 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePackUV: Packed Gaussian UV Maps for 4D Volumetric Video
Feb 26, 2026Volumetric videos offer immersive 4D experiences, but remain difficult to reconstruct, store, and stream at scale. Existing Gaussian Splatting based methods achieve high-quality reconstruction but break down on long sequences, temporal inconsistency, and fail under large motions and disocclusions. Moreover, their outputs are typically incompatible with conventional video coding pipelines, preventing practical applications. We introduce PackUV, a novel 4D Gaussian representation that maps all Gaussian attributes into a sequence of structured, multi-scale UV atlas, enabling compact, image-native storage. To fit this representation from multi-view videos, we propose PackUV-GS, a temporally consistent fitting method that directly optimizes Gaussian parameters in the UV domain. A flow-guided Gaussian labeling and video keyframing module identifies dynamic Gaussians, stabilizes static regions, and preserves temporal coherence even under large motions and disocclusions. The resulting UV atlas format is the first unified volumetric video representation compatible with standard video codecs (e.g., FFV1) without losing quality, enabling efficient streaming within existing multimedia infrastructure. To evaluate long-duration volumetric capture, we present PackUV-2B, the largest multi-view video dataset to date, featuring more than 50 synchronized cameras, substantial motion, and frequent disocclusions across 100 sequences and 2B (billion) frames. Extensive experiments demonstrate that our method surpasses existing baselines in rendering fidelity while scaling to sequences up to 30 minutes with consistent quality.
* https://ivl.cs.brown.edu/packuv
InteractAvatar: Modeling Hand-Face Interaction in Photorealistic Avatars with Deformable Gaussians
Apr 10, 2025With the rising interest from the community in digital avatars coupled with the importance of expressions and gestures in communication, modeling natural avatar behavior remains an important challenge across many industries such as teleconferencing, gaming, and AR/VR. Human hands are the primary tool for interacting with the environment and essential for realistic human behavior modeling, yet existing 3D hand and head avatar models often overlook the crucial aspect of hand-body interactions, such as between hand and face. We present InteracttAvatar, the first model to faithfully capture the photorealistic appearance of dynamic hand and non-rigid hand-face interactions. Our novel Dynamic Gaussian Hand model, combining template model and 3D Gaussian Splatting as well as a dynamic refinement module, captures pose-dependent change, e.g. the fine wrinkles and complex shadows that occur during articulation. Importantly, our hand-face interaction module models the subtle geometry and appearance dynamics that underlie common gestures. Through experiments of novel view synthesis, self reenactment and cross-identity reenactment, we demonstrate that InteracttAvatar can reconstruct hand and hand-face interactions from monocular or multiview videos with high-fidelity details and be animated with novel poses.
UVGS: Reimagining Unstructured 3D Gaussian Splatting using UV Mapping
Feb 03, 20253D Gaussian Splatting (3DGS) has demonstrated superior quality in modeling 3D objects and scenes. However, generating 3DGS remains challenging due to their discrete, unstructured, and permutation-invariant nature. In this work, we present a simple yet effective method to overcome these challenges. We utilize spherical mapping to transform 3DGS into a structured 2D representation, termed UVGS. UVGS can be viewed as multi-channel images, with feature dimensions as a concatenation of Gaussian attributes such as position, scale, color, opacity, and rotation. We further find that these heterogeneous features can be compressed into a lower-dimensional (e.g., 3-channel) shared feature space using a carefully designed multi-branch network. The compressed UVGS can be treated as typical RGB images. Remarkably, we discover that typical VAEs trained with latent diffusion models can directly generalize to this new representation without additional training. Our novel representation makes it effortless to leverage foundational 2D models, such as diffusion models, to directly model 3DGS. Additionally, one can simply increase the 2D UV resolution to accommodate more Gaussians, making UVGS a scalable solution compared to typical 3D backbones. This approach immediately unlocks various novel generation applications of 3DGS by inherently utilizing the already developed superior 2D generation capabilities. In our experiments, we demonstrate various unconditional, conditional generation, and inpainting applications of 3DGS based on diffusion models, which were previously non-trivial.
