 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Importance Sampling of Many Lights
May 16, 2025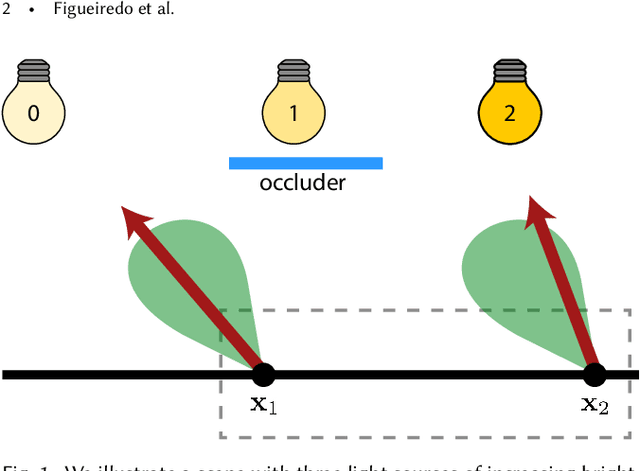
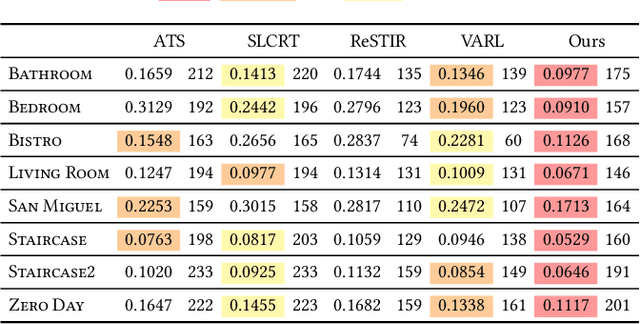

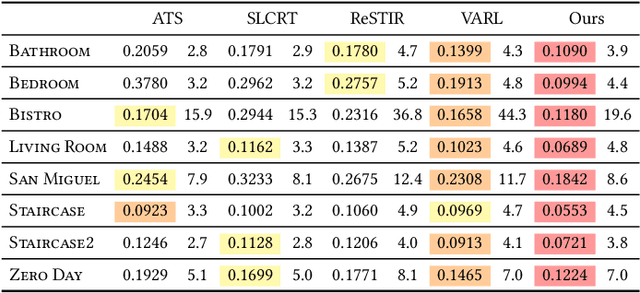
We propose a neural approach for estimating spatially varying light selection distributions to improve importance sampling in Monte Carlo rendering, particularly for complex scenes with many light sources. Our method uses a neural network to predict the light selection distribution at each shading point based on local information, trained by minimizing the KL-divergence between the learned and target distributions in an online manner. To efficiently manage hundreds or thousands of lights, we integrate our neural approach with light hierarchy techniques, where the network predicts cluster-level distributions and existing methods sample lights within clusters. Additionally, we introduce a residual learning strategy that leverages initial distributions from existing techniques, accelerating convergence during training. Our method achieves superior performance across diverse and challenging scenes.
RI3D: Few-Shot Gaussian Splatting With Repair and Inpainting Diffusion Priors
Mar 13, 2025



In this paper, we propose RI3D, a novel 3DGS-based approach that harnesses the power of diffusion models to reconstruct high-quality novel views given a sparse set of input images. Our key contribution is separating the view synthesis process into two tasks of reconstructing visible regions and hallucinating missing regions, and introducing two personalized diffusion models, each tailored to one of these tasks. Specifically, one model ('repair') takes a rendered image as input and predicts the corresponding high-quality image, which in turn is used as a pseudo ground truth image to constrain the optimization. The other model ('inpainting') primarily focuses on hallucinating details in unobserved areas. To integrate these models effectively, we introduce a two-stage optimization strategy: the first stage reconstructs visible areas using the repair model, and the second stage reconstructs missing regions with the inpainting model while ensuring coherence through further optimization. Moreover, we augment the optimization with a novel Gaussian initialization method that obtains per-image depth by combining 3D-consistent and smooth depth with highly detailed relative depth. We demonstrate that by separating the process into two tasks and addressing them with the repair and inpainting models, we produce results with detailed textures in both visible and missing regions that outperform state-of-the-art approaches on a diverse set of scenes with extremely sparse inputs.
PanoDreamer: 3D Panorama Synthesis from a Single Image
Dec 06, 2024



