 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Dec 16, 2025


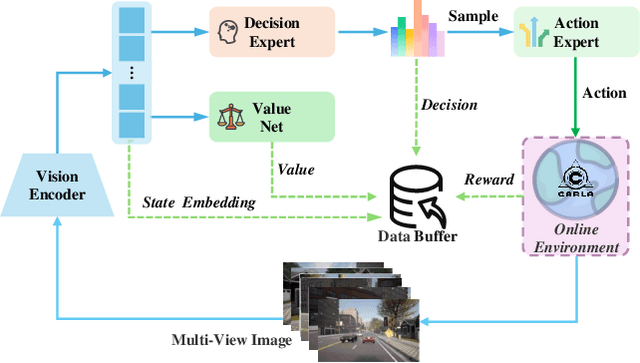
Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.
NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
Oct 31, 2025Underwater exploration offers critical insights into our planet and attracts increasing attention for its broader applications in resource exploration, national security, etc. We study the underwater scene understanding methods, which aim to achieve automated underwater exploration. The underwater scene understanding task demands multi-task perceptions from multiple granularities. However, the absence of large-scale underwater multi-task instruction-tuning datasets hinders the progress of this research. To bridge this gap, we construct NautData, a dataset containing 1.45 M image-text pairs supporting eight underwater scene understanding tasks. It enables the development and thorough evaluation of the underwater scene understanding models. Underwater image degradation is a widely recognized challenge that interferes with underwater tasks. To improve the robustness of underwater scene understanding, we introduce physical priors derived from underwater imaging models and propose a plug-and-play vision feature enhancement (VFE) module, which explicitly restores clear underwater information. We integrate this module into renowned baselines LLaVA-1.5 and Qwen2.5-VL and build our underwater LMM, NAUTILUS. Experiments conducted on the NautData and public underwater datasets demonstrate the effectiveness of the VFE module, consistently improving the performance of both baselines on the majority of supported tasks, thus ensuring the superiority of NAUTILUS in the underwater scene understanding area. Data and models are available at https://github.com/H-EmbodVis/NAUTILUS.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Shuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shuffle
Aug 07, 2025Reinforcement learning (RL) has emerged as an effective post-training paradigm for enhancing the reasoning capabilities of multimodal large language model (MLLM). However, current RL pipelines often suffer from training inefficiencies caused by two underexplored issues: Advantage Collapsing, where most advantages in a batch concentrate near zero, and Rollout Silencing, where the proportion of rollouts contributing non-zero gradients diminishes over time. These issues lead to suboptimal gradient updates and hinder long-term learning efficiency. To address these issues, we propose Shuffle-R1, a simple yet principled framework that improves RL fine-tuning efficiency by dynamically restructuring trajectory sampling and batch composition. It introduces (1) Pairwise Trajectory Sampling, which selects high-contrast trajectories with large advantages to improve gradient signal quality, and (2) Advantage-based Trajectory Shuffle, which increases exposure of valuable rollouts through informed batch reshuffling. Experiments across multiple reasoning benchmarks show that our framework consistently outperforms strong RL baselines with minimal overhead. These results highlight the importance of data-centric adaptations for more efficient RL training in MLLM.
Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
Jul 03, 2025Video generation models have demonstrated remarkable performance, yet their broader adoption remains constrained by slow inference speeds and substantial computational costs, primarily due to the iterative nature of the denoising process. Addressing this bottleneck is essential for democratizing advanced video synthesis technologies and enabling their integration into real-world applications. This work proposes EasyCache, a training-free acceleration framework for video diffusion models. EasyCache introduces a lightweight, runtime-adaptive caching mechanism that dynamically reuses previously computed transformation vectors, avoiding redundant computations during inference. Unlike prior approaches, EasyCache requires no offline profiling, pre-computation, or extensive parameter tuning. We conduct comprehensive studies on various large-scale video generation models, including OpenSora, Wan2.1, and HunyuanVideo. Our method achieves leading acceleration performance, reducing inference time by up to 2.1-3.3$\times$ compared to the original baselines while maintaining high visual fidelity with a significant up to 36% PSNR improvement compared to the previous SOTA method. This improvement makes our EasyCache a efficient and highly accessible solution for high-quality video generation in both research and practical applications. The code is available at https://github.com/H-EmbodVis/EasyCache.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025



