 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Reinforcement Learning with Verifiable Rewards via Randomly Selected Few-Shot Guidance
May 14, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has achieved great success in developing Large Language Models (LLMs) with chain-of-thought rollouts for many tasks such as math and coding. Nevertheless, RLVR struggles with sample efficiency on difficult problems where correct rollouts are hard to generate. Prior works propose to address this issue via demonstration-guided RLVR, i.e., to conduct Supervised FineTuning (SFT) when RL fails; however, SFT often requires a lot of data, which can be expensive to acquire. In this paper, we propose FEST, a FEw-ShoT demonstration-guided RLVR algorithm. It attains compelling results with only 128 demonstrations randomly selected from an SFT dataset. We find that three components are vital for the success: supervised signal, on-policy signal, and decaying weights on the few-shot SFT dataset to prevent overfitting from multiple-epoch training. On several benchmarks, FEST outperforms baselines with magnitudes less SFT data, even matching their performance with full dataset.
Autonomous Laparoscope Control through Unified Mechanics-Based Representation of Multimodal Intraoperative Information
May 06, 2026Laparoscope-holding robots can provide surgeons with a stable laparoscopic field of view (FOV) and reduce the burden on human assistants. To maintain an ideal intraoperative FOV, the robot must continuously adjust the laparoscope pose according to intraoperative information. However, intraoperative multimodal signals, such as position, force/torque, and images, differ markedly in physical meaning and units, making it difficult to build a unified representation and to generate control commands that can be used directly for laparoscope control. To address this issue, we propose a laparoscope-holding robot control method based on unified mechanics modeling of multimodal information. First, we design mapping strategies for multiple intraoperative sources, including position, force/torque, and images, and unify them into an equivalent-wrench representation in the operational space. Then, using a task-priority scheme, we inject the wrenches into the task space and the null space, respectively, and synthesize laparoscope control commands via task-priority projection, thereby achieving consistent representation and coordinated fusion of multimodal information within a single framework. Finally, taking the intraoperative remote center of motion (RCM) position, force/torque sensor readings, and laparoscopic images as examples, we construct an RCM-constraint wrench to enforce the RCM geometric constraint and reduce the contact force at the trocar site, a laparoscope-manipulation wrench to enable compliant dragging, and an instrument-tracking wrench to achieve autonomous visual tracking of the instruments. Experiments on a surgical phantom and in vivo porcine trials demonstrate that the proposed method supports multi-task operation, including compliant laparoscope manipulation and autonomous instrument tracking, while maintaining the RCM constraint and reducing sustained trocar-site loading.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
Latent Wasserstein Adversarial Imitation Learning
Mar 05, 2026Imitation Learning (IL) enables agents to mimic expert behavior by learning from demonstrations. However, traditional IL methods require large amounts of medium-to-high-quality demonstrations as well as actions of expert demonstrations, both of which are often unavailable. To reduce this need, we propose Latent Wasserstein Adversarial Imitation Learning (LWAIL), a novel adversarial imitation learning framework that focuses on state-only distribution matching. It benefits from the Wasserstein distance computed in a dynamics-aware latent space. This dynamics-aware latent space differs from prior work and is obtained via a pre-training stage, where we train the Intention Conditioned Value Function (ICVF) to capture a dynamics-aware structure of the state space using a small set of randomly generated state-only data. We show that this enhances the policy's understanding of state transitions, enabling the learning process to use only one or a few state-only expert episodes to achieve expert-level performance. Through experiments on multiple MuJoCo environments, we demonstrate that our method outperforms prior Wasserstein-based IL methods and prior adversarial IL methods, achieving better results across various tasks.