In this paper, we present PanoDreamer, a novel method for producing a coherent 360$^\circ$ 3D scene from a single input image. Unlike existing methods that generate the scene sequentially, we frame the problem as single-image panorama and depth estimation. Once the coherent panoramic image and its corresponding depth are obtained, the scene can be reconstructed by inpainting the small occluded regions and projecting them into 3D space. Our key contribution is formulating single-image panorama and depth estimation as two optimization tasks and introducing alternating minimization strategies to effectively solve their objectives. We demonstrate that our approach outperforms existing techniques in single-image 360$^\circ$ scene reconstruction in terms of consistency and overall quality.
Analyzing and Improving the Skin Tone Consistency and Bias in Implicit 3D Relightable Face Generators
Nov 18, 2024With the advances in generative adversarial networks (GANs) and neural rendering, 3D relightable face generation has received significant attention. Among the existing methods, a particularly successful technique uses an implicit lighting representation and generates relit images through the product of synthesized albedo and light-dependent shading images. While this approach produces high-quality results with intricate shading details, it often has difficulty producing relit images with consistent skin tones, particularly when the lighting condition is extracted from images of individuals with dark skin. Additionally, this technique is biased towards producing albedo images with lighter skin tones. Our main observation is that this problem is rooted in the biased spherical harmonics (SH) coefficients, used during training. Following this observation, we conduct an analysis and demonstrate that the bias appears not only in band 0 (DC term), but also in the other bands of the estimated SH coefficients. We then propose a simple, but effective, strategy to mitigate the problem. Specifically, we normalize the SH coefficients by their DC term to eliminate the inherent magnitude bias, while statistically align the coefficients in the other bands to alleviate the directional bias. We also propose a scaling strategy to match the distribution of illumination magnitude in the generated images with the training data. Through extensive experiments, we demonstrate the effectiveness of our solution in increasing the skin tone consistency and mitigating bias.
CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Mar 28, 2024The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
ReShader: View-Dependent Highlights for Single Image View-Synthesis
Sep 19, 2023



In recent years, novel view synthesis from a single image has seen significant progress thanks to the rapid advancements in 3D scene representation and image inpainting techniques. While the current approaches are able to synthesize geometrically consistent novel views, they often do not handle the view-dependent effects properly. Specifically, the highlights in their synthesized images usually appear to be glued to the surfaces, making the novel views unrealistic. To address this major problem, we make a key observation that the process of synthesizing novel views requires changing the shading of the pixels based on the novel camera, and moving them to appropriate locations. Therefore, we propose to split the view synthesis process into two independent tasks of pixel reshading and relocation. During the reshading process, we take the single image as the input and adjust its shading based on the novel camera. This reshaded image is then used as the input to an existing view synthesis method to relocate the pixels and produce the final novel view image. We propose to use a neural network to perform reshading and generate a large set of synthetic input-reshaded pairs to train our network. We demonstrate that our approach produces plausible novel view images with realistic moving highlights on a variety of real world scenes.
PhotoMat: A Material Generator Learned from Single Flash Photos
May 23, 2023
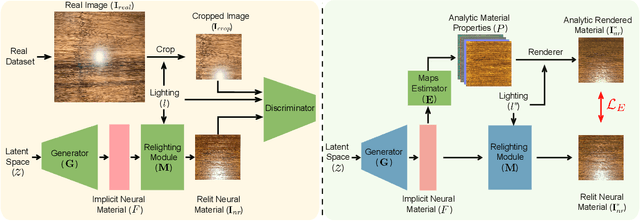


Authoring high-quality digital materials is key to realism in 3D rendering. Previous generative models for materials have been trained exclusively on synthetic data; such data is limited in availability and has a visual gap to real materials. We circumvent this limitation by proposing PhotoMat: the first material generator trained exclusively on real photos of material samples captured using a cell phone camera with flash. Supervision on individual material maps is not available in this setting. Instead, we train a generator for a neural material representation that is rendered with a learned relighting module to create arbitrarily lit RGB images; these are compared against real photos using a discriminator. We then train a material maps estimator to decode material reflectance properties from the neural material representation. We train PhotoMat with a new dataset of 12,000 material photos captured with handheld phone cameras under flash lighting. We demonstrate that our generated materials have better visual quality than previous material generators trained on synthetic data. Moreover, we can fit analytical material models to closely match these generated neural materials, thus allowing for further editing and use in 3D rendering.
Implicit View-Time Interpolation of Stereo Videos using Multi-Plane Disparities and Non-Uniform Coordinates
Mar 30, 2023


