 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Ray Tracing for the Reconstruction of 3D Gaussian Splatting
Mar 24, 2026Ray-tracing-based 3D Gaussian splatting (3DGS) methods overcome the limitations of rasterization -- rigid pinhole camera assumptions, inaccurate shadows, and lack of native reflection or refraction -- but remain slower due to the cost of sorting all intersecting Gaussians along every ray. Moreover, existing ray-tracing methods still rely on rasterization-style approximations such as shadow mapping for relightable scenes, undermining the generality that ray tracing promises. We present a differentiable, sorting-free stochastic formulation for ray-traced 3DGS -- the first framework that uses stochastic ray tracing to both reconstruct and render standard and relightable 3DGS scenes. At its core is an unbiased Monte Carlo estimator for pixel-color gradients that evaluates only a small sampled subset of Gaussians per ray, bypassing the need for sorting. For standard 3DGS, our method matches the reconstruction quality and speed of rasterization-based 3DGS while substantially outperforming sorting-based ray tracing. For relightable 3DGS, the same stochastic estimator drives per-Gaussian shading with fully ray-traced shadow rays, delivering notably higher reconstruction fidelity than prior work.
A Vision-Language Foundation Model for Zero-shot Clinical Collaboration and Automated Concept Discovery in Dermatology
Feb 11, 2026Medical foundation models have shown promise in controlled benchmarks, yet widespread deployment remains hindered by reliance on task-specific fine-tuning. Here, we introduce DermFM-Zero, a dermatology vision-language foundation model trained via masked latent modelling and contrastive learning on over 4 million multimodal data points. We evaluated DermFM-Zero across 20 benchmarks spanning zero-shot diagnosis and multimodal retrieval, achieving state-of-the-art performance without task-specific adaptation. We further evaluated its zero-shot capabilities in three multinational reader studies involving over 1,100 clinicians. In primary care settings, AI assistance enabled general practitioners to nearly double their differential diagnostic accuracy across 98 skin conditions. In specialist settings, the model significantly outperformed board-certified dermatologists in multimodal skin cancer assessment. In collaborative workflows, AI assistance enabled non-experts to surpass unassisted experts while improving management appropriateness. Finally, we show that DermFM-Zero's latent representations are interpretable: sparse autoencoders unsupervisedly disentangle clinically meaningful concepts that outperform predefined-vocabulary approaches and enable targeted suppression of artifact-induced biases, enhancing robustness without retraining. These findings demonstrate that a foundation model can provide effective, safe, and transparent zero-shot clinical decision support.
PBIR-NIE: Glossy Object Capture under Non-Distant Lighting
Aug 13, 2024



Glossy objects present a significant challenge for 3D reconstruction from multi-view input images under natural lighting. In this paper, we introduce PBIR-NIE, an inverse rendering framework designed to holistically capture the geometry, material attributes, and surrounding illumination of such objects. We propose a novel parallax-aware non-distant environment map as a lightweight and efficient lighting representation, accurately modeling the near-field background of the scene, which is commonly encountered in real-world capture setups. This feature allows our framework to accommodate complex parallax effects beyond the capabilities of standard infinite-distance environment maps. Our method optimizes an underlying signed distance field (SDF) through physics-based differentiable rendering, seamlessly connecting surface gradients between a triangle mesh and the SDF via neural implicit evolution (NIE). To address the intricacies of highly glossy BRDFs in differentiable rendering, we integrate the antithetic sampling algorithm to mitigate variance in the Monte Carlo gradient estimator. Consequently, our framework exhibits robust capabilities in handling glossy object reconstruction, showcasing superior quality in geometry, relighting, and material estimation.
NeRF as Non-Distant Environment Emitter in Physics-based Inverse Rendering
Feb 07, 2024



Physics-based inverse rendering aims to jointly optimize shape, materials, and lighting from captured 2D images. Here lighting is an important part of achieving faithful light transport simulation. While the environment map is commonly used as the lighting model in inverse rendering, we show that its distant lighting assumption leads to spatial invariant lighting, which can be an inaccurate approximation in real-world inverse rendering. We propose to use NeRF as a spatially varying environment lighting model and build an inverse rendering pipeline using NeRF as the non-distant environment emitter. By comparing our method with the environment map on real and synthetic datasets, we show that our NeRF-based emitter models the scene lighting more accurately and leads to more accurate inverse rendering. Project page and video: https://nerfemitterpbir.github.io/.
