 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Synthetica: Large Scale Synthetic Data for Robot Perception
Oct 28, 2024



Vision-based object detectors are a crucial basis for robotics applications as they provide valuable information about object localisation in the environment. These need to ensure high reliability in different lighting conditions, occlusions, and visual artifacts, all while running in real-time. Collecting and annotating real-world data for these networks is prohibitively time consuming and costly, especially for custom assets, such as industrial objects, making it untenable for generalization to in-the-wild scenarios. To this end, we present Synthetica, a method for large-scale synthetic data generation for training robust state estimators. This paper focuses on the task of object detection, an important problem which can serve as the front-end for most state estimation problems, such as pose estimation. Leveraging data from a photorealistic ray-tracing renderer, we scale up data generation, generating 2.7 million images, to train highly accurate real-time detection transformers. We present a collection of rendering randomization and training-time data augmentation techniques conducive to robust sim-to-real performance for vision tasks. We demonstrate state-of-the-art performance on the task of object detection while having detectors that run at 50-100Hz which is 9 times faster than the prior SOTA. We further demonstrate the usefulness of our training methodology for robotics applications by showcasing a pipeline for use in the real world with custom objects for which there do not exist prior datasets. Our work highlights the importance of scaling synthetic data generation for robust sim-to-real transfer while achieving the fastest real-time inference speeds. Videos and supplementary information can be found at this URL: https://sites.google.com/view/synthetica-vision.
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
Apr 20, 2021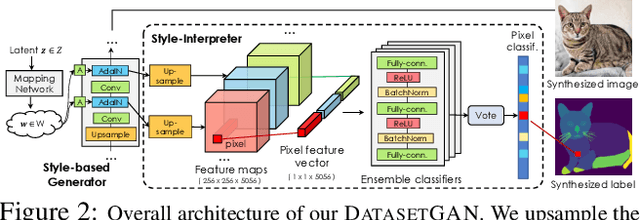
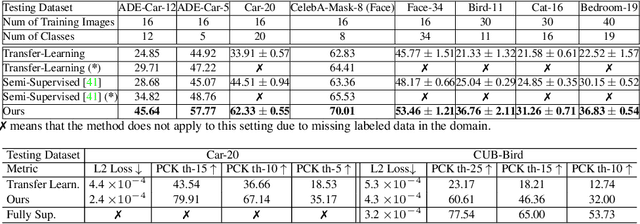
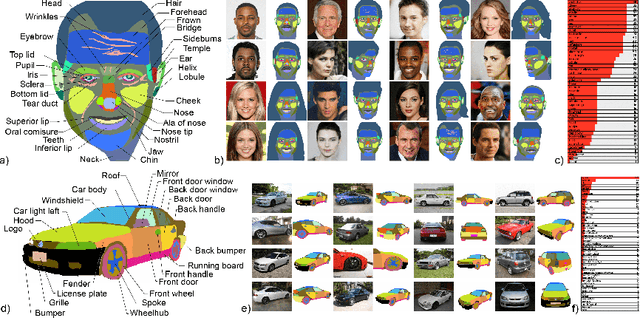
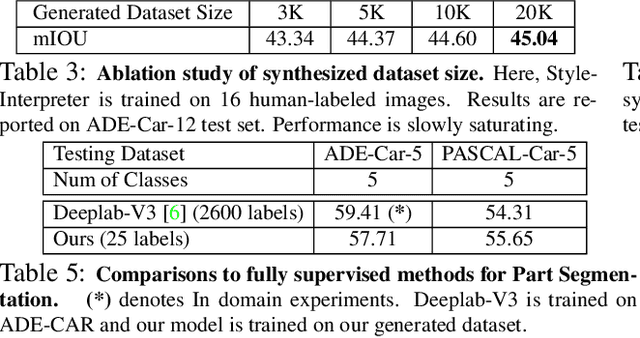
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.
Sim2SG: Sim-to-Real Scene Graph Generation for Transfer Learning
Nov 30, 2020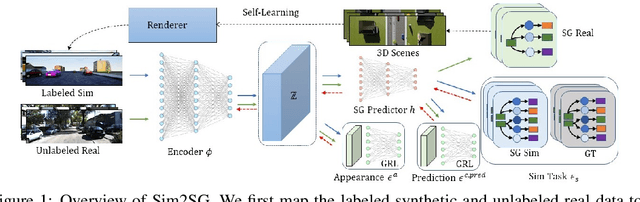

