 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacMamba: A Tactile History Compression Adapter Bridging Fast Reflexes and Slow VLA Reasoning
Mar 02, 2026In visually ambiguous manipulation such as detecting button click tactile feedback is often the sole source of ground truth. However, fusing tactile data poses a significant challenge due to a spatiotemporal mismatch: tactile perception requires high-frequency processing with long-horizon memory (System 1), whereas visual policies operate at low control frequencies (System 2). Existing architectures struggle to bridge this gap: Transformers are computationally prohibitive for high-frequency loops (>100Hz), while LSTMs suffer from forgetting over extended interaction histories. In this paper, we introduce TacMamba, a hierarchical architecture that aligns high-bandwidth tactile reflexes with low-frequency visual planning. Our approach comprises three core contributions: (1) a custom high-frequency tactile interface designed for flexible integration; (2) a Mamba-based Tactile History Compressor that encodes continuous force history into a compact state with O(1) inference latency (0.45 ms), enabling plug-and-play fusion with VLA models without joint pre-training and (3) a Tactile-Guided Dual-Stage Training strategy that leverages temporal discrimination for self-supervised representation learning and phase-uniform sampling to mitigate data sparsity. Experiments on discrete counting and implicit state switching demonstrate that TacMamba achieves 100% success rates, significantly outperforming the visual-only pi_0.5 baseline, while strictly satisfying hard real-time constraints.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
CrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Sep 17, 2025High-quality annotated data is a cornerstone of modern Natural Language Processing (NLP). While recent methods begin to leverage diverse annotation sources-including Large Language Models (LLMs), Small Language Models (SLMs), and human experts-they often focus narrowly on the labeling step itself. A critical gap remains in the holistic process control required to manage these sources dynamically, addressing complex scheduling and quality-cost trade-offs in a unified manner. Inspired by real-world crowdsourcing companies, we introduce CrowdAgent, a multi-agent system that provides end-to-end process control by integrating task assignment, data annotation, and quality/cost management. It implements a novel methodology that rationally assigns tasks, enabling LLMs, SLMs, and human experts to advance synergistically in a collaborative annotation workflow. We demonstrate the effectiveness of CrowdAgent through extensive experiments on six diverse multimodal classification tasks. The source code and video demo are available at https://github.com/QMMMS/CrowdAgent.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
TextRegion: Text-Aligned Region Tokens from Frozen Image-Text Models
May 29, 2025Image-text models excel at image-level tasks but struggle with detailed visual understanding. While these models provide strong visual-language alignment, segmentation models like SAM2 offer precise spatial boundaries for objects. To this end, we propose TextRegion, a simple, effective, and training-free framework that combines the strengths of image-text models and SAM2 to generate powerful text-aligned region tokens. These tokens enable detailed visual understanding while preserving open-vocabulary capabilities. They can be directly applied to various downstream tasks, including open-world semantic segmentation, referring expression comprehension, and grounding. We conduct extensive evaluations and consistently achieve superior or competitive performance compared to state-of-the-art training-free methods. Additionally, our framework is compatible with many image-text models, making it highly practical and easily extensible as stronger models emerge. Code is available at: https://github.com/avaxiao/TextRegion.
Zero-Shot Low Light Image Enhancement with Diffusion Prior
Dec 18, 2024



Balancing aesthetic quality with fidelity when enhancing images from challenging, degraded sources is a core objective in computational photography. In this paper, we address low light image enhancement (LLIE), a task in which dark images often contain limited visible information. Diffusion models, known for their powerful image enhancement capacities, are a natural choice for this problem. However, their deep generative priors can also lead to hallucinations, introducing non-existent elements or substantially altering the visual semantics of the original scene. In this work, we introduce a novel zero-shot method for controlling and refining the generative behavior of diffusion models for dark-to-light image conversion tasks. Our method demonstrates superior performance over existing state-of-the-art methods in the task of low-light image enhancement, as evidenced by both quantitative metrics and qualitative analysis.