Multi-view Image Diffusion via Coordinate Noise and Fourier Attention
Dec 04, 2024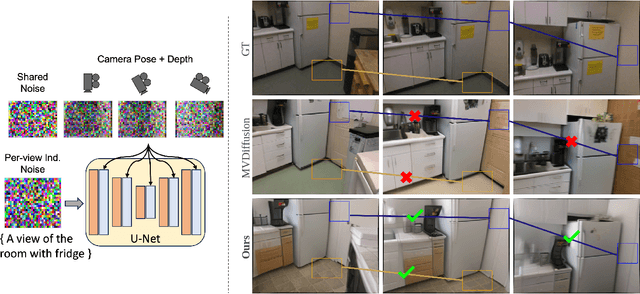

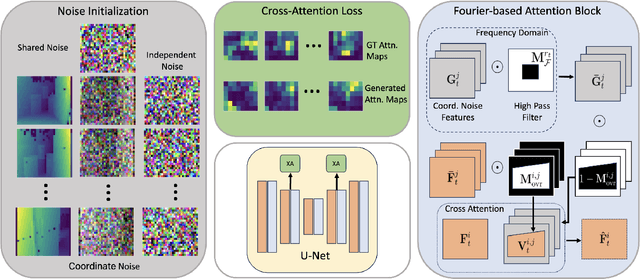
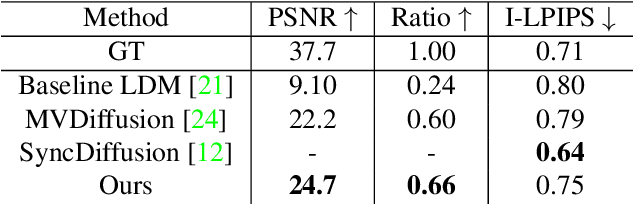
Recently, text-to-image generation with diffusion models has made significant advancements in both higher fidelity and generalization capabilities compared to previous baselines. However, generating holistic multi-view consistent images from prompts still remains an important and challenging task. To address this challenge, we propose a diffusion process that attends to time-dependent spatial frequencies of features with a novel attention mechanism as well as novel noise initialization technique and cross-attention loss. This Fourier-based attention block focuses on features from non-overlapping regions of the generated scene in order to better align the global appearance. Our noise initialization technique incorporates shared noise and low spatial frequency information derived from pixel coordinates and depth maps to induce noise correlations across views. The cross-attention loss further aligns features sharing the same prompt across the scene. Our technique improves SOTA on several quantitative metrics with qualitatively better results when compared to other state-of-the-art approaches for multi-view consistency.
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024


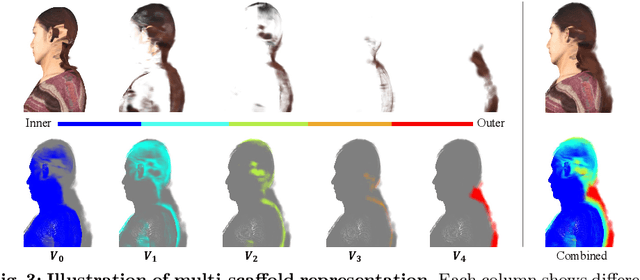
Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
Towards Realistic Generative 3D Face Models
Apr 24, 2023
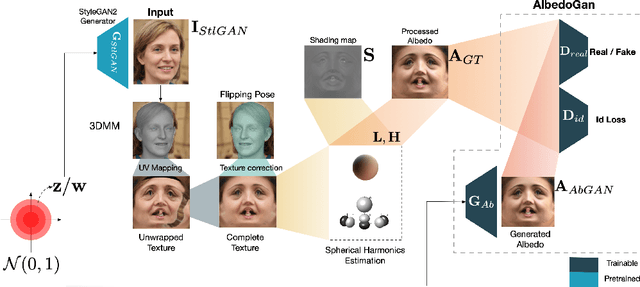


In recent years, there has been significant progress in 2D generative face models fueled by applications such as animation, synthetic data generation, and digital avatars. However, due to the absence of 3D information, these 2D models often struggle to accurately disentangle facial attributes like pose, expression, and illumination, limiting their editing capabilities. To address this limitation, this paper proposes a 3D controllable generative face model to produce high-quality albedo and precise 3D shape leveraging existing 2D generative models. By combining 2D face generative models with semantic face manipulation, this method enables editing of detailed 3D rendered faces. The proposed framework utilizes an alternating descent optimization approach over shape and albedo. Differentiable rendering is used to train high-quality shapes and albedo without 3D supervision. Moreover, this approach outperforms the state-of-the-art (SOTA) methods in the well-known NoW benchmark for shape reconstruction. It also outperforms the SOTA reconstruction models in recovering rendered faces' identities across novel poses by an average of 10%. Additionally, the paper demonstrates direct control of expressions in 3D faces by exploiting latent space leading to text-based editing of 3D faces.
