 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Jun 02, 2026As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Direct Diffusion Score Preference Optimization via Stepwise Contrastive Policy-Pair Supervision
Dec 29, 2025Diffusion models have achieved impressive results in generative tasks such as text-to-image synthesis, yet they often struggle to fully align outputs with nuanced user intent and maintain consistent aesthetic quality. Existing preference-based training methods like Diffusion Direct Preference Optimization help address these issues but rely on costly and potentially noisy human-labeled datasets. In this work, we introduce Direct Diffusion Score Preference Optimization (DDSPO), which directly derives per-timestep supervision from winning and losing policies when such policies are available. Unlike prior methods that operate solely on final samples, DDSPO provides dense, transition-level signals across the denoising trajectory. In practice, we avoid reliance on labeled data by automatically generating preference signals using a pretrained reference model: we contrast its outputs when conditioned on original prompts versus semantically degraded variants. This practical strategy enables effective score-space preference supervision without explicit reward modeling or manual annotations. Empirical results demonstrate that DDSPO improves text-image alignment and visual quality, outperforming or matching existing preference-based methods while requiring significantly less supervision. Our implementation is available at: https://dohyun-as.github.io/DDSPO
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025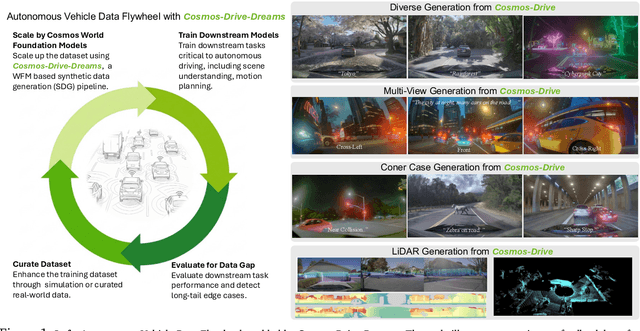
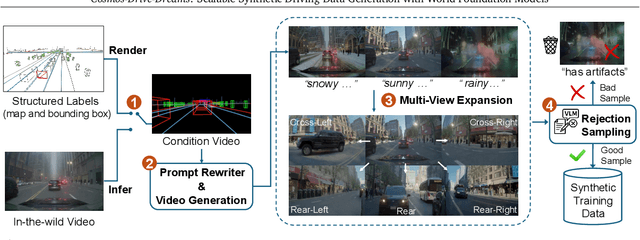
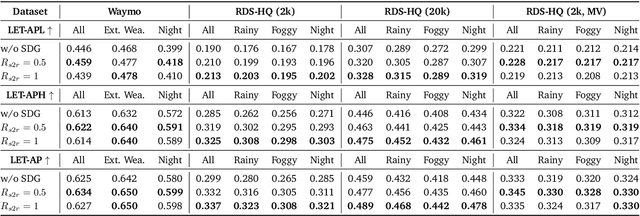
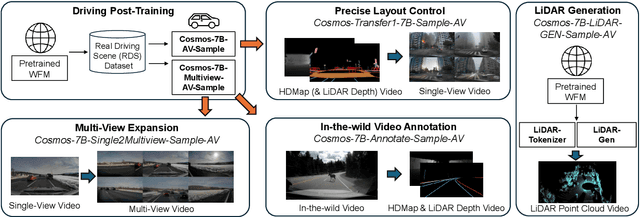
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Random Conditioning with Distillation for Data-Efficient Diffusion Model Compression
Apr 02, 2025Diffusion models generate high-quality images through progressive denoising but are computationally intensive due to large model sizes and repeated sampling. Knowledge distillation, which transfers knowledge from a complex teacher to a simpler student model, has been widely studied in recognition tasks, particularly for transferring concepts unseen during student training. However, its application to diffusion models remains underexplored, especially in enabling student models to generate concepts not covered by the training images. In this work, we propose Random Conditioning, a novel approach that pairs noised images with randomly selected text conditions to enable efficient, image-free knowledge distillation. By leveraging this technique, we show that the student can generate concepts unseen in the training images. When applied to conditional diffusion model distillation, our method allows the student to explore the condition space without generating condition-specific images, resulting in notable improvements in both generation quality and efficiency. This promotes resource-efficient deployment of generative diffusion models, broadening their accessibility for both research and real-world applications. Code, models, and datasets are available at https://dohyun-as.github.io/Random-Conditioning .
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Jun 17, 2024