REFORM: Removing False Correlation in Multi-level Interaction for CTR Prediction
Sep 26, 2023Click-through rate (CTR) prediction is a critical task in online advertising and recommendation systems, as accurate predictions are essential for user targeting and personalized recommendations. Most recent cutting-edge methods primarily focus on investigating complex implicit and explicit feature interactions. However, these methods neglect the issue of false correlations caused by confounding factors or selection bias. This problem is further magnified by the complexity and redundancy of these interactions. We propose a CTR prediction framework that removes false correlation in multi-level feature interaction, termed REFORM. The proposed REFORM framework exploits a wide range of multi-level high-order feature representations via a two-stream stacked recurrent structure while eliminating false correlations. The framework has two key components: I. The multi-level stacked recurrent (MSR) structure enables the model to efficiently capture diverse nonlinear interactions from feature spaces of different levels, and the richer representations lead to enhanced CTR prediction accuracy. II. The false correlation elimination (FCE) module further leverages Laplacian kernel mapping and sample reweighting methods to eliminate false correlations concealed within the multi-level features, allowing the model to focus on the true causal effects. Extensive experiments based on four challenging CTR datasets and our production dataset demonstrate that the proposed REFORM model achieves state-of-the-art performance. Codes, models and our dataset will be released at https://github.com/yansuoyuli/REFORM.
An Improved NeuMIP with Better Accuracy
Jul 19, 2023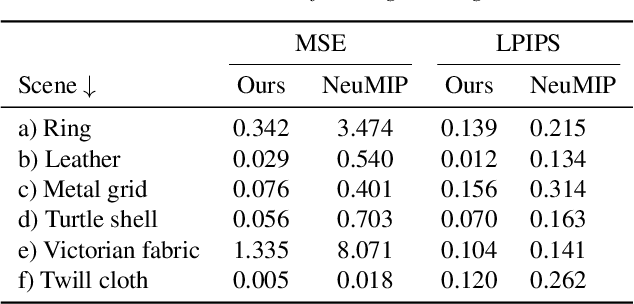



Neural reflectance models are capable of accurately reproducing the spatially-varying appearance of many real-world materials at different scales. However, existing methods have difficulties handling highly glossy materials. To address this problem, we introduce a new neural reflectance model which, compared with existing methods, better preserves not only specular highlights but also fine-grained details. To this end, we enhance the neural network performance by encoding input data to frequency space, inspired by NeRF, to better preserve the details. Furthermore, we introduce a gradient-based loss and employ it in multiple stages, adaptive to the progress of the learning phase. Lastly, we utilize an optional extension to the decoder network using the Inception module for more accurate yet costly performance. We demonstrate the effectiveness of our method using a variety of synthetic and real examples.
