 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving
Mar 25, 2026We introduce Latent-WAM, an efficient end-to-end autonomous driving framework that achieves strong trajectory planning through spatially-aware and dynamics-informed latent world representations. Existing world-model-based planners suffer from inadequately compressed representations, limited spatial understanding, and underutilized temporal dynamics, resulting in sub-optimal planning under constrained data and compute budgets. Latent-WAM addresses these limitations with two core modules: a Spatial-Aware Compressive World Encoder (SCWE) that distills geometric knowledge from a foundation model and compresses multi-view images into compact scene tokens via learnable queries, and a Dynamic Latent World Model (DLWM) that employs a causal Transformer to autoregressively predict future world status conditioned on historical visual and motion representations. Extensive experiments on NAVSIM v2 and HUGSIM demonstrate new state-of-the-art results: 89.3 EPDMS on NAVSIM v2 and 28.9 HD-Score on HUGSIM, surpassing the best prior perception-free method by 3.2 EPDMS with significantly less training data and a compact 104M-parameter model.
TakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025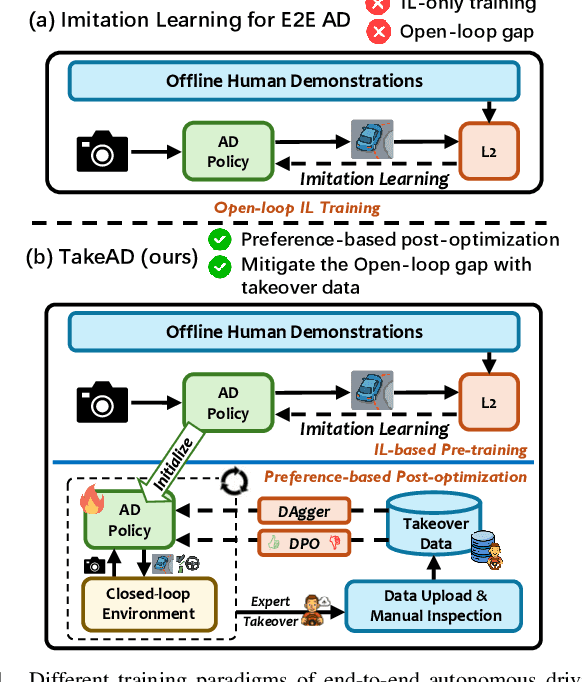
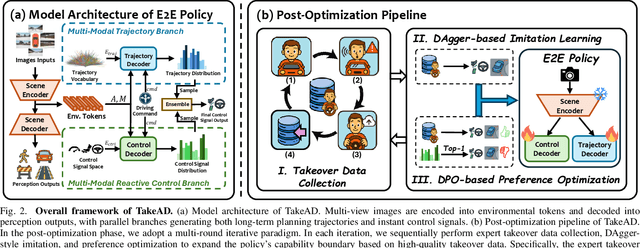
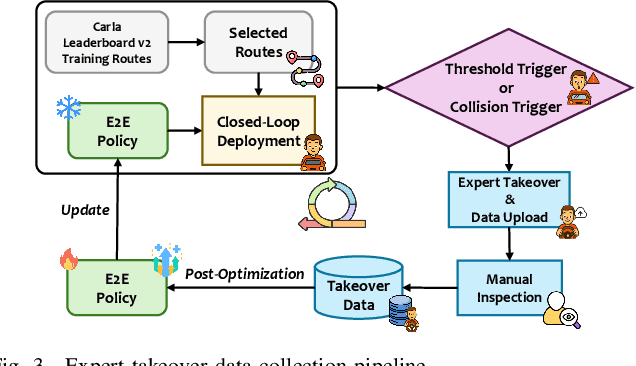
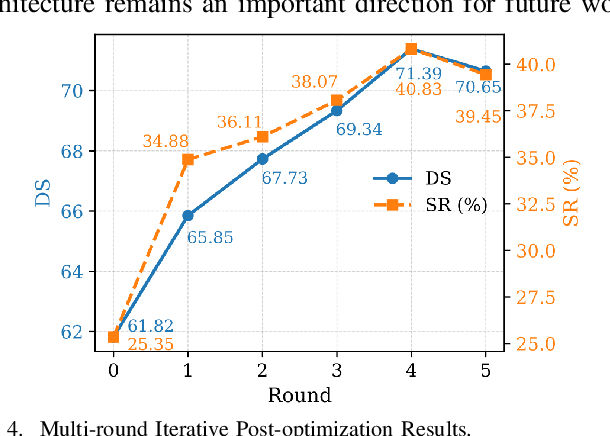
Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
Uni$^2$Det: Unified and Universal Framework for Prompt-Guided Multi-dataset 3D Detection
Sep 30, 2024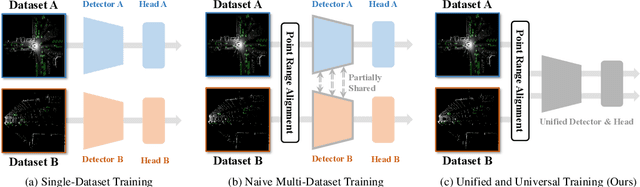
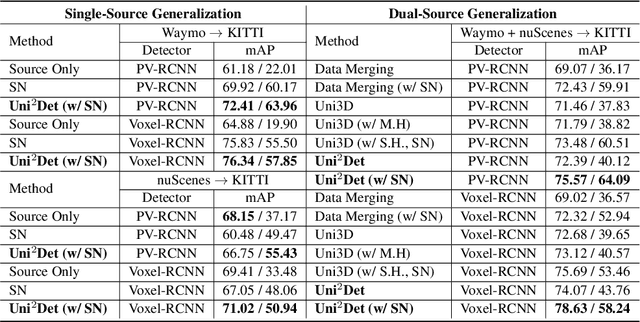
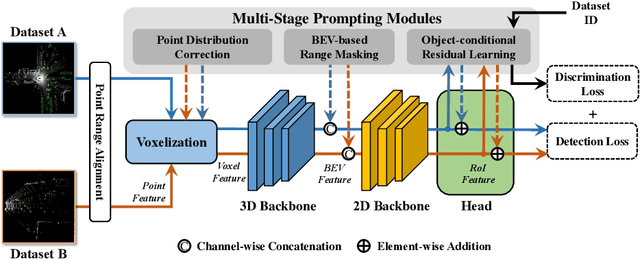
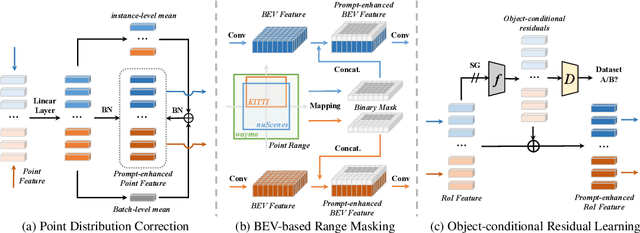
We present Uni$^2$Det, a brand new framework for unified and universal multi-dataset training on 3D detection, enabling robust performance across diverse domains and generalization to unseen domains. Due to substantial disparities in data distribution and variations in taxonomy across diverse domains, training such a detector by simply merging datasets poses a significant challenge. Motivated by this observation, we introduce multi-stage prompting modules for multi-dataset 3D detection, which leverages prompts based on the characteristics of corresponding datasets to mitigate existing differences. This elegant design facilitates seamless plug-and-play integration within various advanced 3D detection frameworks in a unified manner, while also allowing straightforward adaptation for universal applicability across datasets. Experiments are conducted across multiple dataset consolidation scenarios involving KITTI, Waymo, and nuScenes, demonstrating that our Uni$^2$Det outperforms existing methods by a large margin in multi-dataset training. Notably, results on zero-shot cross-dataset transfer validate the generalization capability of our proposed method.
