 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRI3D: Few-Shot Gaussian Splatting With Repair and Inpainting Diffusion Priors
Mar 13, 2025



In this paper, we propose RI3D, a novel 3DGS-based approach that harnesses the power of diffusion models to reconstruct high-quality novel views given a sparse set of input images. Our key contribution is separating the view synthesis process into two tasks of reconstructing visible regions and hallucinating missing regions, and introducing two personalized diffusion models, each tailored to one of these tasks. Specifically, one model ('repair') takes a rendered image as input and predicts the corresponding high-quality image, which in turn is used as a pseudo ground truth image to constrain the optimization. The other model ('inpainting') primarily focuses on hallucinating details in unobserved areas. To integrate these models effectively, we introduce a two-stage optimization strategy: the first stage reconstructs visible areas using the repair model, and the second stage reconstructs missing regions with the inpainting model while ensuring coherence through further optimization. Moreover, we augment the optimization with a novel Gaussian initialization method that obtains per-image depth by combining 3D-consistent and smooth depth with highly detailed relative depth. We demonstrate that by separating the process into two tasks and addressing them with the repair and inpainting models, we produce results with detailed textures in both visible and missing regions that outperform state-of-the-art approaches on a diverse set of scenes with extremely sparse inputs.
PanoDreamer: 3D Panorama Synthesis from a Single Image
Dec 06, 2024



In this paper, we present PanoDreamer, a novel method for producing a coherent 360$^\circ$ 3D scene from a single input image. Unlike existing methods that generate the scene sequentially, we frame the problem as single-image panorama and depth estimation. Once the coherent panoramic image and its corresponding depth are obtained, the scene can be reconstructed by inpainting the small occluded regions and projecting them into 3D space. Our key contribution is formulating single-image panorama and depth estimation as two optimization tasks and introducing alternating minimization strategies to effectively solve their objectives. We demonstrate that our approach outperforms existing techniques in single-image 360$^\circ$ scene reconstruction in terms of consistency and overall quality.
WaSt-3D: Wasserstein-2 Distance for Scene-to-Scene Stylization on 3D Gaussians
Sep 26, 2024



While style transfer techniques have been well-developed for 2D image stylization, the extension of these methods to 3D scenes remains relatively unexplored. Existing approaches demonstrate proficiency in transferring colors and textures but often struggle with replicating the geometry of the scenes. In our work, we leverage an explicit Gaussian Splatting (GS) representation and directly match the distributions of Gaussians between style and content scenes using the Earth Mover's Distance (EMD). By employing the entropy-regularized Wasserstein-2 distance, we ensure that the transformation maintains spatial smoothness. Additionally, we decompose the scene stylization problem into smaller chunks to enhance efficiency. This paradigm shift reframes stylization from a pure generative process driven by latent space losses to an explicit matching of distributions between two Gaussian representations. Our method achieves high-resolution 3D stylization by faithfully transferring details from 3D style scenes onto the content scene. Furthermore, WaSt-3D consistently delivers results across diverse content and style scenes without necessitating any training, as it relies solely on optimization-based techniques. See our project page for additional results and source code: $\href{https://compvis.github.io/wast3d/}{https://compvis.github.io/wast3d/}$.
CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Mar 28, 2024The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
ReShader: View-Dependent Highlights for Single Image View-Synthesis
Sep 19, 2023



In recent years, novel view synthesis from a single image has seen significant progress thanks to the rapid advancements in 3D scene representation and image inpainting techniques. While the current approaches are able to synthesize geometrically consistent novel views, they often do not handle the view-dependent effects properly. Specifically, the highlights in their synthesized images usually appear to be glued to the surfaces, making the novel views unrealistic. To address this major problem, we make a key observation that the process of synthesizing novel views requires changing the shading of the pixels based on the novel camera, and moving them to appropriate locations. Therefore, we propose to split the view synthesis process into two independent tasks of pixel reshading and relocation. During the reshading process, we take the single image as the input and adjust its shading based on the novel camera. This reshaded image is then used as the input to an existing view synthesis method to relocate the pixels and produce the final novel view image. We propose to use a neural network to perform reshading and generate a large set of synthetic input-reshaded pairs to train our network. We demonstrate that our approach produces plausible novel view images with realistic moving highlights on a variety of real world scenes.
Implicit View-Time Interpolation of Stereo Videos using Multi-Plane Disparities and Non-Uniform Coordinates
Mar 30, 2023