Efficient Prediction of Peptide Self-assembly through Sequential and Graphical Encoding
Jul 17, 2023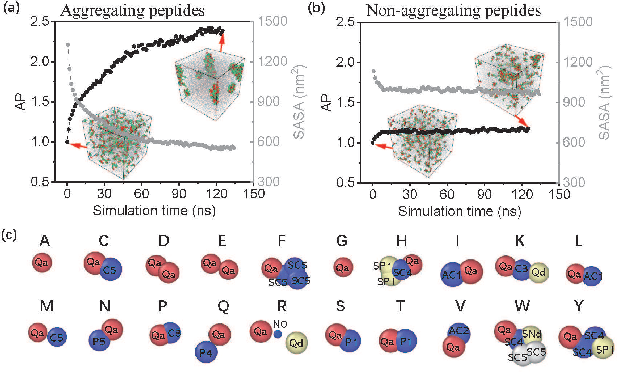
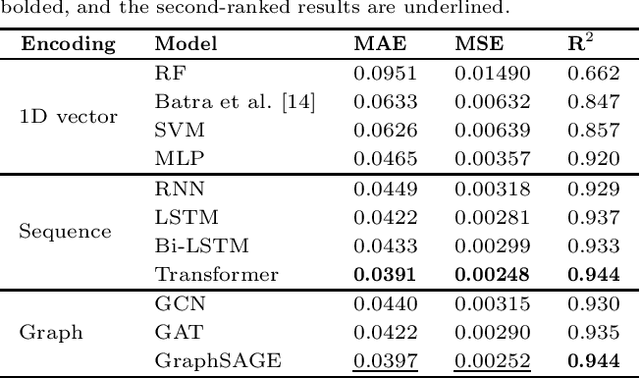
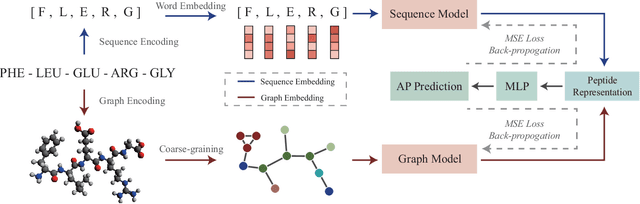
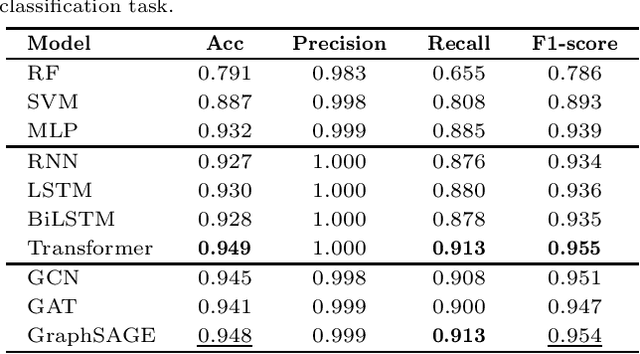
In recent years, there has been an explosion of research on the application of deep learning to the prediction of various peptide properties, due to the significant development and market potential of peptides. Molecular dynamics has enabled the efficient collection of large peptide datasets, providing reliable training data for deep learning. However, the lack of systematic analysis of the peptide encoding, which is essential for AI-assisted peptide-related tasks, makes it an urgent problem to be solved for the improvement of prediction accuracy. To address this issue, we first collect a high-quality, colossal simulation dataset of peptide self-assembly containing over 62,000 samples generated by coarse-grained molecular dynamics (CGMD). Then, we systematically investigate the effect of peptide encoding of amino acids into sequences and molecular graphs using state-of-the-art sequential (i.e., RNN, LSTM, and Transformer) and structural deep learning models (i.e., GCN, GAT, and GraphSAGE), on the accuracy of peptide self-assembly prediction, an essential physiochemical process prior to any peptide-related applications. Extensive benchmarking studies have proven Transformer to be the most powerful sequence-encoding-based deep learning model, pushing the limit of peptide self-assembly prediction to decapeptides. In summary, this work provides a comprehensive benchmark analysis of peptide encoding with advanced deep learning models, serving as a guide for a wide range of peptide-related predictions such as isoelectric points, hydration free energy, etc.
