 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations
Jan 12, 2022

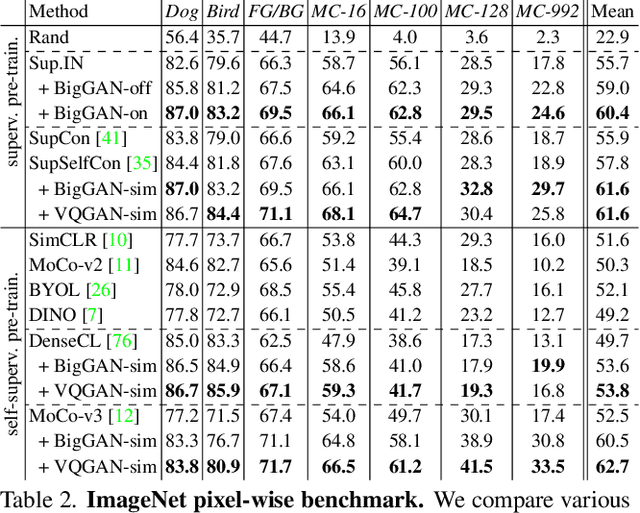
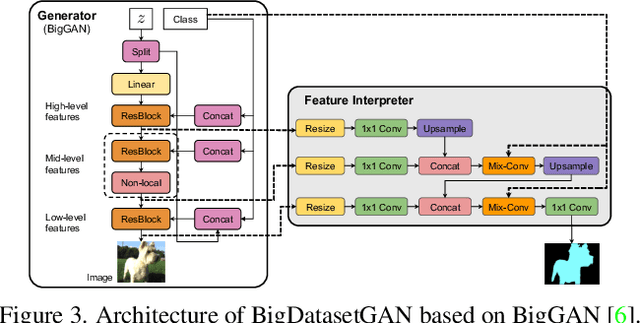
Annotating images with pixel-wise labels is a time-consuming and costly process. Recently, DatasetGAN showcased a promising alternative - to synthesize a large labeled dataset via a generative adversarial network (GAN) by exploiting a small set of manually labeled, GAN-generated images. Here, we scale DatasetGAN to ImageNet scale of class diversity. We take image samples from the class-conditional generative model BigGAN trained on ImageNet, and manually annotate 5 images per class, for all 1k classes. By training an effective feature segmentation architecture on top of BigGAN, we turn BigGAN into a labeled dataset generator. We further show that VQGAN can similarly serve as a dataset generator, leveraging the already annotated data. We create a new ImageNet benchmark by labeling an additional set of 8k real images and evaluate segmentation performance in a variety of settings. Through an extensive ablation study we show big gains in leveraging a large generated dataset to train different supervised and self-supervised backbone models on pixel-wise tasks. Furthermore, we demonstrate that using our synthesized datasets for pre-training leads to improvements over standard ImageNet pre-training on several downstream datasets, such as PASCAL-VOC, MS-COCO, Cityscapes and chest X-ray, as well as tasks (detection, segmentation). Our benchmark will be made public and maintain a leaderboard for this challenging task. Project Page: https://nv-tlabs.github.io/big-datasetgan/
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
Apr 20, 2021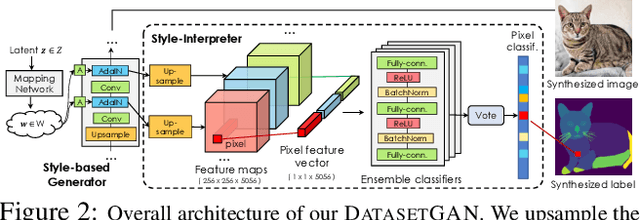
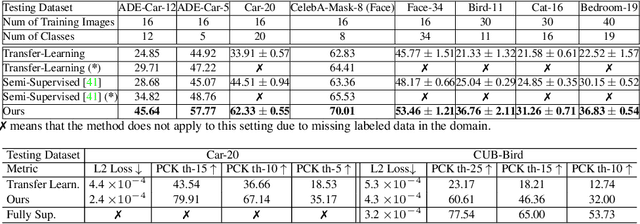
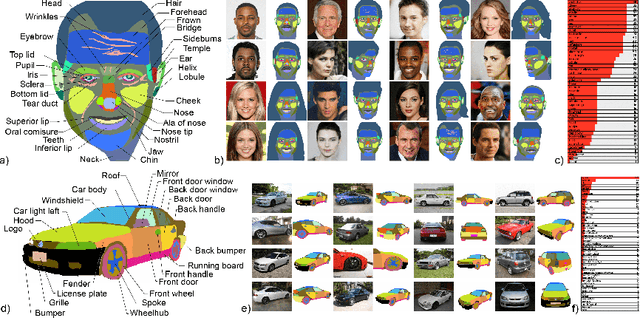
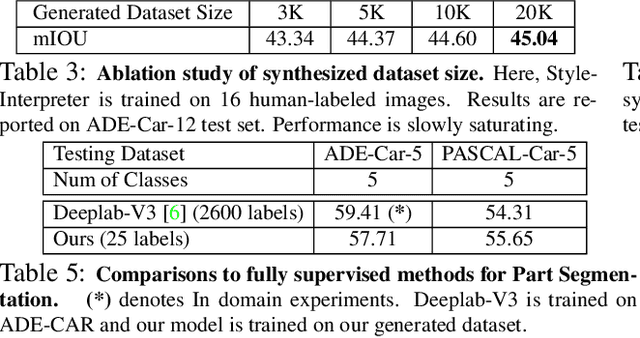
We introduce DatasetGAN: an automatic procedure to generate massive datasets of high-quality semantically segmented images requiring minimal human effort. Current deep networks are extremely data-hungry, benefiting from training on large-scale datasets, which are time consuming to annotate. Our method relies on the power of recent GANs to generate realistic images. We show how the GAN latent code can be decoded to produce a semantic segmentation of the image. Training the decoder only needs a few labeled examples to generalize to the rest of the latent space, resulting in an infinite annotated dataset generator! These generated datasets can then be used for training any computer vision architecture just as real datasets are. As only a few images need to be manually segmented, it becomes possible to annotate images in extreme detail and generate datasets with rich object and part segmentations. To showcase the power of our approach, we generated datasets for 7 image segmentation tasks which include pixel-level labels for 34 human face parts, and 32 car parts. Our approach outperforms all semi-supervised baselines significantly and is on par with fully supervised methods, which in some cases require as much as 100x more annotated data as our method.
Semantic Understanding of Scenes through the ADE20K Dataset
Oct 16, 2018
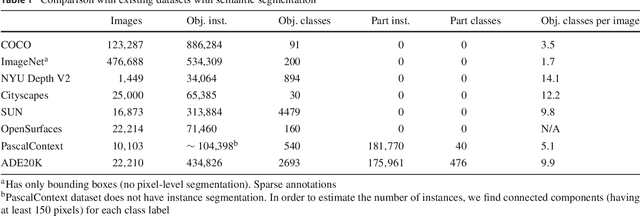