Unpaired Image Translation via Vector Symbolic Architectures
Sep 06, 2022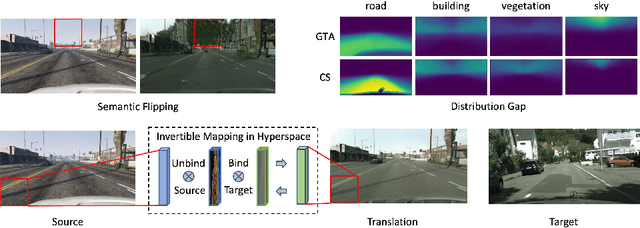
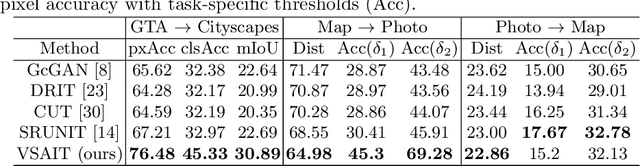


Image-to-image translation has played an important role in enabling synthetic data for computer vision. However, if the source and target domains have a large semantic mismatch, existing techniques often suffer from source content corruption aka semantic flipping. To address this problem, we propose a new paradigm for image-to-image translation using Vector Symbolic Architectures (VSA), a theoretical framework which defines algebraic operations in a high-dimensional vector (hypervector) space. We introduce VSA-based constraints on adversarial learning for source-to-target translations by learning a hypervector mapping that inverts the translation to ensure consistency with source content. We show both qualitatively and quantitatively that our method improves over other state-of-the-art techniques.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
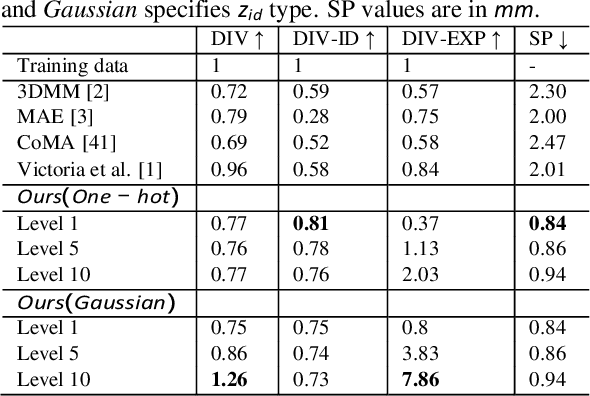
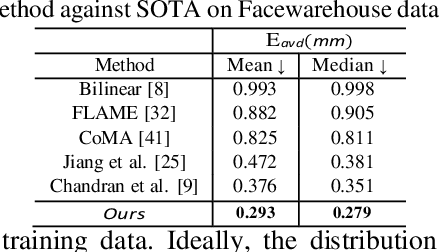
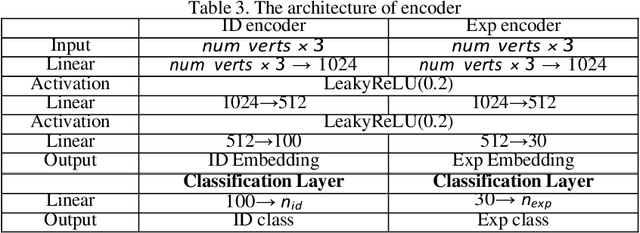
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.