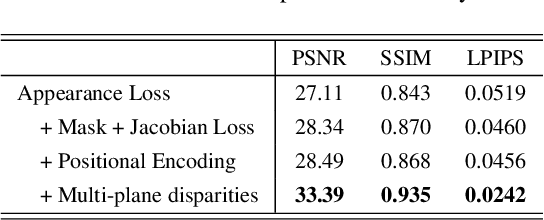
In this paper, we propose an approach for view-time interpolation of stereo videos. Specifically, we build upon X-Fields that approximates an interpolatable mapping between the input coordinates and 2D RGB images using a convolutional decoder. Our main contribution is to analyze and identify the sources of the problems with using X-Fields in our application and propose novel techniques to overcome these challenges. Specifically, we observe that X-Fields struggles to implicitly interpolate the disparities for large baseline cameras. Therefore, we propose multi-plane disparities to reduce the spatial distance of the objects in the stereo views. Moreover, we propose non-uniform time coordinates to handle the non-linear and sudden motion spikes in videos. We additionally introduce several simple, but important, improvements over X-Fields. We demonstrate that our approach is able to produce better results than the state of the art, while running in near real-time rates and having low memory and storage costs.
Frame Interpolation for Dynamic Scenes with Implicit Flow Encoding
Sep 27, 2022
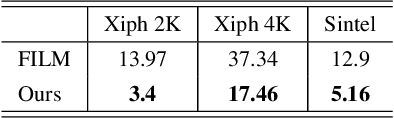
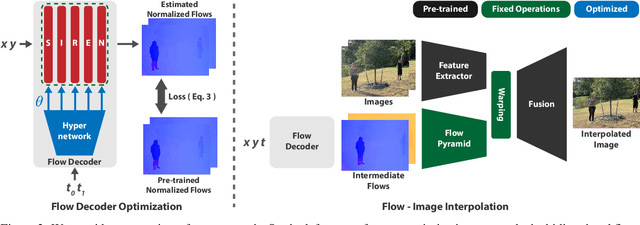
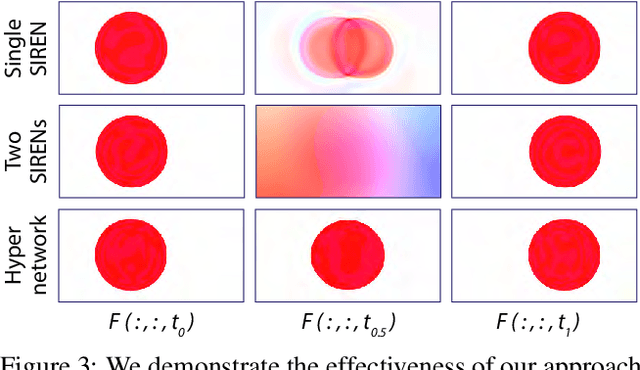
In this paper, we propose an algorithm to interpolate between a pair of images of a dynamic scene. While in the past years significant progress in frame interpolation has been made, current approaches are not able to handle images with brightness and illumination changes, which are common even when the images are captured shortly apart. We propose to address this problem by taking advantage of the existing optical flow methods that are highly robust to the variations in the illumination. Specifically, using the bidirectional flows estimated using an existing pre-trained flow network, we predict the flows from an intermediate frame to the two input images. To do this, we propose to encode the bidirectional flows into a coordinate-based network, powered by a hypernetwork, to obtain a continuous representation of the flow across time. Once we obtain the estimated flows, we use them within an existing blending network to obtain the final intermediate frame. Through extensive experiments, we demonstrate that our approach is able to produce significantly better results than state-of-the-art frame interpolation algorithms.
Multi-Stage Raw Video Denoising with Adversarial Loss and Gradient Mask
Mar 05, 2021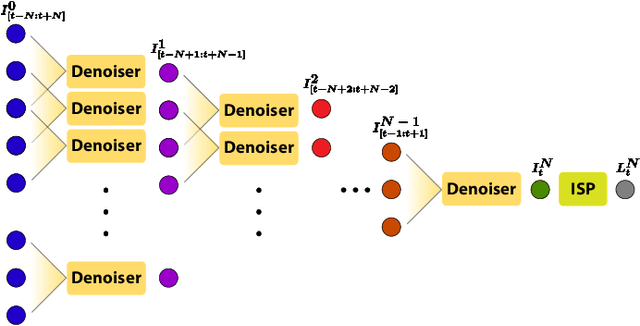
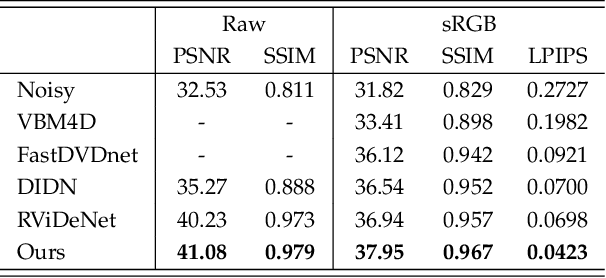

