 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
EasyV2V: A High-quality Instruction-based Video Editing Framework
Dec 18, 2025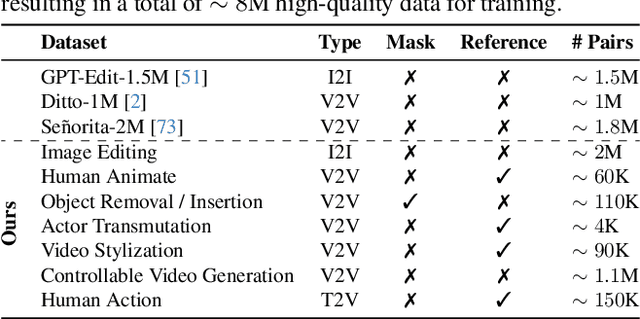

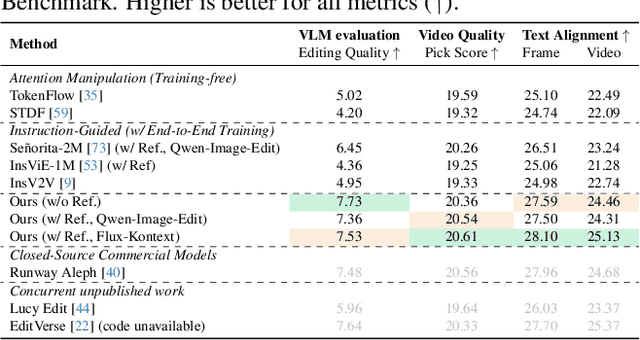
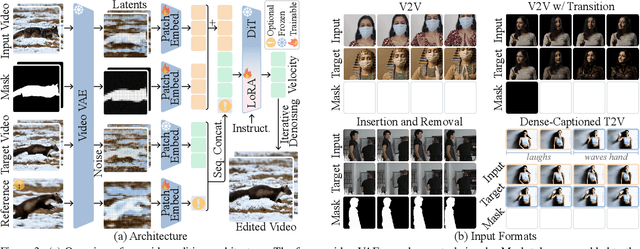
While image editing has advanced rapidly, video editing remains less explored, facing challenges in consistency, control, and generalization. We study the design space of data, architecture, and control, and introduce \emph{EasyV2V}, a simple and effective framework for instruction-based video editing. On the data side, we compose existing experts with fast inverses to build diverse video pairs, lift image edit pairs into videos via single-frame supervision and pseudo pairs with shared affine motion, mine dense-captioned clips for video pairs, and add transition supervision to teach how edits unfold. On the model side, we observe that pretrained text-to-video models possess editing capability, motivating a simplified design. Simple sequence concatenation for conditioning with light LoRA fine-tuning suffices to train a strong model. For control, we unify spatiotemporal control via a single mask mechanism and support optional reference images. Overall, EasyV2V works with flexible inputs, e.g., video+text, video+mask+text, video+mask+reference+text, and achieves state-of-the-art video editing results, surpassing concurrent and commercial systems. Project page: https://snap-research.github.io/easyv2v/
OmniView: An All-Seeing Diffusion Model for 3D and 4D View Synthesis
Dec 11, 2025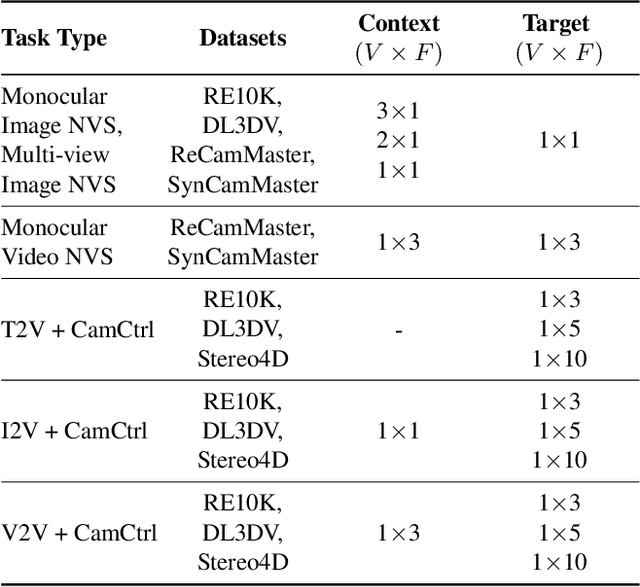
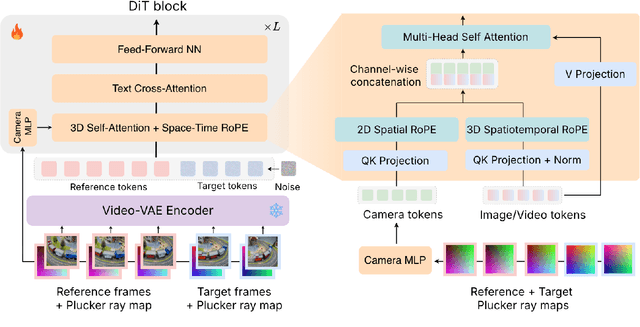
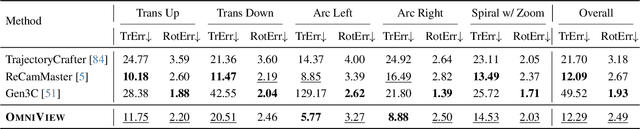

Prior approaches injecting camera control into diffusion models have focused on specific subsets of 4D consistency tasks: novel view synthesis, text-to-video with camera control, image-to-video, amongst others. Therefore, these fragmented approaches are trained on disjoint slices of available 3D/4D data. We introduce OmniView, a unified framework that generalizes across a wide range of 4D consistency tasks. Our method separately