Self-Supervised Object Detection via Generative Image Synthesis
Oct 19, 2021
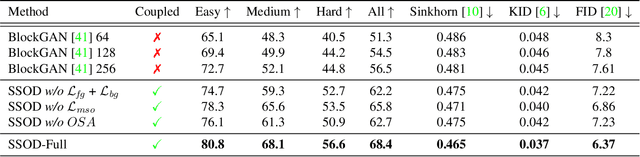
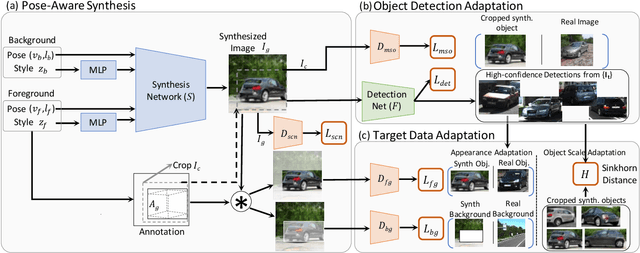
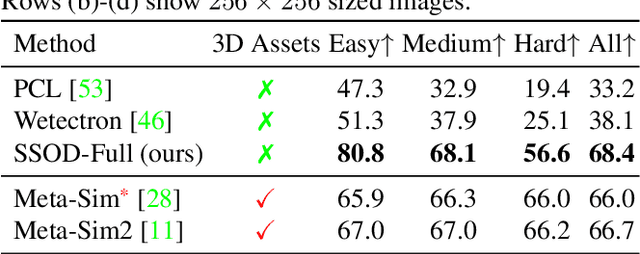
We present SSOD, the first end-to-end analysis-by synthesis framework with controllable GANs for the task of self-supervised object detection. We use collections of real world images without bounding box annotations to learn to synthesize and detect objects. We leverage controllable GANs to synthesize images with pre-defined object properties and use them to train object detectors. We propose a tight end-to-end coupling of the synthesis and detection networks to optimally train our system. Finally, we also propose a method to optimally adapt SSOD to an intended target data without requiring labels for it. For the task of car detection, on the challenging KITTI and Cityscapes datasets, we show that SSOD outperforms the prior state-of-the-art purely image-based self-supervised object detection method Wetectron. Even without requiring any 3D CAD assets, it also surpasses the state-of-the-art rendering based method Meta-Sim2. Our work advances the field of self-supervised object detection by introducing a successful new paradigm of using controllable GAN-based image synthesis for it and by significantly improving the baseline accuracy of the task. We open-source our code at https://github.com/NVlabs/SSOD.
Sim2SG: Sim-to-Real Scene Graph Generation for Transfer Learning
Nov 30, 2020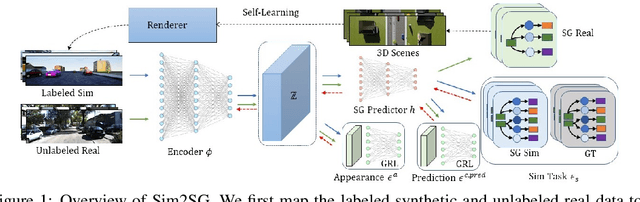

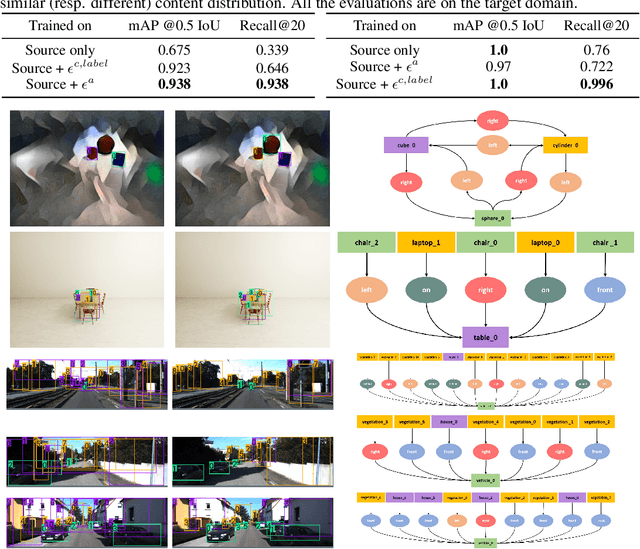
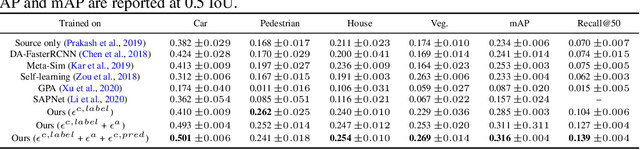
Scene graph (SG) generation has been gaining a lot of traction recently. Current SG generation techniques, however, rely on the availability of expensive and limited number of labeled datasets. Synthetic data offers a viable alternative as labels are essentially free. However, neural network models trained on synthetic data, do not perform well on real data because of the domain gap. To overcome this challenge, we propose Sim2SG, a scalable technique for sim-to-real transfer for scene graph generation. Sim2SG addresses the domain gap by decomposing it into appearance, label and prediction discrepancies between the two domains. We handle these discrepancies by introducing pseudo statistic based self-learning and adversarial techniques. Sim2SG does not require costly supervision from the real-world dataset. Our experiments demonstrate significant improvements over baselines in reducing the domain gap both qualitatively and quantitatively. We validate our approach on toy simulators, as well as realistic simulators evaluated on real-world data.