 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeatherDiffusion: Weather-Guided Diffusion Model for Forward and Inverse Rendering
Aug 09, 2025Forward and inverse rendering have emerged as key techniques for enabling understanding and reconstruction in the context of autonomous driving (AD). However, complex weather and illumination pose great challenges to this task. The emergence of large diffusion models has shown promise in achieving reasonable results through learning from 2D priors, but these models are difficult to control and lack robustness. In this paper, we introduce WeatherDiffusion, a diffusion-based framework for forward and inverse rendering on AD scenes with various weather and lighting conditions. Our method enables authentic estimation of material properties, scene geometry, and lighting, and further supports controllable weather and illumination editing through the use of predicted intrinsic maps guided by text descriptions. We observe that different intrinsic maps should correspond to different regions of the original image. Based on this observation, we propose Intrinsic map-aware attention (MAA) to enable high-quality inverse rendering. Additionally, we introduce a synthetic dataset (\ie WeatherSynthetic) and a real-world dataset (\ie WeatherReal) for forward and inverse rendering on AD scenes with diverse weather and lighting. Extensive experiments show that our WeatherDiffusion outperforms state-of-the-art methods on several benchmarks. Moreover, our method demonstrates significant value in downstream tasks for AD, enhancing the robustness of object detection and image segmentation in challenging weather scenarios.
IntrinsicEdit: Precise generative image manipulation in intrinsic space
May 15, 2025



Generative diffusion models have advanced image editing with high-quality results and intuitive interfaces such as prompts and semantic drawing. However, these interfaces lack precise control, and the associated methods typically specialize on a single editing task. We introduce a versatile, generative workflow that operates in an intrinsic-image latent space, enabling semantic, local manipulation with pixel precision for a range of editing operations. Building atop the RGB-X diffusion framework, we address key challenges of identity preservation and intrinsic-channel entanglement. By incorporating exact diffusion inversion and disentangled channel manipulation, we enable precise, efficient editing with automatic resolution of global illumination effects -- all without additional data collection or model fine-tuning. We demonstrate state-of-the-art performance across a variety of tasks on complex images, including color and texture adjustments, object insertion and removal, global relighting, and their combinations.
WorldPrompter: Traversable Text-to-Scene Generation
Apr 02, 2025



Scene-level 3D generation is a challenging research topic, with most existing methods generating only partial scenes and offering limited navigational freedom. We introduce WorldPrompter, a novel generative pipeline for synthesizing traversable 3D scenes from text prompts. We leverage panoramic videos as an intermediate representation to model the 360{\deg} details of a scene. WorldPrompter incorporates a conditional 360{\deg} panoramic video generator, capable of producing a 128-frame video that simulates a person walking through and capturing a virtual environment. The resulting video is then reconstructed as Gaussian splats by a fast feedforward 3D reconstructor, enabling a true walkable experience within the 3D scene. Experiments demonstrate that our panoramic video generation model achieves convincing view consistency across frames, enabling high-quality panoramic Gaussian splat reconstruction and facilitating traversal over an area of the scene. Qualitative and quantitative results also show it outperforms the state-of-the-art 360{\deg} video generators and 3D scene generation models.
MaterialPicker: Multi-Modal Material Generation with Diffusion Transformers
Dec 04, 2024