AnyBipe: An End-to-End Framework for Training and Deploying Bipedal Robots Guided by Large Language Models
Sep 13, 2024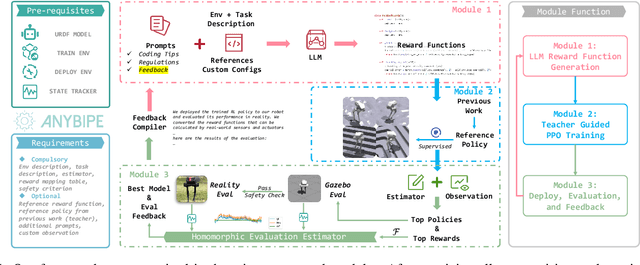


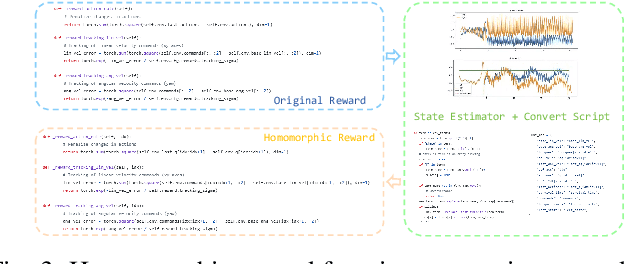
Training and deploying reinforcement learning (RL) policies for robots, especially in accomplishing specific tasks, presents substantial challenges. Recent advancements have explored diverse reward function designs, training techniques, simulation-to-reality (sim-to-real) transfers, and performance analysis methodologies, yet these still require significant human intervention. This paper introduces an end-to-end framework for training and deploying RL policies, guided by Large Language Models (LLMs), and evaluates its effectiveness on bipedal robots. The framework consists of three interconnected modules: an LLM-guided reward function design module, an RL training module leveraging prior work, and a sim-to-real homomorphic evaluation module. This design significantly reduces the need for human input by utilizing only essential simulation and deployment platforms, with the option to incorporate human-engineered strategies and historical data. We detail the construction of these modules, their advantages over traditional approaches, and demonstrate the framework's capability to autonomously develop and refine controlling strategies for bipedal robot locomotion, showcasing its potential to operate independently of human intervention.
Anytime Continual Learning for Open Vocabulary Classification
Sep 13, 2024We propose an approach for anytime continual learning (AnytimeCL) for open vocabulary image classification. The AnytimeCL problem aims to break away from batch training and rigid models by requiring that a system can predict any set of labels at any time and efficiently update and improve when receiving one or more training samples at any time. Despite the challenging goal, we achieve substantial improvements over recent methods. We propose a dynamic weighting between predictions of a partially fine-tuned model and a fixed open vocabulary model that enables continual improvement when training samples are available for a subset of a task's labels. We also propose an attention-weighted PCA compression of training features that reduces storage and computation with little impact to model accuracy. Our methods are validated with experiments that test flexibility of learning and inference. Code is available at https://github.com/jessemelpolio/AnytimeCL.
