 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Generate Visual Programs Without Prompting LLMs?
Dec 11, 2024Visual programming prompts LLMs (large language mod-els) to generate executable code for visual tasks like visual question answering (VQA). Prompt-based methods are difficult to improve while also being unreliable and costly in both time and money. Our goal is to develop an efficient visual programming system without 1) using prompt-based LLMs at inference time and 2) a large set of program and answer annotations. We develop a synthetic data augmentation approach and alternative program generation method based on decoupling programs into higher-level skills called templates and the corresponding arguments. Our results show that with data augmentation, prompt-free smaller LLMs ($\approx$ 1B parameters) are competitive with state-of-the art models with the added benefit of much faster inference
Region-Based Representations Revisited
Feb 04, 2024We investigate whether region-based representations are effective for recognition. Regions were once a mainstay in recognition approaches, but pixel and patch-based features are now used almost exclusively. We show that recent class-agnostic segmenters like SAM can be effectively combined with strong unsupervised representations like DINOv2 and used for a wide variety of tasks, including semantic segmentation, object-based image retrieval, and multi-image analysis. Once the masks and features are extracted, these representations, even with linear decoders, enable competitive performance, making them well suited to applications that require custom queries. The compactness of the representation also makes it well-suited to video analysis and other problems requiring inference across many images.
WebWISE: Web Interface Control and Sequential Exploration with Large Language Models
Oct 25, 2023The paper investigates using a Large Language Model (LLM) to automatically perform web software tasks using click, scroll, and text input operations. Previous approaches, such as reinforcement learning (RL) or imitation learning, are inefficient to train and task-specific. Our method uses filtered Document Object Model (DOM) elements as observations and performs tasks step-by-step, sequentially generating small programs based on the current observations. We use in-context learning, either benefiting from a single manually provided example, or an automatically generated example based on a successful zero-shot trial. We evaluate the proposed method on the MiniWob++ benchmark. With only one in-context example, our WebWISE method achieves similar or better performance than other methods that require many demonstrations or trials.
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Oct 06, 2023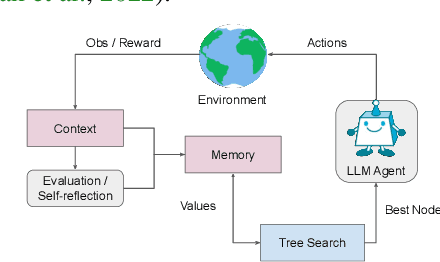
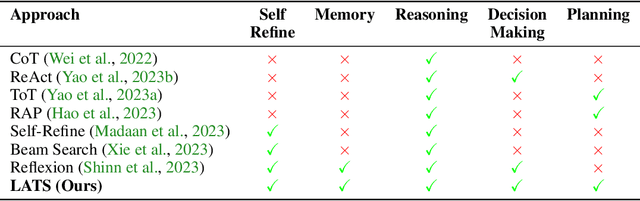
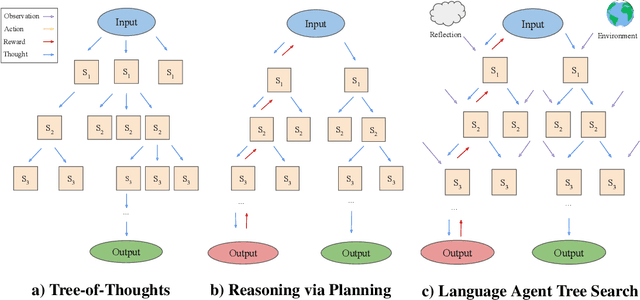
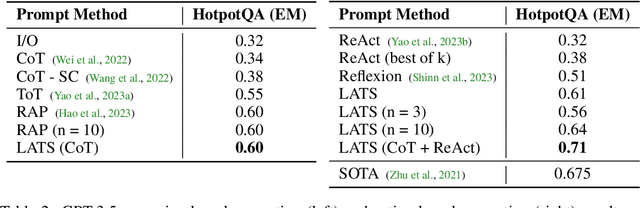
While large language models (LLMs) have demonstrated impressive performance on a range of decision-making tasks, they rely on simple acting processes and fall short of broad deployment as autonomous agents. We introduce LATS (Language Agent Tree Search), a general framework that synergizes the capabilities of LLMs in planning, acting, and reasoning. Drawing inspiration from Monte Carlo tree search in model-based reinforcement learning, LATS employs LLMs as agents, value functions, and optimizers, repurposing their latent strengths for enhanced decision-making. What is crucial in this method is the use of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that moves beyond the limitations of existing techniques. Our experimental evaluation across diverse domains, such as programming, HotPotQA, and WebShop, illustrates the applicability of LATS for both reasoning and acting. In particular, LATS achieves 94.4\% for programming on HumanEval with GPT-4 and an average score of 75.9 for web browsing on WebShop with GPT-3.5, demonstrating the effectiveness and generality of our method.