 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneDiff: A Benchmark and Method for Multiview Object Change Detection
Dec 18, 2025We investigate the problem of identifying objects that have been added, removed, or moved between a pair of captures (images or videos) of the same scene at different times. Detecting such changes is important for many applications, such as robotic tidying or construction progress and safety monitoring. A major challenge is that varying viewpoints can cause objects to falsely appear changed. We introduce SceneDiff Benchmark, the first multiview change detection benchmark with object instance annotations, comprising 350 diverse video pairs with thousands of changed objects. We also introduce the SceneDiff method, a new training-free approach for multiview object change detection that leverages pretrained 3D, segmentation, and image encoding models to robustly predict across multiple benchmarks. Our method aligns the captures in 3D, extracts object regions, and compares spatial and semantic region features to detect changes. Experiments on multi-view and two-view benchmarks demonstrate that our method outperforms existing approaches by large margins (94% and 37.4% relative AP improvements). The benchmark and code will be publicly released.
TextRegion: Text-Aligned Region Tokens from Frozen Image-Text Models
May 29, 2025Image-text models excel at image-level tasks but struggle with detailed visual understanding. While these models provide strong visual-language alignment, segmentation models like SAM2 offer precise spatial boundaries for objects. To this end, we propose TextRegion, a simple, effective, and training-free framework that combines the strengths of image-text models and SAM2 to generate powerful text-aligned region tokens. These tokens enable detailed visual understanding while preserving open-vocabulary capabilities. They can be directly applied to various downstream tasks, including open-world semantic segmentation, referring expression comprehension, and grounding. We conduct extensive evaluations and consistently achieve superior or competitive performance compared to state-of-the-art training-free methods. Additionally, our framework is compatible with many image-text models, making it highly practical and easily extensible as stronger models emerge. Code is available at: https://github.com/avaxiao/TextRegion.
MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
Apr 12, 2024The latest regularized Neural Radiance Field (NeRF) approaches produce poor geometry and view extrapolation for multiview stereo (MVS) benchmarks such as ETH3D. In this paper, we aim to create 3D models that provide accurate geometry and view synthesis, partially closing the large geometric performance gap between NeRF and traditional MVS methods. We propose a patch-based approach that effectively leverages monocular surface normal and relative depth predictions. The patch-based ray sampling also enables the appearance regularization of normalized cross-correlation (NCC) and structural similarity (SSIM) between randomly sampled virtual and training views. We further show that "density restrictions" based on sparse structure-from-motion points can help greatly improve geometric accuracy with a slight drop in novel view synthesis metrics. Our experiments show 4x the performance of RegNeRF and 8x that of FreeNeRF on average F1@2cm for ETH3D MVS benchmark, suggesting a fruitful research direction to improve the geometric accuracy of NeRF-based models, and sheds light on a potential future approach to enable NeRF-based optimization to eventually outperform traditional MVS.
Region-Based Representations Revisited
Feb 04, 2024We investigate whether region-based representations are effective for recognition. Regions were once a mainstay in recognition approaches, but pixel and patch-based features are now used almost exclusively. We show that recent class-agnostic segmenters like SAM can be effectively combined with strong unsupervised representations like DINOv2 and used for a wide variety of tasks, including semantic segmentation, object-based image retrieval, and multi-image analysis. Once the masks and features are extracted, these representations, even with linear decoders, enable competitive performance, making them well suited to applications that require custom queries. The compactness of the representation also makes it well-suited to video analysis and other problems requiring inference across many images.
QFF: Quantized Fourier Features for Neural Field Representations
Dec 02, 2022Multilayer perceptrons (MLPs) learn high frequencies slowly. Recent approaches encode features in spatial bins to improve speed of learning details, but at the cost of larger model size and loss of continuity. Instead, we propose to encode features in bins of Fourier features that are commonly used for positional encoding. We call these Quantized Fourier Features (QFF). As a naturally multiresolution and periodic representation, our experiments show that using QFF can result in smaller model size, faster training, and better quality outputs for several applications, including Neural Image Representations (NIR), Neural Radiance Field (NeRF) and Signed Distance Function (SDF) modeling. QFF are easy to code, fast to compute, and serve as a simple drop-in addition to many neural field representations.
Sparse SPN: Depth Completion from Sparse Keypoints
Dec 02, 2022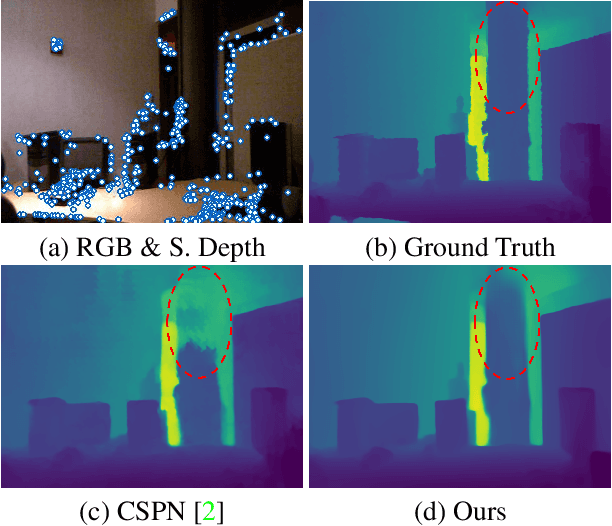
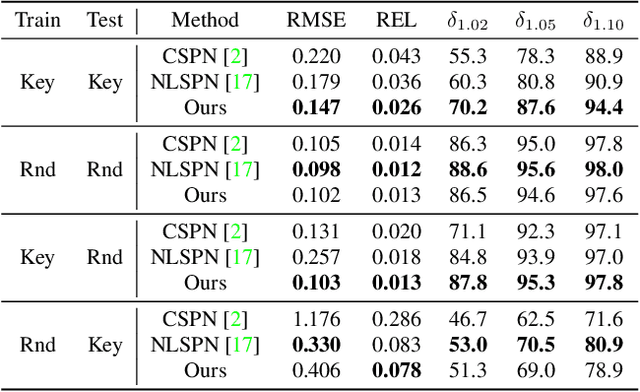

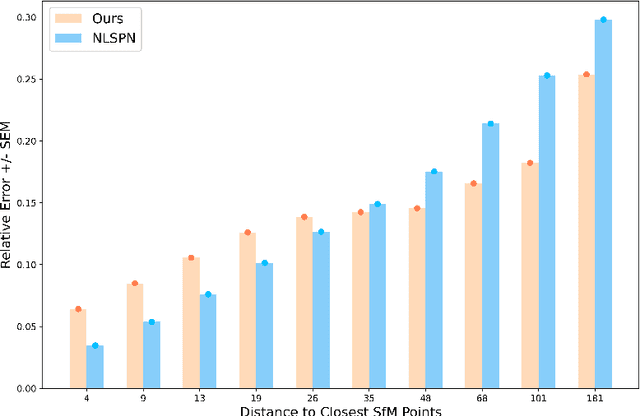
Our long term goal is to use image-based depth completion to quickly create 3D models from sparse point clouds, e.g. from SfM or SLAM. Much progress has been made in depth completion. However, most current works assume well distributed samples of known depth, e.g. Lidar or random uniform sampling, and perform poorly on uneven samples, such as from keypoints, due to the large unsampled regions. To address this problem, we extend CSPN with multiscale prediction and a dilated kernel, leading to much better completion of keypoint-sampled depth. We also show that a model trained on NYUv2 creates surprisingly good point clouds on ETH3D by completing sparse SfM points.