Make Your ViT-based Multi-view 3D Detectors Faster via Token Compression
Sep 01, 2024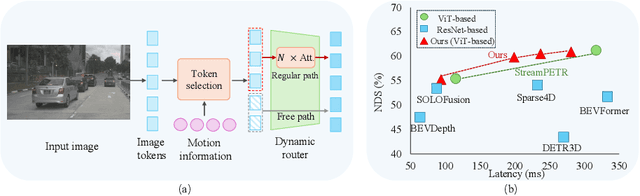

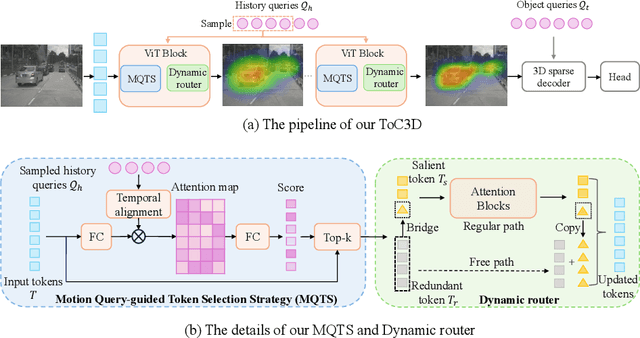
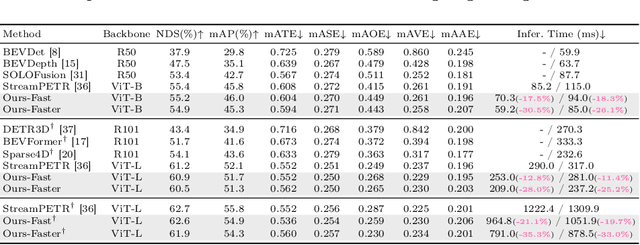
Slow inference speed is one of the most crucial concerns for deploying multi-view 3D detectors to tasks with high real-time requirements like autonomous driving. Although many sparse query-based methods have already attempted to improve the efficiency of 3D detectors, they neglect to consider the backbone, especially when using Vision Transformers (ViT) for better performance. To tackle this problem, we explore the efficient ViT backbones for multi-view 3D detection via token compression and propose a simple yet effective method called TokenCompression3D (ToC3D). By leveraging history object queries as foreground priors of high quality, modeling 3D motion information in them, and interacting them with image tokens through the attention mechanism, ToC3D can effectively determine the magnitude of information densities of image tokens and segment the salient foreground tokens. With the introduced dynamic router design, ToC3D can weigh more computing resources to important foreground tokens while compressing the information loss, leading to a more efficient ViT-based multi-view 3D detector. Extensive results on the large-scale nuScenes dataset show that our method can nearly maintain the performance of recent SOTA with up to 30% inference speedup, and the improvements are consistent after scaling up the ViT and input resolution. The code will be made at https://github.com/DYZhang09/ToC3D.
EasyChauffeur: A Baseline Advancing Simplicity and Efficiency on Waymax
Aug 29, 2024



Recent advancements in deep-learning-based driving planners have primarily focused on elaborate network engineering, yielding limited improvements. This paper diverges from conventional approaches by exploring three fundamental yet underinvestigated aspects: training policy, data efficiency, and evaluation robustness. We introduce EasyChauffeur, a reproducible and effective planner for both imitation learning (IL) and reinforcement learning (RL) on Waymax, a GPU-accelerated simulator. Notably, our findings indicate that the incorporation of on-policy RL significantly boosts performance and data efficiency. To further enhance this efficiency, we propose SNE-Sampling, a novel method that selectively samples data from the encoder's latent space, substantially improving EasyChauffeur's performance with RL. Additionally, we identify a deficiency in current evaluation methods, which fail to accurately assess the robustness of different planners due to significant performance drops from minor changes in the ego vehicle's initial state. In response, we propose Ego-Shifting, a new evaluation setting for assessing planners' robustness. Our findings advocate for a shift from a primary focus on network architectures to adopting a holistic approach encompassing training strategies, data efficiency, and robust evaluation methods.
LION: Linear Group RNN for 3D Object Detection in Point Clouds
Jul 25, 2024



The benefit of transformers in large-scale 3D point cloud perception tasks, such as 3D object detection, is limited by their quadratic computation cost when modeling long-range relationships. In contrast, linear RNNs have low computational complexity and are suitable for long-range modeling. Toward this goal, we propose a simple and effective window-based framework built on LInear grOup RNN (i.e., perform linear RNN for grouped features) for accurate 3D object detection, called LION. The key property is to allow sufficient feature interaction in a much larger group than transformer-based methods. However, effectively applying linear group RNN to 3D object detection in highly sparse point clouds is not trivial due to its limitation in handling spatial modeling. To tackle this problem, we simply introduce a 3D spatial feature descriptor and integrate it into the linear group RNN operators to enhance their spatial features rather than blindly increasing the number of scanning orders for voxel features. To further address the challenge in highly sparse point clouds, we propose a 3D voxel generation strategy to densify foreground features thanks to linear group RNN as a natural property of auto-regressive models. Extensive experiments verify the effectiveness of the proposed components and the generalization of our LION on different linear group RNN operators including Mamba, RWKV, and RetNet. Furthermore, it is worth mentioning that our LION-Mamba achieves state-of-the-art on Waymo, nuScenes, Argoverse V2, and ONCE dataset. Last but not least, our method supports kinds of advanced linear RNN operators (e.g., RetNet, RWKV, Mamba, xLSTM and TTT) on small but popular KITTI dataset for a quick experience with our linear RNN-based framework.
Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection
Jul 22, 2024



Camera and LiDAR serve as informative sensors for accurate and robust autonomous driving systems. However, these sensors often exhibit heterogeneous natures, resulting in distributional modality gaps that present significant challenges for fusion. To address this, a robust fusion technique is crucial, particularly for enhancing 3D object detection. In this paper, we introduce a dynamic adjustment technology aimed at aligning modal distributions and learning effective modality representations to enhance the fusion process. Specifically, we propose a triphase domain aligning module. This module adjusts the feature distributions from both the camera and LiDAR, bringing them closer to the ground truth domain and minimizing differences. Additionally, we explore improved representation acquisition methods for dynamic fusion, which includes modal interaction and specialty enhancement. Finally, an adaptive learning technique that merges the semantics and geometry information for dynamical instance optimization. Extensive experiments in the nuScenes dataset present competitive performance with state-of-the-art approaches. Our code will be released in the future.
SEED: A Simple and Effective 3D DETR in Point Clouds
Jul 15, 2024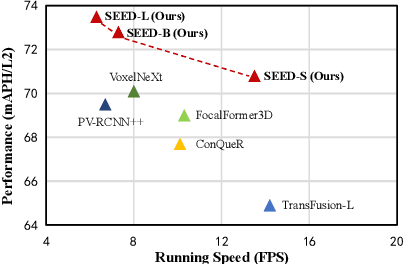
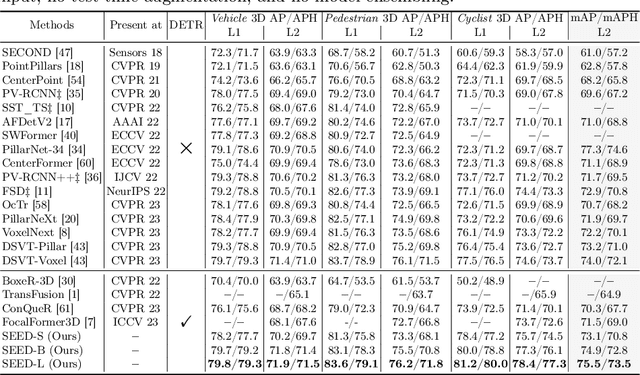
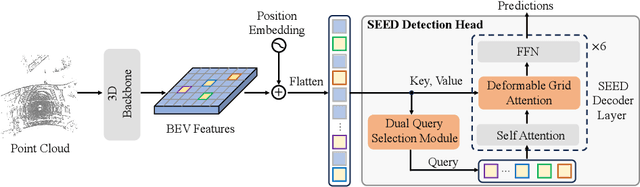
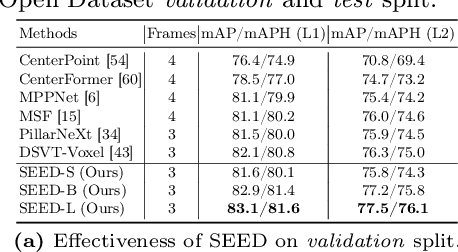
Recently, detection transformers (DETRs) have gradually taken a dominant position in 2D detection thanks to their elegant framework. However, DETR-based detectors for 3D point clouds are still difficult to achieve satisfactory performance. We argue that the main challenges are twofold: 1) How to obtain the appropriate object queries is challenging due to the high sparsity and uneven distribution of point clouds; 2) How to implement an effective query interaction by exploiting the rich geometric structure of point clouds is not fully explored. To this end, we propose a simple and effective 3D DETR method (SEED) for detecting 3D objects from point clouds, which involves a dual query selection (DQS) module and a deformable grid attention (DGA) module. More concretely, to obtain appropriate queries, DQS first ensures a high recall to retain a large number of queries by the predicted confidence scores and then further picks out high-quality queries according to the estimated quality scores. DGA uniformly divides each reference box into grids as the reference points and then utilizes the predicted offsets to achieve a flexible receptive field, allowing the network to focus on relevant regions and capture more informative features. Extensive ablation studies on DQS and DGA demonstrate its effectiveness. Furthermore, our SEED achieves state-of-the-art detection performance on both the large-scale Waymo and nuScenes datasets, illustrating the superiority of our proposed method. The code is available at https://github.com/happinesslz/SEED
OPEN: Object-wise Position Embedding for Multi-view 3D Object Detection
Jul 15, 2024



