 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVGS: Reimagining Unstructured 3D Gaussian Splatting using UV Mapping
Feb 03, 20253D Gaussian Splatting (3DGS) has demonstrated superior quality in modeling 3D objects and scenes. However, generating 3DGS remains challenging due to their discrete, unstructured, and permutation-invariant nature. In this work, we present a simple yet effective method to overcome these challenges. We utilize spherical mapping to transform 3DGS into a structured 2D representation, termed UVGS. UVGS can be viewed as multi-channel images, with feature dimensions as a concatenation of Gaussian attributes such as position, scale, color, opacity, and rotation. We further find that these heterogeneous features can be compressed into a lower-dimensional (e.g., 3-channel) shared feature space using a carefully designed multi-branch network. The compressed UVGS can be treated as typical RGB images. Remarkably, we discover that typical VAEs trained with latent diffusion models can directly generalize to this new representation without additional training. Our novel representation makes it effortless to leverage foundational 2D models, such as diffusion models, to directly model 3DGS. Additionally, one can simply increase the 2D UV resolution to accommodate more Gaussians, making UVGS a scalable solution compared to typical 3D backbones. This approach immediately unlocks various novel generation applications of 3DGS by inherently utilizing the already developed superior 2D generation capabilities. In our experiments, we demonstrate various unconditional, conditional generation, and inpainting applications of 3DGS based on diffusion models, which were previously non-trivial.
Quaffure: Real-Time Quasi-Static Neural Hair Simulation
Dec 13, 2024



Realistic hair motion is crucial for high-quality avatars, but it is often limited by the computational resources available for real-time applications. To address this challenge, we propose a novel neural approach to predict physically plausible hair deformations that generalizes to various body poses, shapes, and hairstyles. Our model is trained using a self-supervised loss, eliminating the need for expensive data generation and storage. We demonstrate our method's effectiveness through numerous results across a wide range of pose and shape variations, showcasing its robust generalization capabilities and temporally smooth results. Our approach is highly suitable for real-time applications with an inference time of only a few milliseconds on consumer hardware and its ability to scale to predicting the drape of 1000 grooms in 0.3 seconds.
3D Mesh Editing using Masked LRMs
Dec 11, 2024We present a novel approach to mesh shape editing, building on recent progress in 3D reconstruction from multi-view images. We formulate shape editing as a conditional reconstruction problem, where the model must reconstruct the input shape with the exception of a specified 3D region, in which the geometry should be generated from the conditional signal. To this end, we train a conditional Large Reconstruction Model (LRM) for masked reconstruction, using multi-view consistent masks rendered from a randomly generated 3D occlusion, and using one clean viewpoint as the conditional signal. During inference, we manually define a 3D region to edit and provide an edited image from a canonical viewpoint to fill in that region. We demonstrate that, in just a single forward pass, our method not only preserves the input geometry in the unmasked region through reconstruction capabilities on par with SoTA, but is also expressive enough to perform a variety of mesh edits from a single image guidance that past works struggle with, while being 10x faster than the top-performing competing prior work.
WaSt-3D: Wasserstein-2 Distance for Scene-to-Scene Stylization on 3D Gaussians
Sep 26, 2024



While style transfer techniques have been well-developed for 2D image stylization, the extension of these methods to 3D scenes remains relatively unexplored. Existing approaches demonstrate proficiency in transferring colors and textures but often struggle with replicating the geometry of the scenes. In our work, we leverage an explicit Gaussian Splatting (GS) representation and directly match the distributions of Gaussians between style and content scenes using the Earth Mover's Distance (EMD). By employing the entropy-regularized Wasserstein-2 distance, we ensure that the transformation maintains spatial smoothness. Additionally, we decompose the scene stylization problem into smaller chunks to enhance efficiency. This paradigm shift reframes stylization from a pure generative process driven by latent space losses to an explicit matching of distributions between two Gaussian representations. Our method achieves high-resolution 3D stylization by faithfully transferring details from 3D style scenes onto the content scene. Furthermore, WaSt-3D consistently delivers results across diverse content and style scenes without necessitating any training, as it relies solely on optimization-based techniques. See our project page for additional results and source code: $\href{https://compvis.github.io/wast3d/}{https://compvis.github.io/wast3d/}$.
TalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Sep 25, 2024