High-quality material generation is key for virtual environment authoring and inverse rendering. We propose MaterialPicker, a multi-modal material generator leveraging a Diffusion Transformer (DiT) architecture, improving and simplifying the creation of high-quality materials from text prompts and/or photographs. Our method can generate a material based on an image crop of a material sample, even if the captured surface is distorted, viewed at an angle or partially occluded, as is often the case in photographs of natural scenes. We further allow the user to specify a text prompt to provide additional guidance for the generation. We finetune a pre-trained DiT-based video generator into a material generator, where each material map is treated as a frame in a video sequence. We evaluate our approach both quantitatively and qualitatively and show that it enables more diverse material generation and better distortion correction than previous work.
RNG: Relightable Neural Gaussians
Sep 29, 2024
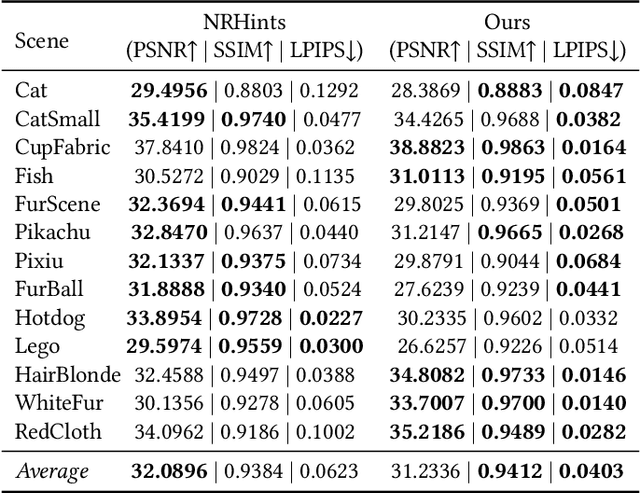
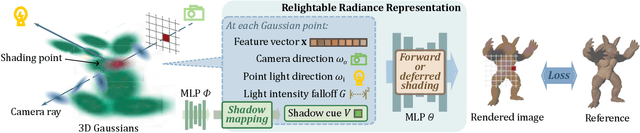
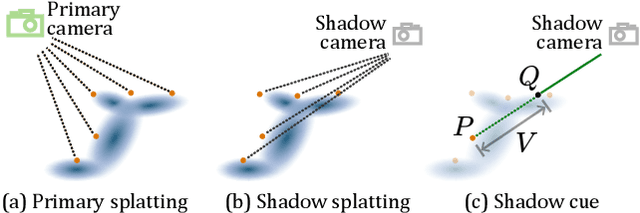
3D Gaussian Splatting (3DGS) has shown its impressive power in novel view synthesis. However, creating relightable 3D assets, especially for objects with ill-defined shapes (e.g., fur), is still a challenging task. For these scenes, the decomposition between the light, geometry, and material is more ambiguous, as neither the surface constraints nor the analytical shading model hold. To address this issue, we propose RNG, a novel representation of relightable neural Gaussians, enabling the relighting of objects with both hard surfaces or fluffy boundaries. We avoid any assumptions in the shading model but maintain feature vectors, which can be further decoded by an MLP into colors, in each Gaussian point. Following prior work, we utilize a point light to reduce the ambiguity and introduce a shadow-aware condition to the network. We additionally propose a depth refinement network to help the shadow computation under the 3DGS framework, leading to better shadow effects under point lights. Furthermore, to avoid the blurriness brought by the alpha-blending in 3DGS, we design a hybrid forward-deferred optimization strategy. As a result, we achieve about $20\times$ faster in training and about $600\times$ faster in rendering than prior work based on neural radiance fields, with $60$ frames per second on an RTX4090.
PBIR-NIE: Glossy Object Capture under Non-Distant Lighting
Aug 13, 2024



Glossy objects present a significant challenge for 3D reconstruction from multi-view input images under natural lighting. In this paper, we introduce PBIR-NIE, an inverse rendering framework designed to holistically capture the geometry, material attributes, and surrounding illumination of such objects. We propose a novel parallax-aware non-distant environment map as a lightweight and efficient lighting representation, accurately modeling the near-field background of the scene, which is commonly encountered in real-world capture setups. This feature allows our framework to accommodate complex parallax effects beyond the capabilities of standard infinite-distance environment maps. Our method optimizes an underlying signed distance field (SDF) through physics-based differentiable rendering, seamlessly connecting surface gradients between a triangle mesh and the SDF via neural implicit evolution (NIE). To address the intricacies of highly glossy BRDFs in differentiable rendering, we integrate the antithetic sampling algorithm to mitigate variance in the Monte Carlo gradient estimator. Consequently, our framework exhibits robust capabilities in handling glossy object reconstruction, showcasing superior quality in geometry, relighting, and material estimation.
Fast and Uncertainty-Aware SVBRDF Recovery from Multi-View Capture using Frequency Domain Analysis
Jun 25, 2024



Relightable object acquisition is a key challenge in simplifying digital asset creation. Complete reconstruction of an object typically requires capturing hundreds to thousands of photographs under controlled illumination, with specialized equipment. The recent progress in differentiable rendering improved the quality and accessibility of inverse rendering optimization. Nevertheless, under uncontrolled illumination and unstructured viewpoints, there is no guarantee that the observations contain enough information to reconstruct the appearance properties of the captured object. We thus propose to consider the acquisition process from a signal-processing perspective. Given an object's geometry and a lighting environment, we estimate the properties of the materials on the object's surface in seconds. We do so by leveraging frequency domain analysis, considering the recovery of material properties as a deconvolution, enabling fast error estimation. We then quantify the uncertainty of the estimation, based on the available data, highlighting the areas for which priors or additional samples would be required for improved acquisition quality. We compare our approach to previous work and quantitatively evaluate our results, showing similar quality as previous work in a fraction of the time, and providing key information about the certainty of the results.
RGB$\leftrightarrow$X: Image decomposition and synthesis using material- and lighting-aware diffusion models
May 01, 2024



