 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridTM: Combining Transformer and Mamba for 3D Semantic Segmentation
Jul 24, 2025Transformer-based methods have demonstrated remarkable capabilities in 3D semantic segmentation through their powerful attention mechanisms, but the quadratic complexity limits their modeling of long-range dependencies in large-scale point clouds. While recent Mamba-based approaches offer efficient processing with linear complexity, they struggle with feature representation when extracting 3D features. However, effectively combining these complementary strengths remains an open challenge in this field. In this paper, we propose HybridTM, the first hybrid architecture that integrates Transformer and Mamba for 3D semantic segmentation. In addition, we propose the Inner Layer Hybrid Strategy, which combines attention and Mamba at a finer granularity, enabling simultaneous capture of long-range dependencies and fine-grained local features. Extensive experiments demonstrate the effectiveness and generalization of our HybridTM on diverse indoor and outdoor datasets. Furthermore, our HybridTM achieves state-of-the-art performance on ScanNet, ScanNet200, and nuScenes benchmarks. The code will be made available at https://github.com/deepinact/HybridTM.
LION: Linear Group RNN for 3D Object Detection in Point Clouds
Jul 25, 2024



The benefit of transformers in large-scale 3D point cloud perception tasks, such as 3D object detection, is limited by their quadratic computation cost when modeling long-range relationships. In contrast, linear RNNs have low computational complexity and are suitable for long-range modeling. Toward this goal, we propose a simple and effective window-based framework built on LInear grOup RNN (i.e., perform linear RNN for grouped features) for accurate 3D object detection, called LION. The key property is to allow sufficient feature interaction in a much larger group than transformer-based methods. However, effectively applying linear group RNN to 3D object detection in highly sparse point clouds is not trivial due to its limitation in handling spatial modeling. To tackle this problem, we simply introduce a 3D spatial feature descriptor and integrate it into the linear group RNN operators to enhance their spatial features rather than blindly increasing the number of scanning orders for voxel features. To further address the challenge in highly sparse point clouds, we propose a 3D voxel generation strategy to densify foreground features thanks to linear group RNN as a natural property of auto-regressive models. Extensive experiments verify the effectiveness of the proposed components and the generalization of our LION on different linear group RNN operators including Mamba, RWKV, and RetNet. Furthermore, it is worth mentioning that our LION-Mamba achieves state-of-the-art on Waymo, nuScenes, Argoverse V2, and ONCE dataset. Last but not least, our method supports kinds of advanced linear RNN operators (e.g., RetNet, RWKV, Mamba, xLSTM and TTT) on small but popular KITTI dataset for a quick experience with our linear RNN-based framework.
SEED: A Simple and Effective 3D DETR in Point Clouds
Jul 15, 2024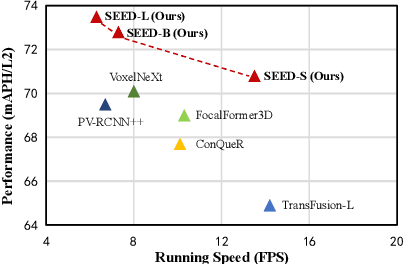
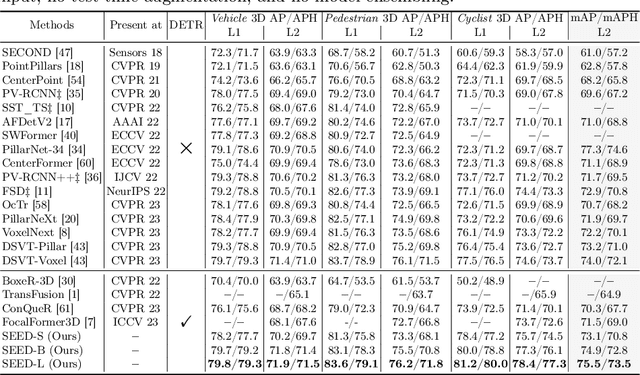
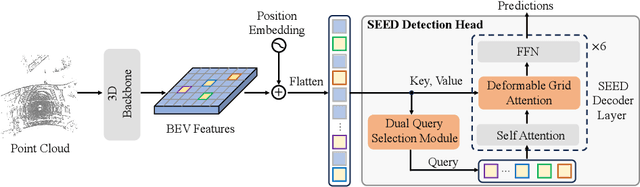
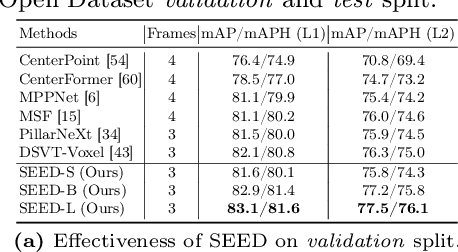
Recently, detection transformers (DETRs) have gradually taken a dominant position in 2D detection thanks to their elegant framework. However, DETR-based detectors for 3D point clouds are still difficult to achieve satisfactory performance. We argue that the main challenges are twofold: 1) How to obtain the appropriate object queries is challenging due to the high sparsity and uneven distribution of point clouds; 2) How to implement an effective query interaction by exploiting the rich geometric structure of point clouds is not fully explored. To this end, we propose a simple and effective 3D DETR method (SEED) for detecting 3D objects from point clouds, which involves a dual query selection (DQS) module and a deformable grid attention (DGA) module. More concretely, to obtain appropriate queries, DQS first ensures a high recall to retain a large number of queries by the predicted confidence scores and then further picks out high-quality queries according to the estimated quality scores. DGA uniformly divides each reference box into grids as the reference points and then utilizes the predicted offsets to achieve a flexible receptive field, allowing the network to focus on relevant regions and capture more informative features. Extensive ablation studies on DQS and DGA demonstrate its effectiveness. Furthermore, our SEED achieves state-of-the-art detection performance on both the large-scale Waymo and nuScenes datasets, illustrating the superiority of our proposed method. The code is available at https://github.com/happinesslz/SEED
OPEN: Object-wise Position Embedding for Multi-view 3D Object Detection
Jul 15, 2024