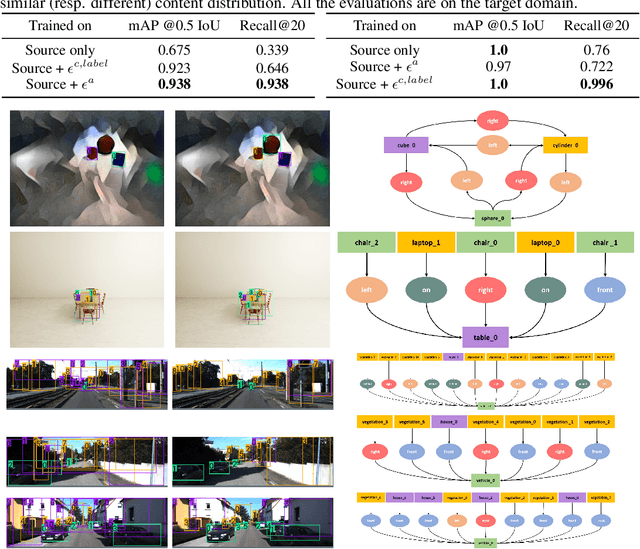
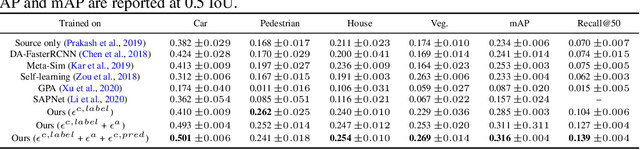
Scene graph (SG) generation has been gaining a lot of traction recently. Current SG generation techniques, however, rely on the availability of expensive and limited number of labeled datasets. Synthetic data offers a viable alternative as labels are essentially free. However, neural network models trained on synthetic data, do not perform well on real data because of the domain gap. To overcome this challenge, we propose Sim2SG, a scalable technique for sim-to-real transfer for scene graph generation. Sim2SG addresses the domain gap by decomposing it into appearance, label and prediction discrepancies between the two domains. We handle these discrepancies by introducing pseudo statistic based self-learning and adversarial techniques. Sim2SG does not require costly supervision from the real-world dataset. Our experiments demonstrate significant improvements over baselines in reducing the domain gap both qualitatively and quantitatively. We validate our approach on toy simulators, as well as realistic simulators evaluated on real-world data.
Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research
Nov 13, 2019

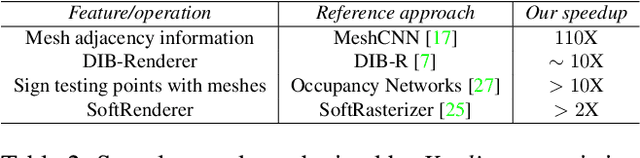

We present Kaolin, a PyTorch library aiming to accelerate 3D deep learning research. Kaolin provides efficient implementations of differentiable 3D modules for use in deep learning systems. With functionality to load and preprocess several popular 3D datasets, and native functions to manipulate meshes, pointclouds, signed distance functions, and voxel grids, Kaolin mitigates the need to write wasteful boilerplate code. Kaolin packages together several differentiable graphics modules including rendering, lighting, shading, and view warping. Kaolin also supports an array of loss functions and evaluation metrics for seamless evaluation and provides visualization functionality to render the 3D results. Importantly, we curate a comprehensive model zoo comprising many state-of-the-art 3D deep learning architectures, to serve as a starting point for future research endeavours. Kaolin is available as open-source software at https://github.com/NVIDIAGameWorks/kaolin/.