Accurate depth information is crucial for enhancing the performance of multi-view 3D object detection. Despite the success of some existing multi-view 3D detectors utilizing pixel-wise depth supervision, they overlook two significant phenomena: 1) the depth supervision obtained from LiDAR points is usually distributed on the surface of the object, which is not so friendly to existing DETR-based 3D detectors due to the lack of the depth of 3D object center; 2) for distant objects, fine-grained depth estimation of the whole object is more challenging. Therefore, we argue that the object-wise depth (or 3D center of the object) is essential for accurate detection. In this paper, we propose a new multi-view 3D object detector named OPEN, whose main idea is to effectively inject object-wise depth information into the network through our proposed object-wise position embedding. Specifically, we first employ an object-wise depth encoder, which takes the pixel-wise depth map as a prior, to accurately estimate the object-wise depth. Then, we utilize the proposed object-wise position embedding to encode the object-wise depth information into the transformer decoder, thereby producing 3D object-aware features for final detection. Extensive experiments verify the effectiveness of our proposed method. Furthermore, OPEN achieves a new state-of-the-art performance with 64.4% NDS and 56.7% mAP on the nuScenes test benchmark.
Exploring the Causality of End-to-End Autonomous Driving
Jul 09, 2024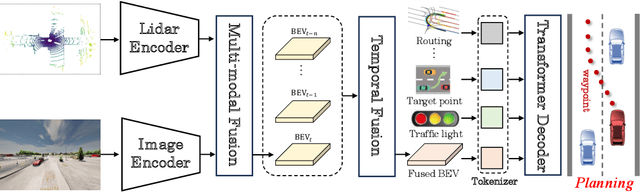
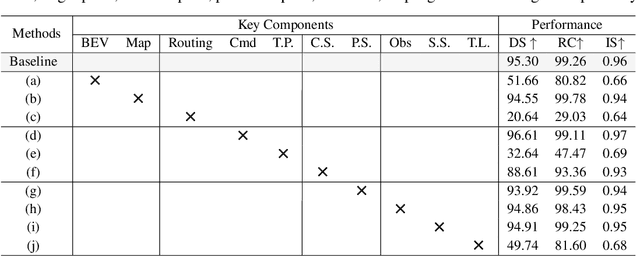

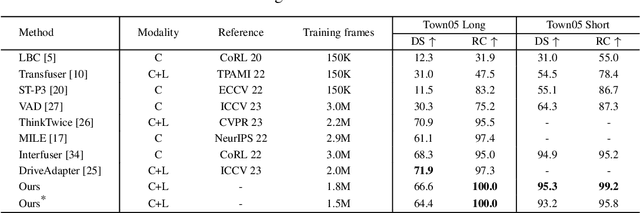
Deep learning-based models are widely deployed in autonomous driving areas, especially the increasingly noticed end-to-end solutions. However, the black-box property of these models raises concerns about their trustworthiness and safety for autonomous driving, and how to debug the causality has become a pressing concern. Despite some existing research on the explainability of autonomous driving, there is currently no systematic solution to help researchers debug and identify the key factors that lead to the final predicted action of end-to-end autonomous driving. In this work, we propose a comprehensive approach to explore and analyze the causality of end-to-end autonomous driving. First, we validate the essential information that the final planning depends on by using controlled variables and counterfactual interventions for qualitative analysis. Then, we quantitatively assess the factors influencing model decisions by visualizing and statistically analyzing the response of key model inputs. Finally, based on the comprehensive study of the multi-factorial end-to-end autonomous driving system, we have developed a strong baseline and a tool for exploring causality in the close-loop simulator CARLA. It leverages the essential input sources to obtain a well-designed model, resulting in highly competitive capabilities. As far as we know, our work is the first to unveil the mystery of end-to-end autonomous driving and turn the black box into a white one. Thorough close-loop experiments demonstrate that our method can be applied to end-to-end autonomous driving solutions for causality debugging. Code will be available at https://github.com/bdvisl/DriveInsight.