Undergraduate Robotics Education with General Instructors using a Student-Centered Personalized Learning Framework
Jun 12, 2024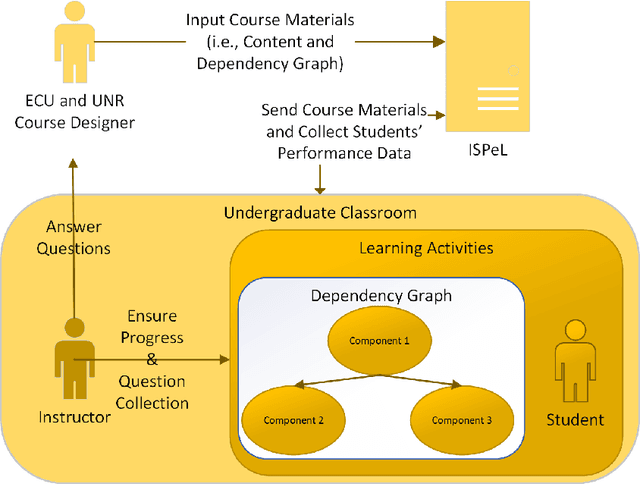
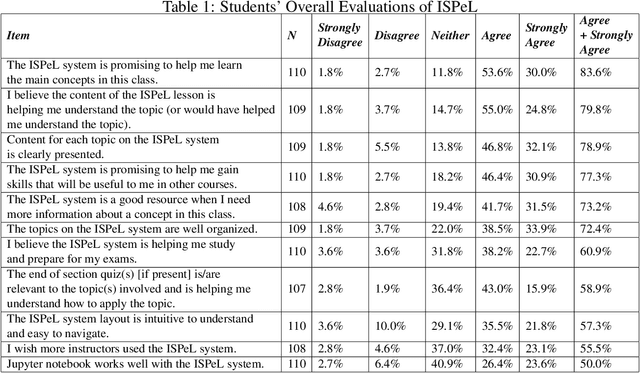
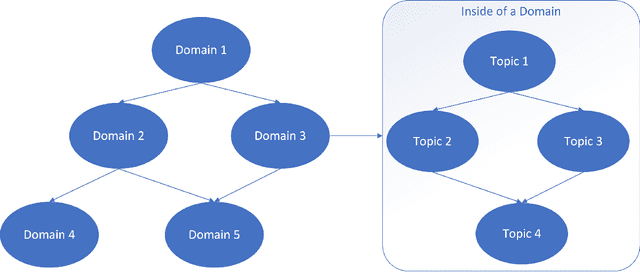
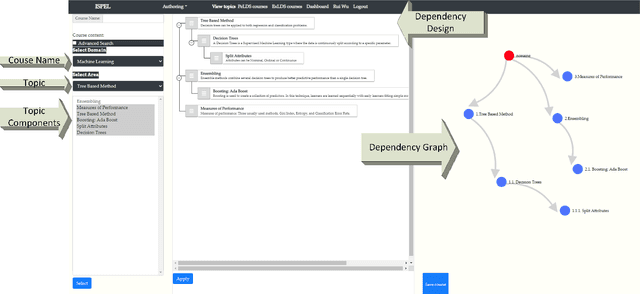
Recent advancements in robotics, including applications like self-driving cars, unmanned systems, and medical robots, have had a significant impact on the job market. On one hand, big robotics companies offer training programs based on the job requirements. However, these training programs may not be as beneficial as general robotics programs offered by universities or community colleges. On the other hand, community colleges and universities face challenges with required resources, especially qualified instructors, to offer students advanced robotics education. Furthermore, the diverse backgrounds of undergraduate students present additional challenges. Some students bring extensive industry experiences, while others are newcomers to the field. To address these challenges, we propose a student-centered personalized learning framework for robotics. This framework allows a general instructor to teach undergraduate-level robotics courses by breaking down course topics into smaller components with well-defined topic dependencies, structured as a graph. This modular approach enables students to choose their learning path, catering to their unique preferences and pace. Moreover, our framework's flexibility allows for easy customization of teaching materials to meet the specific needs of host institutions. In addition to teaching materials, a frequently-asked-questions document would be prepared for a general instructor. If students' robotics questions cannot be answered by the instructor, the answers to these questions may be included in this document. For questions not covered in this document, we can gather and address them through collaboration with the robotics community and course content creators. Our user study results demonstrate the promise of this method in delivering undergraduate-level robotics education tailored to individual learning outcomes and preferences.
Survey on Memory-Augmented Neural Networks: Cognitive Insights to AI Applications
Dec 13, 2023This paper explores Memory-Augmented Neural Networks (MANNs), delving into how they blend human-like memory processes into AI. It covers different memory types, like sensory, short-term, and long-term memory, linking psychological theories with AI applications. The study investigates advanced architectures such as Hopfield Networks, Neural Turing Machines, Correlation Matrix Memories, Memformer, and Neural Attention Memory, explaining how they work and where they excel. It dives into real-world uses of MANNs across Natural Language Processing, Computer Vision, Multimodal Learning, and Retrieval Models, showing how memory boosters enhance accuracy, efficiency, and reliability in AI tasks. Overall, this survey provides a comprehensive view of MANNs, offering insights for future research in memory-based AI systems.