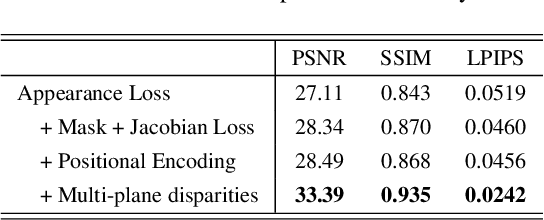
In this paper, we propose an approach for view-time interpolation of stereo videos. Specifically, we build upon X-Fields that approximates an interpolatable mapping between the input coordinates and 2D RGB images using a convolutional decoder. Our main contribution is to analyze and identify the sources of the problems with using X-Fields in our application and propose novel techniques to overcome these challenges. Specifically, we observe that X-Fields struggles to implicitly interpolate the disparities for large baseline cameras. Therefore, we propose multi-plane disparities to reduce the spatial distance of the objects in the stereo views. Moreover, we propose non-uniform time coordinates to handle the non-linear and sudden motion spikes in videos. We additionally introduce several simple, but important, improvements over X-Fields. We demonstrate that our approach is able to produce better results than the state of the art, while running in near real-time rates and having low memory and storage costs.
Frame Interpolation for Dynamic Scenes with Implicit Flow Encoding
Sep 27, 2022
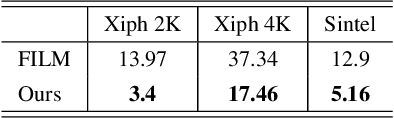
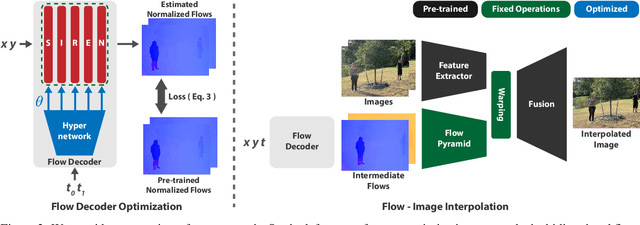
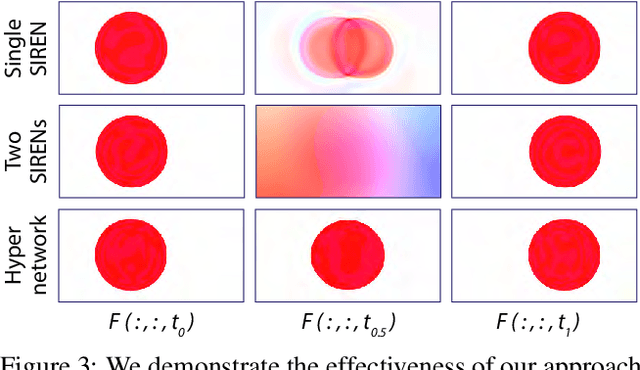
In this paper, we propose an algorithm to interpolate between a pair of images of a dynamic scene. While in the past years significant progress in frame interpolation has been made, current approaches are not able to handle images with brightness and illumination changes, which are common even when the images are captured shortly apart. We propose to address this problem by taking advantage of the existing optical flow methods that are highly robust to the variations in the illumination. Specifically, using the bidirectional flows estimated using an existing pre-trained flow network, we predict the flows from an intermediate frame to the two input images. To do this, we propose to encode the bidirectional flows into a coordinate-based network, powered by a hypernetwork, to obtain a continuous representation of the flow across time. Once we obtain the estimated flows, we use them within an existing blending network to obtain the final intermediate frame. Through extensive experiments, we demonstrate that our approach is able to produce significantly better results than state-of-the-art frame interpolation algorithms.
Multi-Stage Raw Video Denoising with Adversarial Loss and Gradient Mask
Mar 05, 2021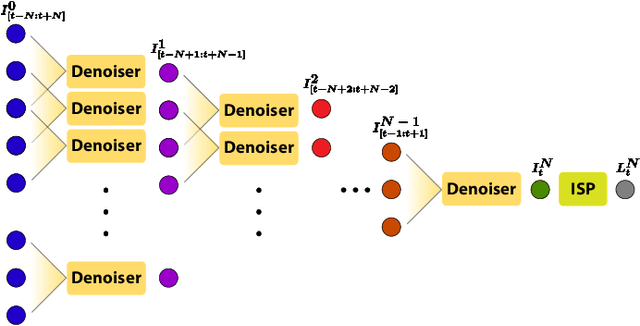
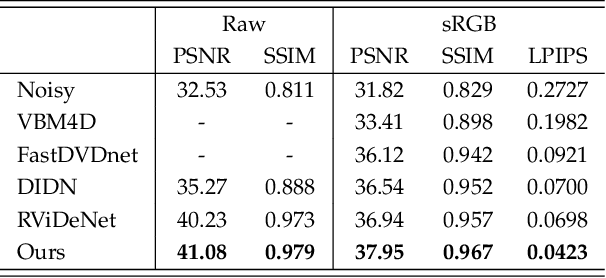