represents space, time, and view conditions, enabling flexible combinations of these inputs. For example, OmniView can synthesize novel views from static, dynamic, and multiview inputs, extrapolate trajectories forward and backward in time, and create videos from text or image prompts with full camera control. OmniView is competitive with task-specific models across diverse benchmarks and metrics, improving image quality scores among camera-conditioned diffusion models by up to 33\% in multiview NVS LLFF dataset, 60\% in dynamic NVS Neural 3D Video benchmark, 20\% in static camera control on RE-10K, and reducing camera trajectory errors by 4x in text-conditioned video generation. With strong generalizability in one model, OmniView demonstrates the feasibility of a generalist 4D video model. Project page is available at https://snap-research.github.io/OmniView/
3DGUT: Enabling Distorted Cameras and Secondary Rays in Gaussian Splatting
Dec 17, 2024
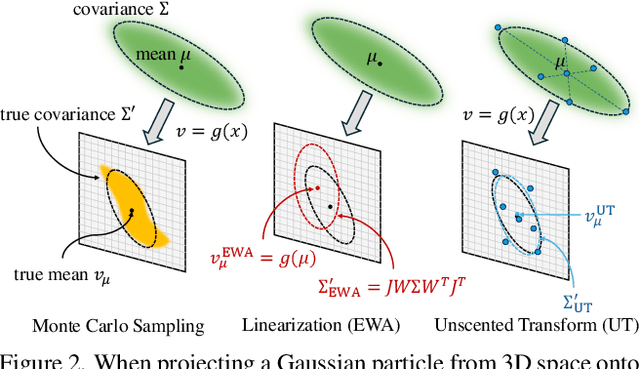


3D Gaussian Splatting (3DGS) has shown great potential for efficient reconstruction and high-fidelity real-time rendering of complex scenes on consumer hardware. However, due to its rasterization-based formulation, 3DGS is constrained to ideal pinhole cameras and lacks support for secondary lighting effects. Recent methods address these limitations by tracing volumetric particles instead, however, this comes at the cost of significantly slower rendering speeds. In this work, we propose 3D Gaussian Unscented Transform (3DGUT), replacing the EWA splatting formulation in 3DGS with the Unscented Transform that approximates the particles through sigma points, which can be projected exactly under any nonlinear projection function. This modification enables trivial support of distorted cameras with time dependent effects such as rolling shutter, while retaining the efficiency of rasterization. Additionally, we align our rendering formulation with that of tracing-based methods, enabling secondary ray tracing required to represent phenomena such as reflections and refraction within the same 3D representation.
