 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSTAR: Box-free Multi-query Scene Text Retrieval with Attention Recycling
Jun 12, 2025Scene text retrieval has made significant progress with the assistance of accurate text localization. However, existing approaches typically require costly bounding box annotations for training. Besides, they mostly adopt a customized retrieval strategy but struggle to unify various types of queries to meet diverse retrieval needs. To address these issues, we introduce Muti-query Scene Text retrieval with Attention Recycling (MSTAR), a box-free approach for scene text retrieval. It incorporates progressive vision embedding to dynamically capture the multi-grained representation of texts and harmonizes free-style text queries with style-aware instructions. Additionally, a multi-instance matching module is integrated to enhance vision-language alignment. Furthermore, we build the Multi-Query Text Retrieval (MQTR) dataset, the first benchmark designed to evaluate the multi-query scene text retrieval capability of models, comprising four query types and 16k images. Extensive experiments demonstrate the superiority of our method across seven public datasets and the MQTR dataset. Notably, MSTAR marginally surpasses the previous state-of-the-art model by 6.4% in MAP on Total-Text while eliminating box annotation costs. Moreover, on the MQTR benchmark, MSTAR significantly outperforms the previous models by an average of 8.5%. The code and datasets are available at https://github.com/yingift/MSTAR.
TokBench: Evaluating Your Visual Tokenizer before Visual Generation
May 26, 2025In this work, we reveal the limitations of visual tokenizers and VAEs in preserving fine-grained features, and propose a benchmark to evaluate reconstruction performance for two challenging visual contents: text and face. Visual tokenizers and VAEs have significantly advanced visual generation and multimodal modeling by providing more efficient compressed or quantized image representations. However, while helping production models reduce computational burdens, the information loss from image compression fundamentally limits the upper bound of visual generation quality. To evaluate this upper bound, we focus on assessing reconstructed text and facial features since they typically: 1) exist at smaller scales, 2) contain dense and rich textures, 3) are prone to collapse, and 4) are highly sensitive to human vision. We first collect and curate a diverse set of clear text and face images from existing datasets. Unlike approaches using VLM models, we employ established OCR and face recognition models for evaluation, ensuring accuracy while maintaining an exceptionally lightweight assessment process <span style="font-weight: bold; color: rgb(214, 21, 21);">requiring just 2GB memory and 4 minutes</span> to complete. Using our benchmark, we analyze text and face reconstruction quality across various scales for different image tokenizers and VAEs. Our results show modern visual tokenizers still struggle to preserve fine-grained features, especially at smaller scales. We further extend this evaluation framework to video, conducting comprehensive analysis of video tokenizers. Additionally, we demonstrate that traditional metrics fail to accurately reflect reconstruction performance for faces and text, while our proposed metrics serve as an effective complement.
SemiETS: Integrating Spatial and Content Consistencies for Semi-Supervised End-to-end Text Spotting
Apr 14, 2025Most previous scene text spotting methods rely on high-quality manual annotations to achieve promising performance. To reduce their expensive costs, we study semi-supervised text spotting (SSTS) to exploit useful information from unlabeled images. However, directly applying existing semi-supervised methods of general scenes to SSTS will face new challenges: 1) inconsistent pseudo labels between detection and recognition tasks, and 2) sub-optimal supervisions caused by inconsistency between teacher/student. Thus, we propose a new Semi-supervised framework for End-to-end Text Spotting, namely SemiETS that leverages the complementarity of text detection and recognition. Specifically, it gradually generates reliable hierarchical pseudo labels for each task, thereby reducing noisy labels. Meanwhile, it extracts important information in locations and transcriptions from bidirectional flows to improve consistency. Extensive experiments on three datasets under various settings demonstrate the effectiveness of SemiETS on arbitrary-shaped text. For example, it outperforms previous state-of-the-art SSL methods by a large margin on end-to-end spotting (+8.7%, +5.6%, and +2.6% H-mean under 0.5%, 1%, and 2% labeled data settings on Total-Text, respectively). More importantly, it still improves upon a strongly supervised text spotter trained with plenty of labeled data by 2.0%. Compelling domain adaptation ability shows practical potential. Moreover, our method demonstrates consistent improvement on different text spotters.
PDF-WuKong: A Large Multimodal Model for Efficient Long PDF Reading with End-to-End Sparse Sampling
Oct 08, 2024Document understanding is a challenging task to process and comprehend large amounts of textual and visual information. Recent advances in Large Language Models (LLMs) have significantly improved the performance of this task. However, existing methods typically focus on either plain text or a limited number of document images, struggling to handle long PDF documents with interleaved text and images, especially in academic papers. In this paper, we introduce PDF-WuKong, a multimodal large language model (MLLM) which is designed to enhance multimodal question-answering (QA) for long PDF documents. PDF-WuKong incorporates a sparse sampler that operates on both text and image representations, significantly improving the efficiency and capability of the MLLM. The sparse sampler is integrated with the MLLM's image encoder and selects the paragraphs or diagrams most pertinent to user queries for processing by the language model. To effectively train and evaluate our model, we construct PaperPDF, a dataset consisting of a broad collection of academic papers sourced from arXiv, multiple strategies are proposed to generate automatically 1M QA pairs along with their corresponding evidence sources. Experimental results demonstrate the superiority and high efficiency of our approach over other models on the task of long multimodal PDF understanding, surpassing proprietary products by an average of 8.6% on F1. Our code and dataset will be released at https://github.com/yh-hust/PDF-Wukong.