A Novel Multi-Task Model Imitating Dermatologists for Accurate Differential Diagnosis of Skin Diseases in Clinical Images
Jul 17, 2023
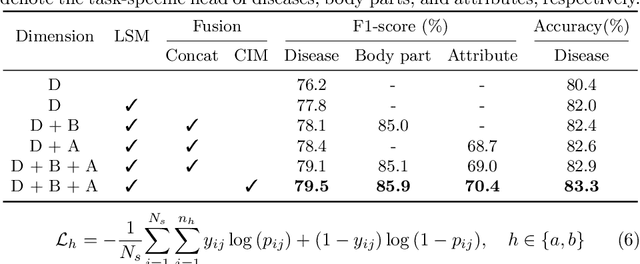
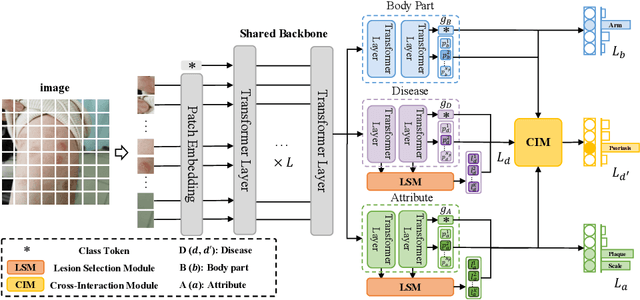
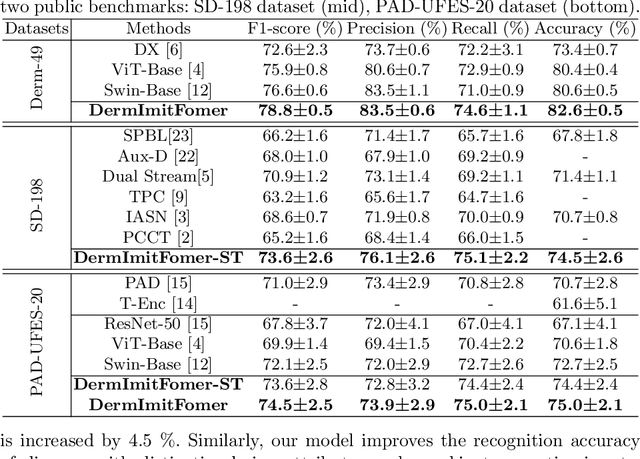
Skin diseases are among the most prevalent health issues, and accurate computer-aided diagnosis methods are of importance for both dermatologists and patients. However, most of the existing methods overlook the essential domain knowledge required for skin disease diagnosis. A novel multi-task model, namely DermImitFormer, is proposed to fill this gap by imitating dermatologists' diagnostic procedures and strategies. Through multi-task learning, the model simultaneously predicts body parts and lesion attributes in addition to the disease itself, enhancing diagnosis accuracy and improving diagnosis interpretability. The designed lesion selection module mimics dermatologists' zoom-in action, effectively highlighting the local lesion features from noisy backgrounds. Additionally, the presented cross-interaction module explicitly models the complicated diagnostic reasoning between body parts, lesion attributes, and diseases. To provide a more robust evaluation of the proposed method, a large-scale clinical image dataset of skin diseases with significantly more cases than existing datasets has been established. Extensive experiments on three different datasets consistently demonstrate the state-of-the-art recognition performance of the proposed approach.
PSDR-Room: Single Photo to Scene using Differentiable Rendering
Jul 06, 2023



A 3D digital scene contains many components: lights, materials and geometries, interacting to reach the desired appearance. Staging such a scene is time-consuming and requires both artistic and technical skills. In this work, we propose PSDR-Room, a system allowing to optimize lighting as well as the pose and materials of individual objects to match a target image of a room scene, with minimal user input. To this end, we leverage a recent path-space differentiable rendering approach that provides unbiased gradients of the rendering with respect to geometry, lighting, and procedural materials, allowing us to optimize all of these components using gradient descent to visually match the input photo appearance. We use recent single-image scene understanding methods to initialize the optimization and search for appropriate 3D models and materials. We evaluate our method on real photographs of indoor scenes and demonstrate the editability of the resulting scene components.
Neural-PBIR Reconstruction of Shape, Material, and Illumination
Apr 26, 2023Reconstructing the shape and spatially varying surface appearances of a physical-world object as well as its surrounding illumination based on 2D images (e.g., photographs) of the object has been a long-standing problem in computer vision and graphics. In this paper, we introduce a robust object reconstruction pipeline combining neural based object reconstruction and physics-based inverse rendering (PBIR). Specifically, our pipeline firstly leverages a neural stage to produce high-quality but potentially imperfect predictions of object shape, reflectance, and illumination. Then, in the later stage, initialized by the neural predictions, we perform PBIR to refine the initial results and obtain the final high-quality reconstruction. Experimental results demonstrate our pipeline significantly outperforms existing reconstruction methods quality-wise and performance-wise.