The three areas of realistic forward rendering, per-pixel inverse rendering, and generative image synthesis may seem like separate and unrelated sub-fields of graphics and vision. However, recent work has demonstrated improved estimation of per-pixel intrinsic channels (albedo, roughness, metallicity) based on a diffusion architecture; we call this the RGB$\rightarrow$X problem. We further show that the reverse problem of synthesizing realistic images given intrinsic channels, X$\rightarrow$RGB, can also be addressed in a diffusion framework. Focusing on the image domain of interior scenes, we introduce an improved diffusion model for RGB$\rightarrow$X, which also estimates lighting, as well as the first diffusion X$\rightarrow$RGB model capable of synthesizing realistic images from (full or partial) intrinsic channels. Our X$\rightarrow$RGB model explores a middle ground between traditional rendering and generative models: we can specify only certain appearance properties that should be followed, and give freedom to the model to hallucinate a plausible version of the rest. This flexibility makes it possible to use a mix of heterogeneous training datasets, which differ in the available channels. We use multiple existing datasets and extend them with our own synthetic and real data, resulting in a model capable of extracting scene properties better than previous work and of generating highly realistic images of interior scenes.
Relightable Neural Assets
Dec 14, 2023



High-fidelity 3D assets with materials composed of fibers (including hair), complex layered material shaders, or fine scattering geometry are ubiquitous in high-end realistic rendering applications. Rendering such models is computationally expensive due to heavy shaders and long scattering paths. Moreover, implementing the shading and scattering models is non-trivial and has to be done not only in the 3D content authoring software (which is necessarily complex), but also in all downstream rendering solutions. For example, web and mobile viewers for complex 3D assets are desirable, but frequently cannot support the full shading complexity allowed by the authoring application. Our goal is to design a neural representation for 3D assets with complex shading that supports full relightability and full integration into existing renderers. We provide an end-to-end shading solution at the first intersection of a ray with the underlying geometry. All shading and scattering is precomputed and included in the neural asset; no multiple scattering paths need to be traced, and no complex shading models need to be implemented to render our assets, beyond a single neural architecture. We combine an MLP decoder with a feature grid. Shading consists of querying a feature vector, followed by an MLP evaluation producing the final reflectance value. Our method provides high-fidelity shading, close to the ground-truth Monte Carlo estimate even at close-up views. We believe our neural assets could be used in practical renderers, providing significant speed-ups and simplifying renderer implementations.
PhotoMat: A Material Generator Learned from Single Flash Photos
May 23, 2023
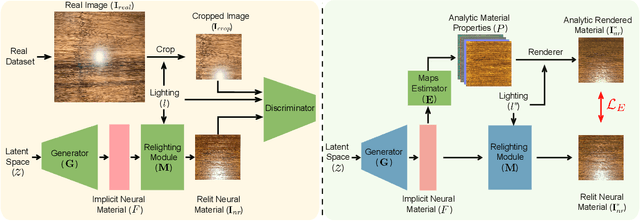


Authoring high-quality digital materials is key to realism in 3D rendering. Previous generative models for materials have been trained exclusively on synthetic data; such data is limited in availability and has a visual gap to real materials. We circumvent this limitation by proposing PhotoMat: the first material generator trained exclusively on real photos of material samples captured using a cell phone camera with flash. Supervision on individual material maps is not available in this setting. Instead, we train a generator for a neural material representation that is rendered with a learned relighting module to create arbitrarily lit RGB images; these are compared against real photos using a discriminator. We then train a material maps estimator to decode material reflectance properties from the neural material representation. We train PhotoMat with a new dataset of 12,000 material photos captured with handheld phone cameras under flash lighting. We demonstrate that our generated materials have better visual quality than previous material generators trained on synthetic data. Moreover, we can fit analytical material models to closely match these generated neural materials, thus allowing for further editing and use in 3D rendering.