We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
L4GM: Large 4D Gaussian Reconstruction Model
Jun 14, 2024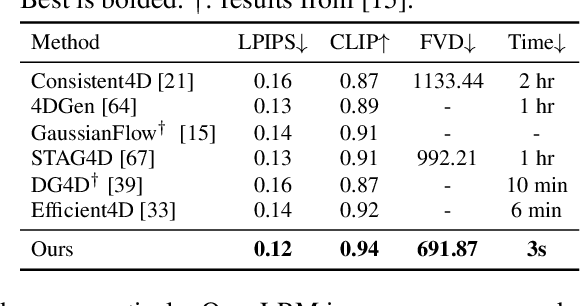
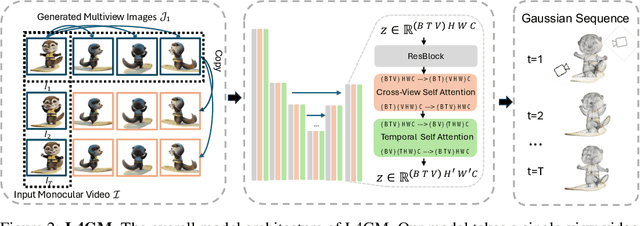
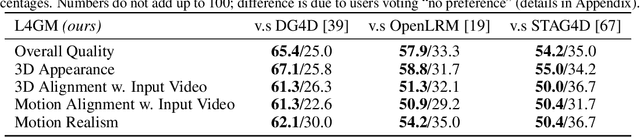
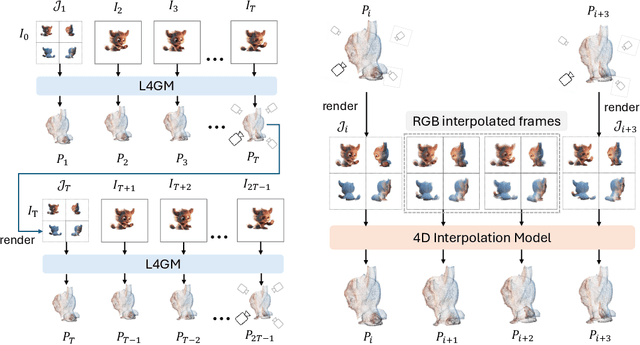
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
RefFusion: Reference Adapted Diffusion Models for 3D Scene Inpainting
Apr 16, 2024


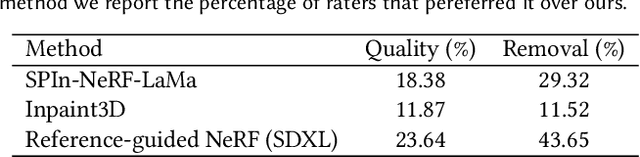
Neural reconstruction approaches are rapidly emerging as the preferred representation for 3D scenes, but their limited editability is still posing a challenge. In this work, we propose an approach for 3D scene inpainting -- the task of coherently replacing parts of the reconstructed scene with desired content. Scene inpainting is an inherently ill-posed task as there exist many solutions that plausibly replace the missing content. A good inpainting method should therefore not only enable high-quality synthesis but also a high degree of control. Based on this observation, we focus on enabling explicit control over the inpainted content and leverage a reference image as an efficient means to achieve this goal. Specifically, we introduce RefFusion, a novel 3D inpainting method based on a multi-scale personalization of an image inpainting diffusion model to the given reference view. The personalization effectively adapts the prior distribution to the target scene, resulting in a lower variance of score distillation objective and hence significantly sharper details. Our framework achieves state-of-the-art results for object removal while maintaining high controllability. We further demonstrate the generality of our formulation on other downstream tasks such as object insertion, scene outpainting, and sparse view reconstruction.
EmerDiff: Emerging Pixel-level Semantic Knowledge in Diffusion Models
Jan 22, 2024Diffusion models have recently received increasing research attention for their remarkable transfer abilities in semantic segmentation tasks. However, generating fine-grained segmentation masks with diffusion models often requires additional training on annotated datasets, leaving it unclear to what extent pre-trained diffusion models alone understand the semantic relations of their generated images. To address this question, we leverage the semantic knowledge extracted from Stable Diffusion (SD) and aim to develop an image segmentor capable of generating fine-grained segmentation maps without any additional training. The primary difficulty stems from the fact that semantically meaningful feature maps typically exist only in the spatially lower-dimensional layers, which poses a challenge in directly extracting pixel-level semantic relations from these feature maps. To overcome this issue, our framework identifies semantic correspondences between image pixels and spatial locations of low-dimensional feature maps by exploiting SD's generation process and utilizes them for constructing image-resolution segmentation maps. In extensive experiments, the produced segmentation maps are demonstrated to be well delineated and capture detailed parts of the images, indicating the existence of highly accurate pixel-level semantic knowledge in diffusion models.
Align Your Gaussians: Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models
Jan 03, 2024



Text-guided diffusion models have revolutionized image and video generation and have also been successfully used for optimization-based 3D object synthesis. Here, we instead focus on the underexplored text-to-4D setting and synthesize dynamic, animated 3D objects using score distillation methods with an additional temporal dimension. Compared to previous work, we pursue a novel compositional generation-based approach, and combine text-to-image, text-to-video, and 3D-aware multiview diffusion models to provide feedback during 4D object optimization, thereby simultaneously enforcing temporal consistency, high-quality visual appearance and realistic geometry. Our method, called Align Your Gaussians (AYG), leverages dynamic 3D Gaussian Splatting with deformation fields as 4D representation. Crucial to AYG is a novel method to regularize the distribution of the moving 3D Gaussians and thereby stabilize the optimization and induce motion. We also propose a motion amplification mechanism as well as a new autoregressive synthesis scheme to generate and combine multiple 4D sequences for longer generation. These techniques allow us to synthesize vivid dynamic scenes, outperform previous work qualitatively and quantitatively and achieve state-of-the-art text-to-4D performance. Due to the Gaussian 4D representation, different 4D animations can be seamlessly combined, as we demonstrate. AYG opens up promising avenues for animation, simulation and digital content creation as well as synthetic data generation.