Visual Merit or Linguistic Crutch? A Close Look at DeepSeek-OCR
Jan 08, 2026DeepSeek-OCR utilizes an optical 2D mapping approach to achieve high-ratio vision-text compression, claiming to decode text tokens exceeding ten times the input visual tokens. While this suggests a promising solution for the LLM long-context bottleneck, we investigate a critical question: "Visual merit or linguistic crutch - which drives DeepSeek-OCR's performance?" By employing sentence-level and word-level semantic corruption, we isolate the model's intrinsic OCR capabilities from its language priors. Results demonstrate that without linguistic support, DeepSeek-OCR's performance plummets from approximately 90% to 20%. Comparative benchmarking against 13 baseline models reveals that traditional pipeline OCR methods exhibit significantly higher robustness to such semantic perturbations than end-to-end methods. Furthermore, we find that lower visual token counts correlate with increased reliance on priors, exacerbating hallucination risks. Context stress testing also reveals a total model collapse around 10,000 text tokens, suggesting that current optical compression techniques may paradoxically aggravate the long-context bottleneck. This study empirically defines DeepSeek-OCR's capability boundaries and offers essential insights for future optimizations of the vision-text compression paradigm. We release all data, results and scripts used in this study at https://github.com/dududuck00/DeepSeekOCR.
Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?
Apr 01, 2025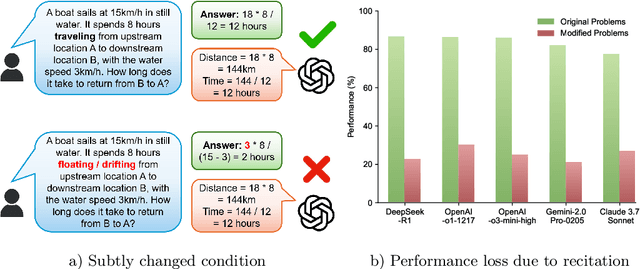
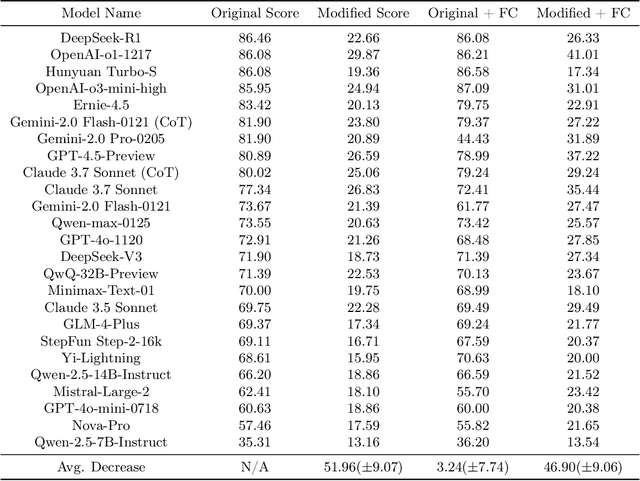

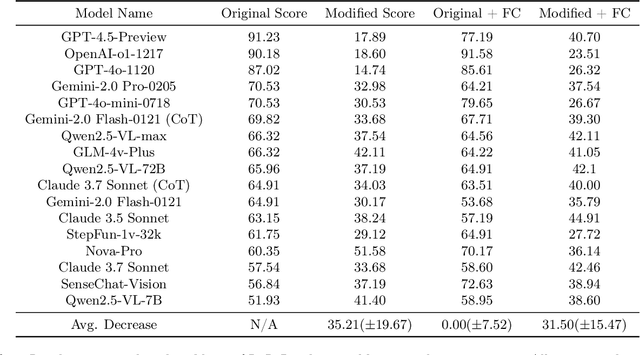
The rapid escalation from elementary school-level to frontier problems of the difficulty for LLM benchmarks in recent years have weaved a miracle for researchers that we are only inches away from surpassing human intelligence. However, is the LLMs' remarkable reasoning ability indeed comes from true intelligence by human standards, or are they simply reciting solutions witnessed during training at an Internet level? To study this problem, we propose RoR-Bench, a novel, multi-modal benchmark for detecting LLM's recitation behavior when asked simple reasoning problems but with conditions subtly shifted, and conduct empirical analysis on our benchmark. Surprisingly, we found existing cutting-edge LLMs unanimously exhibits extremely severe recitation behavior; by changing one phrase in the condition, top models such as OpenAI-o1 and DeepSeek-R1 can suffer $60\%$ performance loss on elementary school-level arithmetic and reasoning problems. Such findings are a wake-up call to the LLM community that compels us to re-evaluate the true intelligence level of cutting-edge LLMs.