We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.
Garment3DGen: 3D Garment Stylization and Texture Generation
Mar 27, 2024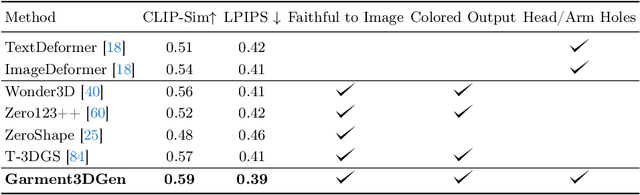
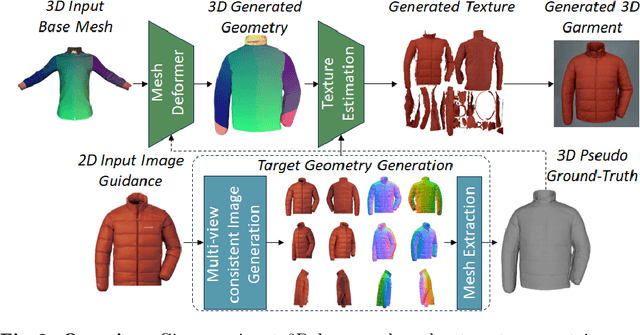


We introduce Garment3DGen a new method to synthesize 3D garment assets from a base mesh given a single input image as guidance. Our proposed approach allows users to generate 3D textured clothes based on both real and synthetic images, such as those generated by text prompts. The generated assets can be directly draped and simulated on human bodies. First, we leverage the recent progress of image to 3D diffusion methods to generate 3D garment geometries. However, since these geometries cannot be utilized directly for downstream tasks, we propose to use them as pseudo ground-truth and set up a mesh deformation optimization procedure that deforms a base template mesh to match the generated 3D target. Second, we introduce carefully designed losses that allow the input base mesh to freely deform towards the desired target, yet preserve mesh quality and topology such that they can be simulated. Finally, a texture estimation module generates high-fidelity texture maps that are globally and locally consistent and faithfully capture the input guidance, allowing us to render the generated 3D assets. With Garment3DGen users can generate the textured 3D garment of their choice without the need of artist intervention. One can provide a textual prompt describing the garment they desire to generate a simulation-ready 3D asset. We present a plethora of quantitative and qualitative comparisons on various assets both real and generated and provide use-cases of how one can generate simulation-ready 3D garments.
ANIM: Accurate Neural Implicit Model for Human Reconstruction from a single RGB-D image
Mar 18, 2024



