 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes VLM Classification Benefit from LLM Description Semantics?
Dec 16, 2024



Accurately describing images via text is a foundation of explainable AI. Vision-Language Models (VLMs) like CLIP have recently addressed this by aligning images and texts in a shared embedding space, expressing semantic similarities between vision and language embeddings. VLM classification can be improved with descriptions generated by Large Language Models (LLMs). However, it is difficult to determine the contribution of actual description semantics, as the performance gain may also stem from a semantic-agnostic ensembling effect. Considering this, we ask how to distinguish the actual discriminative power of descriptions from performance boosts that potentially rely on an ensembling effect. To study this, we propose an alternative evaluation scenario that shows a characteristic behavior if the used descriptions have discriminative power. Furthermore, we propose a training-free method to select discriminative descriptions that work independently of classname ensembling effects. The training-free method works in the following way: A test image has a local CLIP label neighborhood, i.e., its top-$k$ label predictions. Then, w.r.t. to a small selection set, we extract descriptions that distinguish each class well in the local neighborhood. Using the selected descriptions, we demonstrate improved classification accuracy across seven datasets and provide in-depth analysis and insights into the explainability of description-based image classification by VLMs.
WaSt-3D: Wasserstein-2 Distance for Scene-to-Scene Stylization on 3D Gaussians
Sep 26, 2024



While style transfer techniques have been well-developed for 2D image stylization, the extension of these methods to 3D scenes remains relatively unexplored. Existing approaches demonstrate proficiency in transferring colors and textures but often struggle with replicating the geometry of the scenes. In our work, we leverage an explicit Gaussian Splatting (GS) representation and directly match the distributions of Gaussians between style and content scenes using the Earth Mover's Distance (EMD). By employing the entropy-regularized Wasserstein-2 distance, we ensure that the transformation maintains spatial smoothness. Additionally, we decompose the scene stylization problem into smaller chunks to enhance efficiency. This paradigm shift reframes stylization from a pure generative process driven by latent space losses to an explicit matching of distributions between two Gaussian representations. Our method achieves high-resolution 3D stylization by faithfully transferring details from 3D style scenes onto the content scene. Furthermore, WaSt-3D consistently delivers results across diverse content and style scenes without necessitating any training, as it relies solely on optimization-based techniques. See our project page for additional results and source code: $\href{https://compvis.github.io/wast3d/}{https://compvis.github.io/wast3d/}$.
CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Mar 28, 2024The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Mar 20, 2024



Monocular depth estimation is crucial for numerous downstream vision tasks and applications. Current discriminative approaches to this problem are limited due to blurry artifacts, while state-of-the-art generative methods suffer from slow sampling due to their SDE nature. Rather than starting from noise, we seek a direct mapping from input image to depth map. We observe that this can be effectively framed using flow matching, since its straight trajectories through solution space offer efficiency and high quality. Our study demonstrates that a pre-trained image diffusion model can serve as an adequate prior for a flow matching depth model, allowing efficient training on only synthetic data to generalize to real images. We find that an auxiliary surface normals loss further improves the depth estimates. Due to the generative nature of our approach, our model reliably predicts the confidence of its depth estimates. On standard benchmarks of complex natural scenes, our lightweight approach exhibits state-of-the-art performance at favorable low computational cost despite only being trained on little synthetic data.
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
Mar 31, 2021
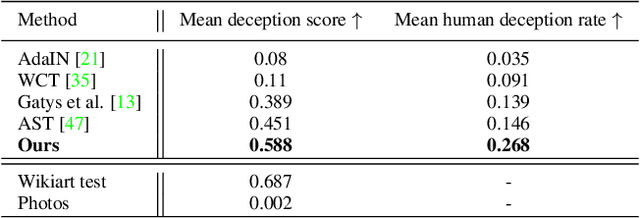


There have been many successful implementations of neural style transfer in recent years. In most of these works, the stylization process is confined to the pixel domain. However, we argue that this representation is unnatural because paintings usually consist of brushstrokes rather than pixels. We propose a method to stylize images by optimizing parameterized brushstrokes instead of pixels and further introduce a simple differentiable rendering mechanism. Our approach significantly improves visual quality and enables additional control over the stylization process such as controlling the flow of brushstrokes through user input. We provide qualitative and quantitative evaluations that show the efficacy of the proposed parameterized representation.
A Content Transformation Block For Image Style Transfer
Mar 18, 2020


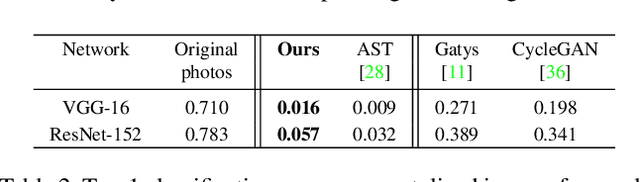
Style transfer has recently received a lot of attention, since it allows to study fundamental challenges in image understanding and synthesis. Recent work has significantly improved the representation of color and texture and computational speed and image resolution. The explicit transformation of image content has, however, been mostly neglected: while artistic style affects formal characteristics of an image, such as color, shape or texture, it also deforms, adds or removes content details. This paper explicitly focuses on a content-and style-aware stylization of a content image. Therefore, we introduce a content transformation module between the encoder and decoder. Moreover, we utilize similar content appearing in photographs and style samples to learn how style alters content details and we generalize this to other class details. Additionally, this work presents a novel normalization layer critical for high resolution image synthesis. The robustness and speed of our model enables a video stylization in real-time and high definition. We perform extensive qualitative and quantitative evaluations to demonstrate the validity of our approach.
A Style-Aware Content Loss for Real-time HD Style Transfer
Jul 28, 2018



Recently, style transfer has received a lot of attention. While much of this research has aimed at speeding up processing, the approaches are still lacking from a principled, art historical standpoint: a style is more than just a single image or an artist, but previous work is limited to only a single instance of a style or shows no benefit from more images. Moreover, previous work has relied on a direct comparison of art in the domain of RGB images or on CNNs pre-trained on ImageNet, which requires millions of labeled object bounding boxes and can introduce an extra bias, since it has been assembled without artistic consideration. To circumvent these issues, we propose a style-aware content loss, which is trained jointly with a deep encoder-decoder network for real-time, high-resolution stylization of images and videos. We propose a quantitative measure for evaluating the quality of a stylized image and also have art historians rank patches from our approach against those from previous work. These and our qualitative results ranging from small image patches to megapixel stylistic images and videos show that our approach better captures the subtle nature in which a style affects content.