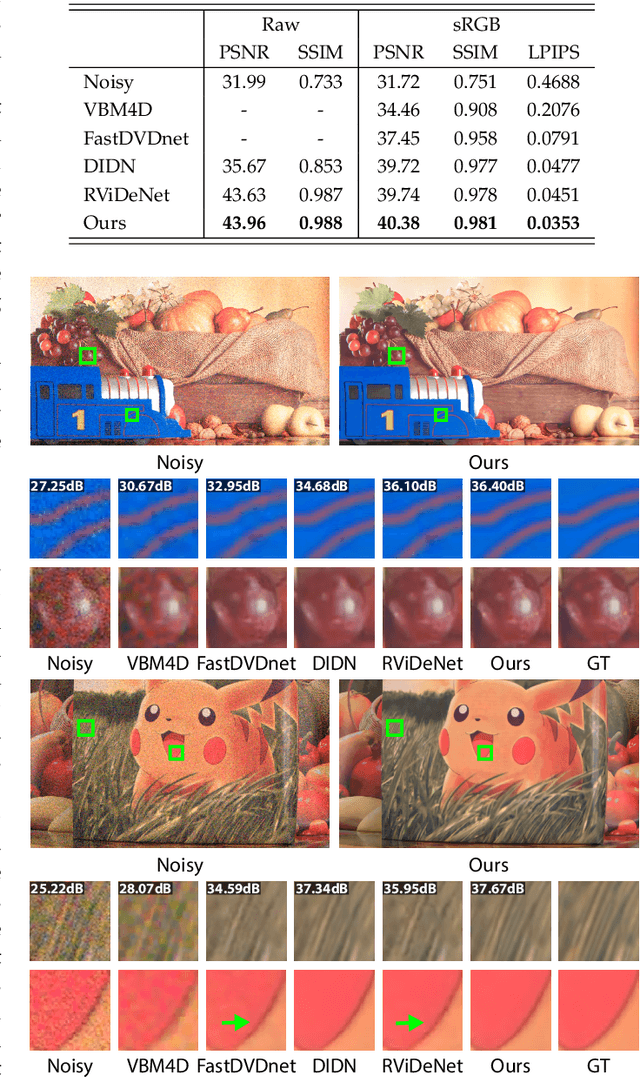
In this paper, we propose a learning-based approach for denoising raw videos captured under low lighting conditions. We propose to do this by first explicitly aligning the neighboring frames to the current frame using a convolutional neural network (CNN). We then fuse the registered frames using another CNN to obtain the final denoised frame. To avoid directly aligning the temporally distant frames, we perform the two processes of alignment and fusion in multiple stages. Specifically, at each stage, we perform the denoising process on three consecutive input frames to generate the intermediate denoised frames which are then passed as the input to the next stage. By performing the process in multiple stages, we can effectively utilize the information of neighboring frames without directly aligning the temporally distant frames. We train our multi-stage system using an adversarial loss with a conditional discriminator. Specifically, we condition the discriminator on a soft gradient mask to prevent introducing high-frequency artifacts in smooth regions. We show that our system is able to produce temporally coherent videos with realistic details. Furthermore, we demonstrate through extensive experiments that our approach outperforms state-of-the-art image and video denoising methods both numerically and visually.
Deep Slow Motion Video Reconstruction with Hybrid Imaging System
Feb 27, 2020



Slow motion videos are becoming increasingly popular, but capturing high-resolution videos at extremely high frame rates requires professional high-speed cameras. To mitigate this problem, current techniques increase the frame rate of standard videos through frame interpolation by assuming linear motion between the existing frames. While this assumption holds true for simple cases with small motion, in challenging cases the motion is usually complex and this assumption is no longer valid. Therefore, they typically produce results with unnatural motion in these challenging cases. In this paper, we address this problem using two video streams as the input; an auxiliary video with high frame rate and low spatial resolution, providing temporal information, in addition to the standard main video with low frame rate and high spatial resolution. We propose a two-stage deep learning system consisting of alignment and appearance estimation that reconstructs high resolution slow motion video from the hybrid video input. For alignment, we propose to use a set of pre-trained and trainable convolutional neural networks (CNNs) to compute the flows between the missing frame and the two existing frames of the main video by utilizing the content of the auxiliary video frames. We then warp the existing frames using the flows to produce a set of aligned frames. For appearance estimation, we propose to combine the aligned and auxiliary frames using a context and occlusion aware CNN. We train our model on a set of synthetically generated hybrid videos and show high-quality results on a wide range of test scenes. We further demonstrate the practicality of our approach by showing the performance of our system on two real dual camera setups with small baseline.