Recent progress in human shape learning, shows that neural implicit models are effective in generating 3D human surfaces from limited number of views, and even from a single RGB image. However, existing monocular approaches still struggle to recover fine geometric details such as face, hands or cloth wrinkles. They are also easily prone to depth ambiguities that result in distorted geometries along the camera optical axis. In this paper, we explore the benefits of incorporating depth observations in the reconstruction process by introducing ANIM, a novel method that reconstructs arbitrary 3D human shapes from single-view RGB-D images with an unprecedented level of accuracy. Our model learns geometric details from both multi-resolution pixel-aligned and voxel-aligned features to leverage depth information and enable spatial relationships, mitigating depth ambiguities. We further enhance the quality of the reconstructed shape by introducing a depth-supervision strategy, which improves the accuracy of the signed distance field estimation of points that lie on the reconstructed surface. Experiments demonstrate that ANIM outperforms state-of-the-art works that use RGB, surface normals, point cloud or RGB-D data as input. In addition, we introduce ANIM-Real, a new multi-modal dataset comprising high-quality scans paired with consumer-grade RGB-D camera, and our protocol to fine-tune ANIM, enabling high-quality reconstruction from real-world human capture.
Geometry Transfer for Stylizing Radiance Fields
Feb 02, 2024Shape and geometric patterns are essential in defining stylistic identity. However, current 3D style transfer methods predominantly focus on transferring colors and textures, often overlooking geometric aspects. In this paper, we introduce Geometry Transfer, a novel method that leverages geometric deformation for 3D style transfer. This technique employs depth maps to extract a style guide, subsequently applied to stylize the geometry of radiance fields. Moreover, we propose new techniques that utilize geometric cues from the 3D scene, thereby enhancing aesthetic expressiveness and more accurately reflecting intended styles. Our extensive experiments show that Geometry Transfer enables a broader and more expressive range of stylizations, thereby significantly expanding the scope of 3D style transfer.
HISR: Hybrid Implicit Surface Representation for Photorealistic 3D Human Reconstruction
Dec 28, 2023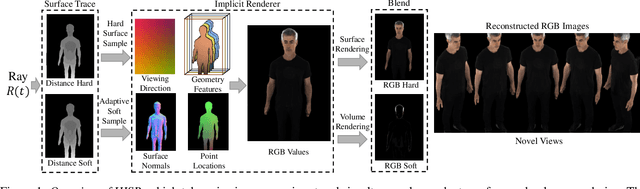
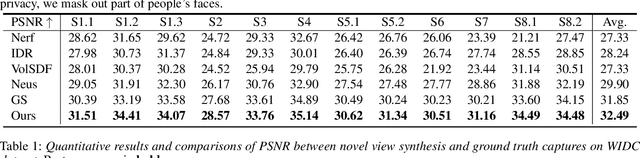
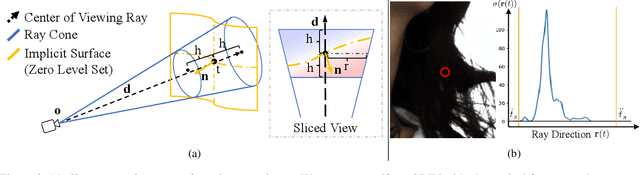
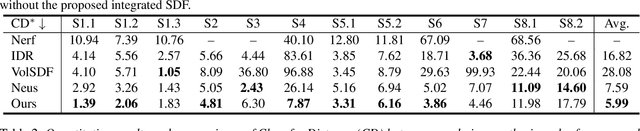
Neural reconstruction and rendering strategies have demonstrated state-of-the-art performances due, in part, to their ability to preserve high level shape details. Existing approaches, however, either represent objects as implicit surface functions or neural volumes and still struggle to recover shapes with heterogeneous materials, in particular human skin, hair or clothes. To this aim, we present a new hybrid implicit surface representation to model human shapes. This representation is composed of two surface layers that represent opaque and translucent regions on the clothed human body. We segment different regions automatically using visual cues and learn to reconstruct two signed distance functions (SDFs). We perform surface-based rendering on opaque regions (e.g., body, face, clothes) to preserve high-fidelity surface normals and volume rendering on translucent regions (e.g., hair). Experiments demonstrate that our approach obtains state-of-the-art results on 3D human reconstructions, and also shows competitive performances on other objects.
DiffAvatar: Simulation-Ready Garment Optimization with Differentiable Simulation
Nov 20, 2023



The realism of digital avatars is crucial in enabling telepresence applications with self-expression and customization. A key aspect of this realism originates from the physical accuracy of both a true-to-life body shape and clothing. While physical simulations can produce high-quality, realistic motions for clothed humans, they require precise estimation of body shape and high-quality garment assets with associated physical parameters for cloth simulations. However, manually creating these assets and calibrating their parameters is labor-intensive and requires specialized expertise. To address this gap, we propose DiffAvatar, a novel approach that performs body and garment co-optimization using differentiable simulation. By integrating physical simulation into the optimization loop and accounting for the complex nonlinear behavior of cloth and its intricate interaction with the body, our framework recovers body and garment geometry and extracts important material parameters in a physically plausible way. Our experiments demonstrate that our approach generates realistic clothing and body shape that can be easily used in downstream applications.