WAS: Dataset and Methods for Artistic Text Segmentation
Jul 31, 2024
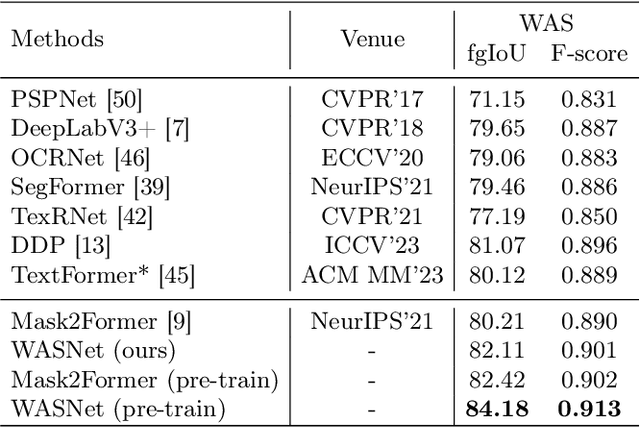
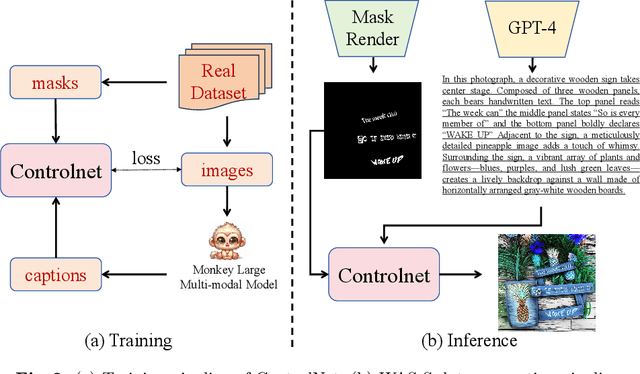
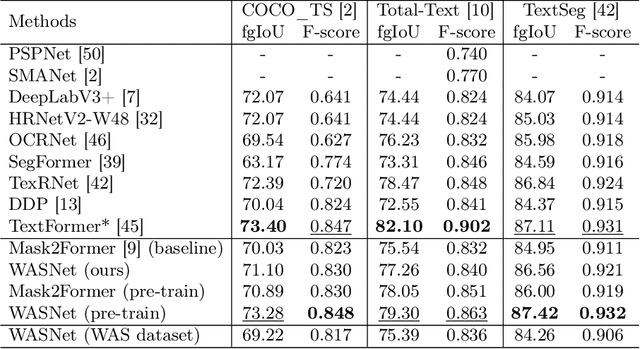
Accurate text segmentation results are crucial for text-related generative tasks, such as text image generation, text editing, text removal, and text style transfer. Recently, some scene text segmentation methods have made significant progress in segmenting regular text. However, these methods perform poorly in scenarios containing artistic text. Therefore, this paper focuses on the more challenging task of artistic text segmentation and constructs a real artistic text segmentation dataset. One challenge of the task is that the local stroke shapes of artistic text are changeable with diversity and complexity. We propose a decoder with the layer-wise momentum query to prevent the model from ignoring stroke regions of special shapes. Another challenge is the complexity of the global topological structure. We further design a skeleton-assisted head to guide the model to focus on the global structure. Additionally, to enhance the generalization performance of the text segmentation model, we propose a strategy for training data synthesis, based on the large multi-modal model and the diffusion model. Experimental results show that our proposed method and synthetic dataset can significantly enhance the performance of artistic text segmentation and achieve state-of-the-art results on other public datasets.
Progressive Evolution from Single-Point to Polygon for Scene Text
Dec 21, 2023The advancement of text shape representations towards compactness has enhanced text detection and spotting performance, but at a high annotation cost. Current models use single-point annotations to reduce costs, yet they lack sufficient localization information for downstream applications. To overcome this limitation, we introduce Point2Polygon, which can efficiently transform single-points into compact polygons. Our method uses a coarse-to-fine process, starting with creating and selecting anchor points based on recognition confidence, then vertically and horizontally refining the polygon using recognition information to optimize its shape. We demonstrate the accuracy of the generated polygons through extensive experiments: 1) By creating polygons from ground truth points, we achieved an accuracy of 82.0% on ICDAR 2015; 2) In training detectors with polygons generated by our method, we attained 86% of the accuracy relative to training with ground truth (GT); 3) Additionally, the proposed Point2Polygon can be seamlessly integrated to empower single-point spotters to generate polygons. This integration led to an impressive 82.5% accuracy for the generated polygons. It is worth mentioning that our method relies solely on synthetic recognition information, eliminating the need for any manual annotation beyond single points.