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis
Mar 29, 2025Inductive program synthesis, or programming by example, requires synthesizing functions from input-output examples that generalize to unseen inputs. While large language model agents have shown promise in programming tasks guided by natural language, their ability to perform inductive program synthesis is underexplored. Existing evaluation protocols rely on static sets of examples and held-out tests, offering no feedback when synthesized functions are incorrect and failing to reflect real-world scenarios such as reverse engineering. We propose CodeARC, the Code Abstraction and Reasoning Challenge, a new evaluation framework where agents interact with a hidden target function by querying it with new inputs, synthesizing candidate functions, and iteratively refining their solutions using a differential testing oracle. This interactive setting encourages agents to perform function calls and self-correction based on feedback. We construct the first large-scale benchmark for general-purpose inductive program synthesis, featuring 1114 functions. Among 18 models evaluated, o3-mini performs best with a success rate of 52.7%, highlighting the difficulty of this task. Fine-tuning LLaMA-3.1-8B-Instruct on curated synthesis traces yields up to a 31% relative performance gain. CodeARC provides a more realistic and challenging testbed for evaluating LLM-based program synthesis and inductive reasoning.
LongReason: A Synthetic Long-Context Reasoning Benchmark via Context Expansion
Jan 25, 2025



Large language models (LLMs) have demonstrated remarkable progress in understanding long-context inputs. However, benchmarks for evaluating the long-context reasoning abilities of LLMs fall behind the pace. Existing benchmarks often focus on a narrow range of tasks or those that do not demand complex reasoning. To address this gap and enable a more comprehensive evaluation of the long-context reasoning capabilities of current LLMs, we propose a new synthetic benchmark, LongReason, which is constructed by synthesizing long-context reasoning questions from a varied set of short-context reasoning questions through context expansion. LongReason consists of 794 multiple-choice reasoning questions with diverse reasoning patterns across three task categories: reading comprehension, logical inference, and mathematical word problems. We evaluate 21 LLMs on LongReason, revealing that most models experience significant performance drops as context length increases. Our further analysis shows that even state-of-the-art LLMs still have significant room for improvement in providing robust reasoning across different tasks. We will open-source LongReason to support the comprehensive evaluation of LLMs' long-context reasoning capabilities.
Reinforcement Learning Gradients as Vitamin for Online Finetuning Decision Transformers
Oct 31, 2024



Decision Transformers have recently emerged as a new and compelling paradigm for offline Reinforcement Learning (RL), completing a trajectory in an autoregressive way. While improvements have been made to overcome initial shortcomings, online finetuning of decision transformers has been surprisingly under-explored. The widely adopted state-of-the-art Online Decision Transformer (ODT) still struggles when pretrained with low-reward offline data. In this paper, we theoretically analyze the online-finetuning of the decision transformer, showing that the commonly used Return-To-Go (RTG) that's far from the expected return hampers the online fine-tuning process. This problem, however, is well-addressed by the value function and advantage of standard RL algorithms. As suggested by our analysis, in our experiments, we hence find that simply adding TD3 gradients to the finetuning process of ODT effectively improves the online finetuning performance of ODT, especially if ODT is pretrained with low-reward offline data. These findings provide new directions to further improve decision transformers.
Natural Adversarial Patch Generation Method Based on Latent Diffusion Model
Dec 27, 2023Recently, some research show that deep neural networks are vulnerable to the adversarial attacks, the well-trainned samples or patches could be used to trick the neural network detector or human visual perception. However, these adversarial patches, with their conspicuous and unusual patterns, lack camouflage and can easily raise suspicion in the real world. To solve this problem, this paper proposed a novel adversarial patch method called the Latent Diffusion Patch (LDP), in which, a pretrained encoder is first designed to compress the natural images into a feature space with key characteristics. Then trains the diffusion model using the above feature space. Finally, explore the latent space of the pretrained diffusion model using the image denoising technology. It polishes the patches and images through the powerful natural abilities of diffusion models, making them more acceptable to the human visual system. Experimental results, both digital and physical worlds, show that LDPs achieve a visual subjectivity score of 87.3%, while still maintaining effective attack capabilities.