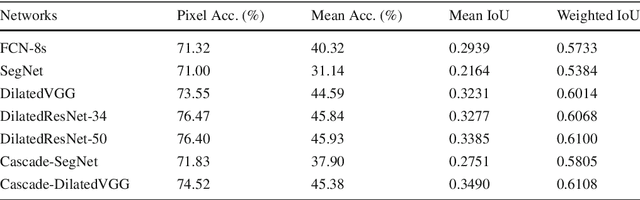
Scene parsing, or recognizing and segmenting objects and stuff in an image, is one of the key problems in computer vision. Despite the community's efforts in data collection, there are still few image datasets covering a wide range of scenes and object categories with dense and detailed annotations for scene parsing. In this paper, we introduce and analyze the ADE20K dataset, spanning diverse annotations of scenes, objects, parts of objects, and in some cases even parts of parts. A generic network design called Cascade Segmentation Module is then proposed to enable the segmentation networks to parse a scene into stuff, objects, and object parts in a cascade. We evaluate the proposed module integrated within two existing semantic segmentation networks, yielding significant improvements for scene parsing. We further show that the scene parsing networks trained on ADE20K can be applied to a wide variety of scenes and objects.
Notes on image annotation
Oct 12, 2012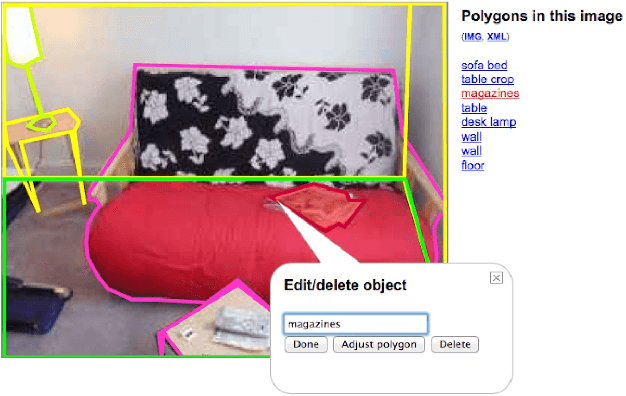

We are under the illusion that seeing is effortless, but frequently the visual system is lazy and makes us believe that we understand something when in fact we don't. Labeling a picture forces us to become aware of the difficulties underlying scene understanding. Suddenly, the act of seeing is not effortless anymore. We have to make an effort in order to understand parts of the picture that we neglected at first glance. In this report, an expert image annotator relates her experience on segmenting and labeling tens of thousands of images. During this process, the notes she took try to highlight the difficulties encountered, the solutions adopted, and the decisions made in order to get a consistent set of annotations. Those annotations constitute the SUN database.