Learning in a Single Domain for Non-Stationary Multi-Texture Synthesis
May 10, 2023This paper aims for a new generation task: non-stationary multi-texture synthesis, which unifies synthesizing multiple non-stationary textures in a single model. Most non-stationary textures have large scale variance and can hardly be synthesized through one model. To combat this, we propose a multi-scale generator to capture structural patterns of various scales and effectively synthesize textures with a minor cost. However, it is still hard to handle textures of different categories with different texture patterns. Therefore, we present a category-specific training strategy to focus on learning texture pattern of a specific domain. Interestingly, once trained, our model is able to produce multi-pattern generations with dynamic variations without the need to finetune the model for different styles. Moreover, an objective evaluation metric is designed for evaluating the quality of texture expansion and global structure consistency. To our knowledge, ours is the first scheme for this challenging task, including model, training, and evaluation. Experimental results demonstrate the proposed method achieves superior performance and time efficiency. The code will be available after the publication.
Toward Understanding WordArt: Corner-Guided Transformer for Scene Text Recognition
Jul 31, 2022
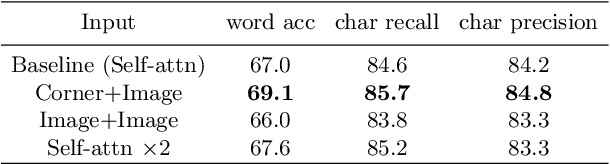

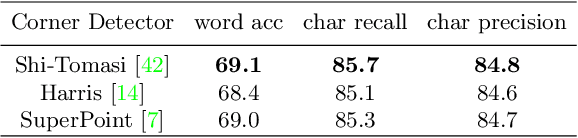
Artistic text recognition is an extremely challenging task with a wide range of applications. However, current scene text recognition methods mainly focus on irregular text while have not explored artistic text specifically. The challenges of artistic text recognition include the various appearance with special-designed fonts and effects, the complex connections and overlaps between characters, and the severe interference from background patterns. To alleviate these problems, we propose to recognize the artistic text at three levels. Firstly, corner points are applied to guide the extraction of local features inside characters, considering the robustness of corner structures to appearance and shape. In this way, the discreteness of the corner points cuts off the connection between characters, and the sparsity of them improves the robustness for background interference. Secondly, we design a character contrastive loss to model the character-level feature, improving the feature representation for character classification. Thirdly, we utilize Transformer to learn the global feature on image-level and model the global relationship of the corner points, with the assistance of a corner-query cross-attention mechanism. Besides, we provide an artistic text dataset to benchmark the performance. Experimental results verify the significant superiority of our proposed method on artistic text recognition and also achieve state-of-the-art performance on several blurred and perspective datasets.
Person Re-Identification by Unsupervised Video Matching
Nov 28, 2016
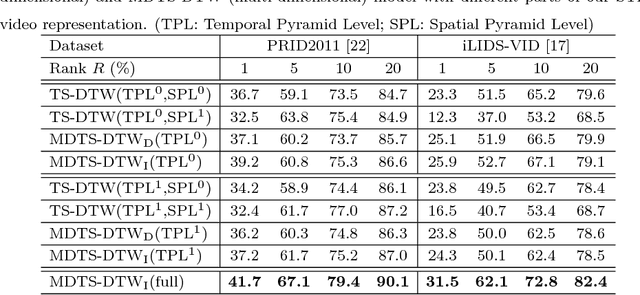

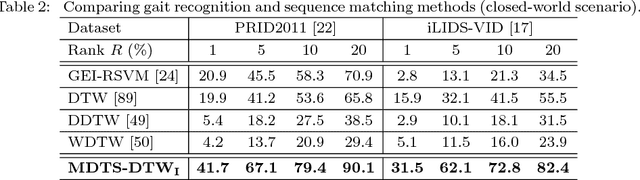
Most existing person re-identification (ReID) methods rely only on the spatial appearance information from either one or multiple person images, whilst ignore the space-time cues readily available in video or image-sequence data. Moreover, they often assume the availability of exhaustively labelled cross-view pairwise data for every camera pair, making them non-scalable to ReID applications in real-world large scale camera networks. In this work, we introduce a novel video based person ReID method capable of accurately matching people across views from arbitrary unaligned image-sequences without any labelled pairwise data. Specifically, we introduce a new space-time person representation by encoding multiple granularities of spatio-temporal dynamics in form of time series. Moreover, a Time Shift Dynamic Time Warping (TS-DTW) model is derived for performing automatically alignment whilst achieving data selection and matching between inherently inaccurate and incomplete sequences in a unified way. We further extend the TS-DTW model for accommodating multiple feature-sequences of an image-sequence in order to fuse information from different descriptions. Crucially, this model does not require pairwise labelled training data (i.e. unsupervised) therefore readily scalable to large scale camera networks of arbitrary camera pairs without the need for exhaustive data annotation for every camera pair. We show the effectiveness and advantages of the proposed method by extensive comparisons with related state-of-the-art approaches using two benchmarking ReID datasets, PRID2011 and iLIDS-VID.