SegFormer (UWSegFormer), a transformer-based framework for semantic segmentation of low-quality underwater images. Firstly, we propose the Underwater Image Quality Attention (UIQA) module. This module enhances the representation of highquality semantic information in underwater image feature channels through a channel self-attention mechanism. In order to address the issue of loss of imaging details due to the underwater environment, the Multi-scale Aggregation Attention(MAA) module is proposed. This module aggregates sets of semantic features at different scales by extracting discriminative information from high-level features,thus compensating for the semantic loss of detail in underwater objects. Finally, during training, we introduce Edge Learning Loss (ELL) in order to enhance the model's learning of underwater object edges and improve the model's prediction accuracy. Experiments conducted on the SUIM and DUT-USEG (DUT) datasets have demonstrated that the proposed method has advantages in terms of segmentation completeness, boundary clarity, and subjective perceptual details when compared to SOTA methods. In addition, the proposed method achieves the highest mIoU of 82.12 and 71.41 on the SUIM and DUT datasets, respectively. Code will be available at https://github.com/SAWRJJ/UWSegFormer.
Precise GPS-Denied UAV Self-Positioning via Context-Enhanced Cross-View Geo-Localization
Feb 17, 2025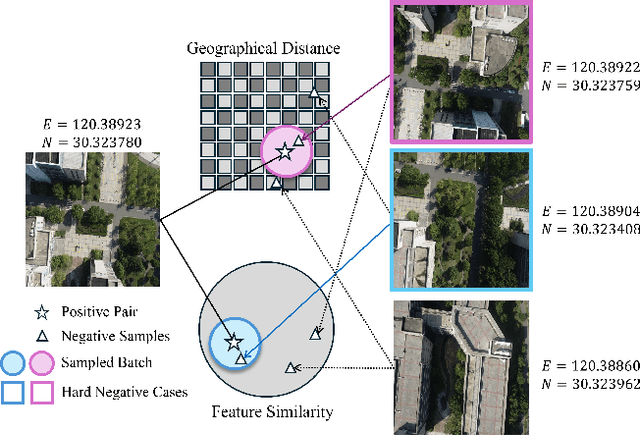
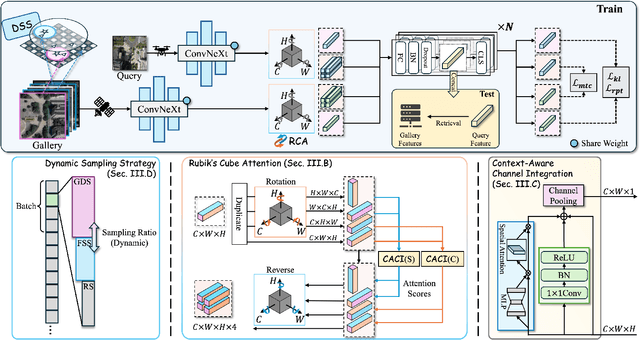

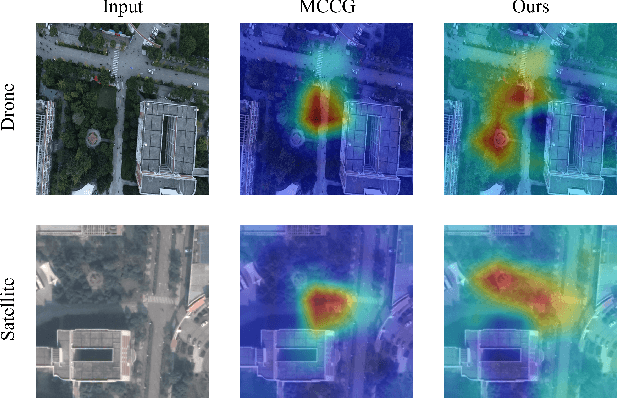
Image retrieval has been employed as a robust complementary technique to address the challenge of Unmanned Aerial Vehicles (UAVs) self-positioning. However, most existing methods primarily focus on localizing objects captured by UAVs through complex part-based representations, often overlooking the unique challenges associated with UAV self-positioning, such as fine-grained spatial discrimination requirements and dynamic scene variations. To address the above issues, we propose the Context-Enhanced method for precise UAV Self-Positioning (CEUSP), specifically designed for UAV self-positioning tasks. CEUSP integrates a Dynamic Sampling Strategy (DSS) to efficiently select optimal negative samples, while the Rubik's Cube Attention (RCA) module, combined with the Context-Aware Channel Integration (CACI) module, enhances feature representation and discrimination by exploiting interdimensional interactions, inspired by the rotational mechanics of a Rubik's Cube. Extensive experimental validate the effectiveness of the proposed method, demonstrating notable improvements in feature representation and UAV self-positioning accuracy within complex urban environments. Our approach achieves state-of-the-art performance on the DenseUAV dataset, which is specifically designed for dense urban contexts, and also delivers competitive results on the widely recognized University-1652 benchmark.