The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.
DriVerse: Navigation World Model for Driving Simulation via Multimodal Trajectory Prompting and Motion Alignment
Apr 22, 2025



This paper presents DriVerse, a generative model for simulating navigation-driven driving scenes from a single image and a future trajectory. Previous autonomous driving world models either directly feed the trajectory or discrete control signals into the generation pipeline, leading to poor alignment between the control inputs and the implicit features of the 2D base generative model, which results in low-fidelity video outputs. Some methods use coarse textual commands or discrete vehicle control signals, which lack the precision to guide fine-grained, trajectory-specific video generation, making them unsuitable for evaluating actual autonomous driving algorithms. DriVerse introduces explicit trajectory guidance in two complementary forms: it tokenizes trajectories into textual prompts using a predefined trend vocabulary for seamless language integration, and converts 3D trajectories into 2D spatial motion priors to enhance control over static content within the driving scene. To better handle dynamic objects, we further introduce a lightweight motion alignment module, which focuses on the inter-frame consistency of dynamic pixels, significantly enhancing the temporal coherence of moving elements over long sequences. With minimal training and no need for additional data, DriVerse outperforms specialized models on future video generation tasks across both the nuScenes and Waymo datasets. The code and models will be released to the public.
SemiETS: Integrating Spatial and Content Consistencies for Semi-Supervised End-to-end Text Spotting
Apr 14, 2025Most previous scene text spotting methods rely on high-quality manual annotations to achieve promising performance. To reduce their expensive costs, we study semi-supervised text spotting (SSTS) to exploit useful information from unlabeled images. However, directly applying existing semi-supervised methods of general scenes to SSTS will face new challenges: 1) inconsistent pseudo labels between detection and recognition tasks, and 2) sub-optimal supervisions caused by inconsistency between teacher/student. Thus, we propose a new Semi-supervised framework for End-to-end Text Spotting, namely SemiETS that leverages the complementarity of text detection and recognition. Specifically, it gradually generates reliable hierarchical pseudo labels for each task, thereby reducing noisy labels. Meanwhile, it extracts important information in locations and transcriptions from bidirectional flows to improve consistency. Extensive experiments on three datasets under various settings demonstrate the effectiveness of SemiETS on arbitrary-shaped text. For example, it outperforms previous state-of-the-art SSL methods by a large margin on end-to-end spotting (+8.7%, +5.6%, and +2.6% H-mean under 0.5%, 1%, and 2% labeled data settings on Total-Text, respectively). More importantly, it still improves upon a strongly supervised text spotter trained with plenty of labeled data by 2.0%. Compelling domain adaptation ability shows practical potential. Moreover, our method demonstrates consistent improvement on different text spotters.
A Unified Image-Dense Annotation Generation Model for Underwater Scenes
Mar 27, 2025Underwater dense prediction, especially depth estimation and semantic segmentation, is crucial for gaining a comprehensive understanding of underwater scenes. Nevertheless, high-quality and large-scale underwater datasets with dense annotations remain scarce because of the complex environment and the exorbitant data collection costs. This paper proposes a unified Text-to-Image and DEnse annotation generation method (TIDE) for underwater scenes. It relies solely on text as input to simultaneously generate realistic underwater images and multiple highly consistent dense annotations. Specifically, we unify the generation of text-to-image and text-to-dense annotations within a single model. The Implicit Layout Sharing mechanism (ILS) and cross-modal interaction method called Time Adaptive Normalization (TAN) are introduced to jointly optimize the consistency between image and dense annotations. We synthesize a large-scale underwater dataset using TIDE to validate the effectiveness of our method in underwater dense prediction tasks. The results demonstrate that our method effectively improves the performance of existing underwater dense prediction models and mitigates the scarcity of underwater data with dense annotations. We hope our method can offer new perspectives on alleviating data scarcity issues in other fields. The code is available at https: //github.com/HongkLin/TIDE.
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Mar 25, 2025End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.