Accurate depth information is crucial for enhancing the performance of multi-view 3D object detection. Despite the success of some existing multi-view 3D detectors utilizing pixel-wise depth supervision, they overlook two significant phenomena: 1) the depth supervision obtained from LiDAR points is usually distributed on the surface of the object, which is not so friendly to existing DETR-based 3D detectors due to the lack of the depth of 3D object center; 2) for distant objects, fine-grained depth estimation of the whole object is more challenging. Therefore, we argue that the object-wise depth (or 3D center of the object) is essential for accurate detection. In this paper, we propose a new multi-view 3D object detector named OPEN, whose main idea is to effectively inject object-wise depth information into the network through our proposed object-wise position embedding. Specifically, we first employ an object-wise depth encoder, which takes the pixel-wise depth map as a prior, to accurately estimate the object-wise depth. Then, we utilize the proposed object-wise position embedding to encode the object-wise depth information into the transformer decoder, thereby producing 3D object-aware features for final detection. Extensive experiments verify the effectiveness of our proposed method. Furthermore, OPEN achieves a new state-of-the-art performance with 64.4% NDS and 56.7% mAP on the nuScenes test benchmark.
Diffusion-based 3D Object Detection with Random Boxes
Sep 05, 2023



3D object detection is an essential task for achieving autonomous driving. Existing anchor-based detection methods rely on empirical heuristics setting of anchors, which makes the algorithms lack elegance. In recent years, we have witnessed the rise of several generative models, among which diffusion models show great potential for learning the transformation of two distributions. Our proposed Diff3Det migrates the diffusion model to proposal generation for 3D object detection by considering the detection boxes as generative targets. During training, the object boxes diffuse from the ground truth boxes to the Gaussian distribution, and the decoder learns to reverse this noise process. In the inference stage, the model progressively refines a set of random boxes to the prediction results. We provide detailed experiments on the KITTI benchmark and achieve promising performance compared to classical anchor-based 3D detection methods.
DDS3D: Dense Pseudo-Labels with Dynamic Threshold for Semi-Supervised 3D Object Detection
Mar 10, 2023In this paper, we present a simple yet effective semi-supervised 3D object detector named DDS3D. Our main contributions have two-fold. On the one hand, different from previous works using Non-Maximal Suppression (NMS) or its variants for obtaining the sparse pseudo labels, we propose a dense pseudo-label generation strategy to get dense pseudo-labels, which can retain more potential supervision information for the student network. On the other hand, instead of traditional fixed thresholds, we propose a dynamic threshold manner to generate pseudo-labels, which can guarantee the quality and quantity of pseudo-labels during the whole training process. Benefiting from these two components, our DDS3D outperforms the state-of-the-art semi-supervised 3d object detection with mAP of 3.1% on the pedestrian and 2.1% on the cyclist under the same configuration of 1% samples. Extensive ablation studies on the KITTI dataset demonstrate the effectiveness of our DDS3D. The code and models will be made publicly available at https://github.com/hust-jy/DDS3D