Multi-task Visual Grounding with Coarse-to-Fine Consistency Constraints
Jan 12, 2025
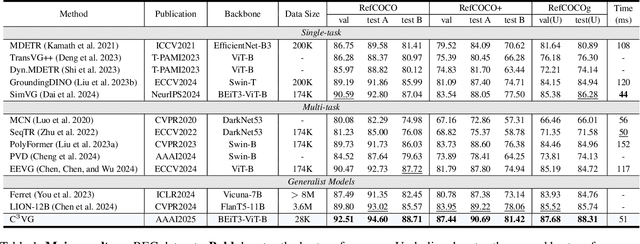

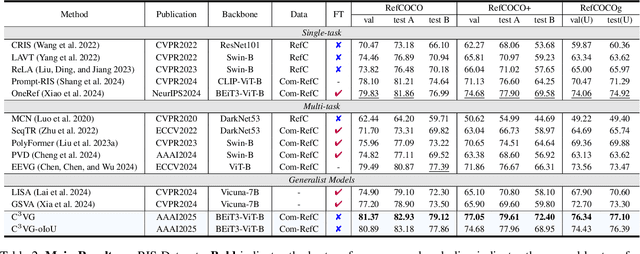
Multi-task visual grounding involves the simultaneous execution of localization and segmentation in images based on textual expressions. The majority of advanced methods predominantly focus on transformer-based multimodal fusion, aiming to extract robust multimodal representations. However, ambiguity between referring expression comprehension (REC) and referring image segmentation (RIS) is error-prone, leading to inconsistencies between multi-task predictions. Besides, insufficient multimodal understanding directly contributes to biased target perception. To overcome these challenges, we propose a Coarse-to-fine Consistency Constraints Visual Grounding architecture ($\text{C}^3\text{VG}$), which integrates implicit and explicit modeling approaches within a two-stage framework. Initially, query and pixel decoders are employed to generate preliminary detection and segmentation outputs, a process referred to as the Rough Semantic Perception (RSP) stage. These coarse predictions are subsequently refined through the proposed Mask-guided Interaction Module (MIM) and a novel explicit bidirectional consistency constraint loss to ensure consistent representations across tasks, which we term the Refined Consistency Interaction (RCI) stage. Furthermore, to address the challenge of insufficient multimodal understanding, we leverage pre-trained models based on visual-linguistic fusion representations. Empirical evaluations on the RefCOCO, RefCOCO+, and RefCOCOg datasets demonstrate the efficacy and soundness of $\text{C}^3\text{VG}$, which significantly outperforms state-of-the-art REC and RIS methods by a substantial margin. Code and model will be available at \url{https://github.com/Dmmm1997/C3VG}.
Uncertainty Quantification in Stereo Matching
Dec 24, 2024



Stereo matching plays a crucial role in various applications, where understanding uncertainty can enhance both safety and reliability. Despite this, the estimation and analysis of uncertainty in stereo matching have been largely overlooked. Previous works often provide limited interpretations of uncertainty and struggle to separate it effectively into data (aleatoric) and model (epistemic) components. This disentanglement is essential, as it allows for a clearer understanding of the underlying sources of error, enhancing both prediction confidence and decision-making processes. In this paper, we propose a new framework for stereo matching and its uncertainty quantification. We adopt Bayes risk as a measure of uncertainty and estimate data and model uncertainty separately. Experiments are conducted on four stereo benchmarks, and the results demonstrate that our method can estimate uncertainty accurately and efficiently. Furthermore, we apply our uncertainty method to improve prediction accuracy by selecting data points with small uncertainties, which reflects the accuracy of our estimated uncertainty. The codes are publicly available at https://github.com/RussRobin/Uncertainty.
SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
Sep 26, 2024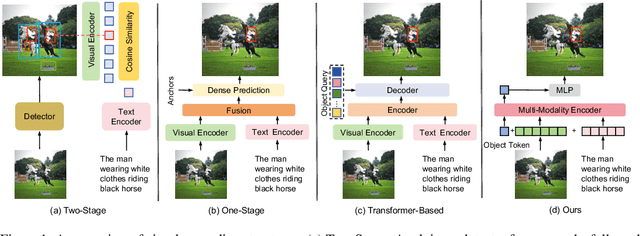
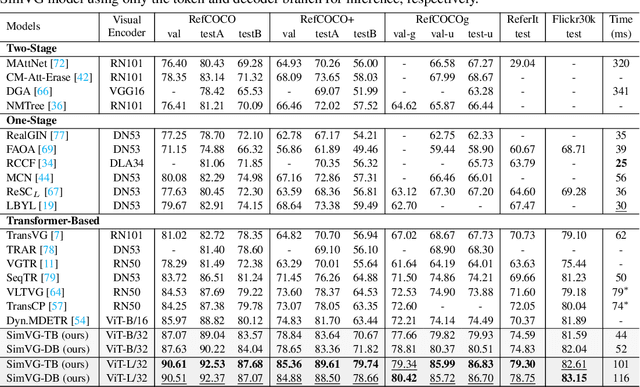
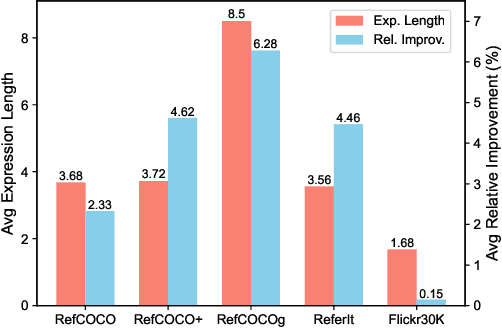
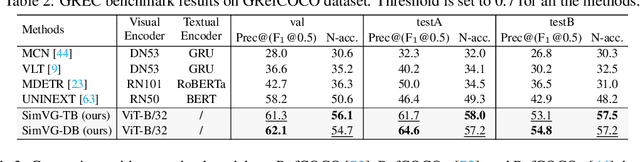
Visual grounding is a common vision task that involves grounding descriptive sentences to the corresponding regions of an image. Most existing methods use independent image-text encoding and apply complex hand-crafted modules or encoder-decoder architectures for modal interaction and query reasoning. However, their performance significantly drops when dealing with complex textual expressions. This is because the former paradigm only utilizes limited downstream data to fit the multi-modal feature fusion. Therefore, it is only effective when the textual expressions are relatively simple. In contrast, given the wide diversity of textual expressions and the uniqueness of downstream training data, the existing fusion module, which extracts multimodal content from a visual-linguistic context, has not been fully investigated. In this paper, we present a simple yet robust transformer-based framework, SimVG, for visual grounding. Specifically, we decouple visual-linguistic feature fusion from downstream tasks by leveraging existing multimodal pre-trained models and incorporating additional object tokens to facilitate deep integration of downstream and pre-training tasks. Furthermore, we design a dynamic weight-balance distillation method in the multi-branch synchronous learning process to enhance the representation capability of the simpler branch. This branch only consists of a lightweight MLP, which simplifies the structure and improves reasoning speed. Experiments on six widely used VG datasets, i.e., RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO, demonstrate the superiority of SimVG. Finally, the proposed method not only achieves improvements in efficiency and convergence speed but also attains new state-of-the-art performance on these benchmarks. Codes and models will be available at \url{https://github.com/Dmmm1997/SimVG}.