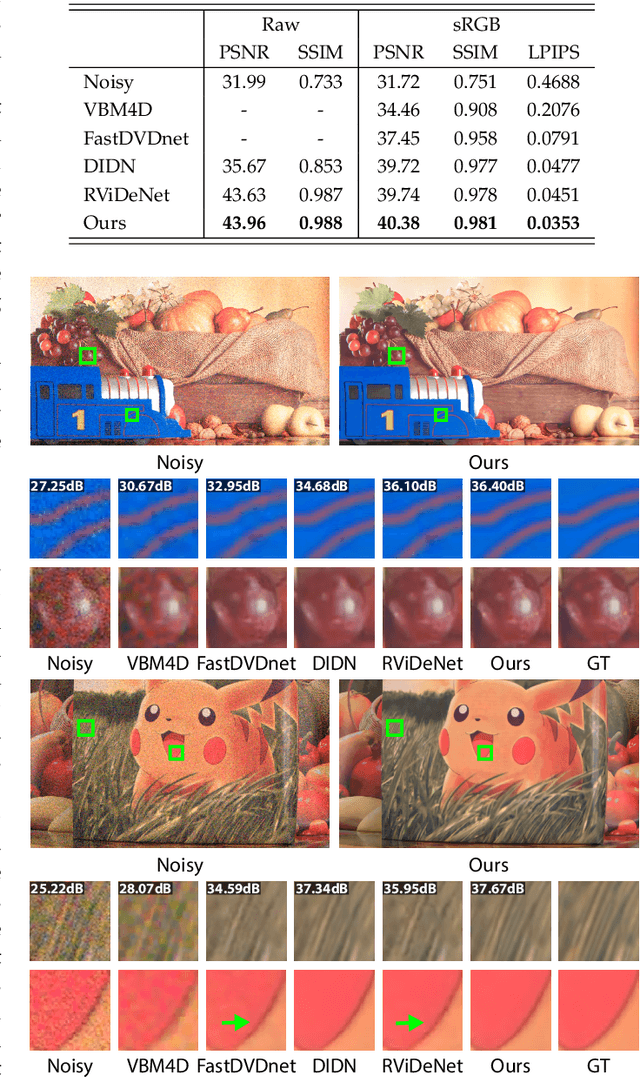
In this paper, we propose a learning-based approach for denoising raw videos captured under low lighting conditions. We propose to do this by first explicitly aligning the neighboring frames to the current frame using a convolutional neural network (CNN). We then fuse the registered frames using another CNN to obtain the final denoised frame. To avoid directly aligning the temporally distant frames, we perform the two processes of alignment and fusion in multiple stages. Specifically, at each stage, we perform the denoising process on three consecutive input frames to generate the intermediate denoised frames which are then passed as the input to the next stage. By performing the process in multiple stages, we can effectively utilize the information of neighboring frames without directly aligning the temporally distant frames. We train our multi-stage system using an adversarial loss with a conditional discriminator. Specifically, we condition the discriminator on a soft gradient mask to prevent introducing high-frequency artifacts in smooth regions. We show that our system is able to produce temporally coherent videos with realistic details. Furthermore, we demonstrate through extensive experiments that our approach outperforms state-of-the-art image and video denoising methods both numerically and visually.