EventSplat: 3D Gaussian Splatting from Moving Event Cameras for Real-time Rendering
Dec 10, 2024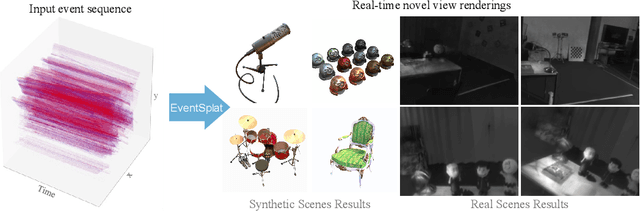
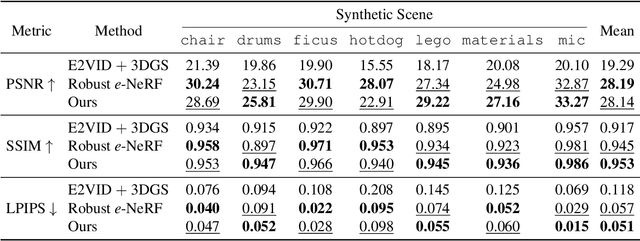
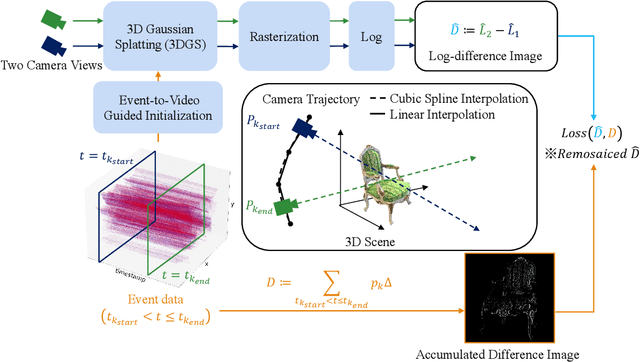
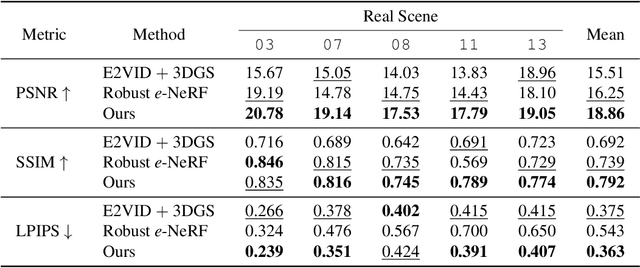
We introduce a method for using event camera data in novel view synthesis via Gaussian Splatting. Event cameras offer exceptional temporal resolution and a high dynamic range. Leveraging these capabilities allows us to effectively address the novel view synthesis challenge in the presence of fast camera motion. For initialization of the optimization process, our approach uses prior knowledge encoded in an event-to-video model. We also use spline interpolation for obtaining high quality poses along the event camera trajectory. This enhances the reconstruction quality from fast-moving cameras while overcoming the computational limitations traditionally associated with event-based Neural Radiance Field (NeRF) methods. Our experimental evaluation demonstrates that our results achieve higher visual fidelity and better performance than existing event-based NeRF approaches while being an order of magnitude faster to render.
Feed-Forward Bullet-Time Reconstruction of Dynamic Scenes from Monocular Videos
Dec 04, 2024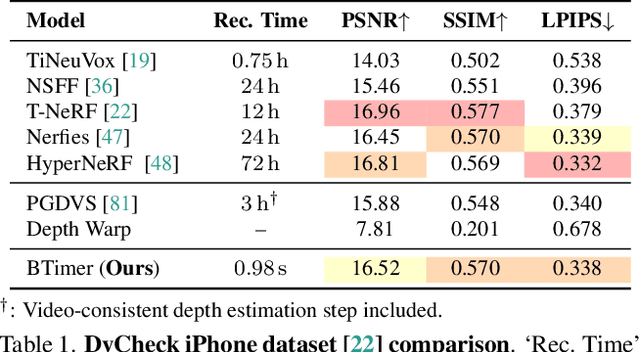
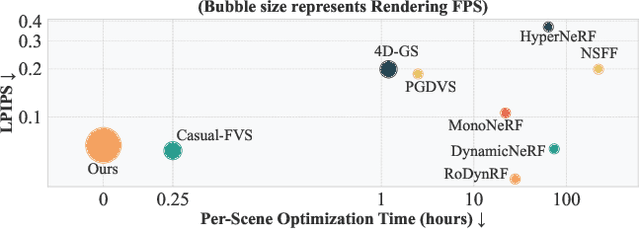
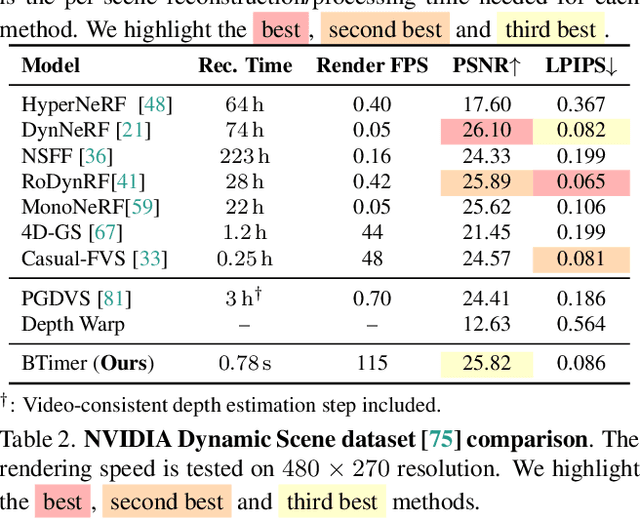
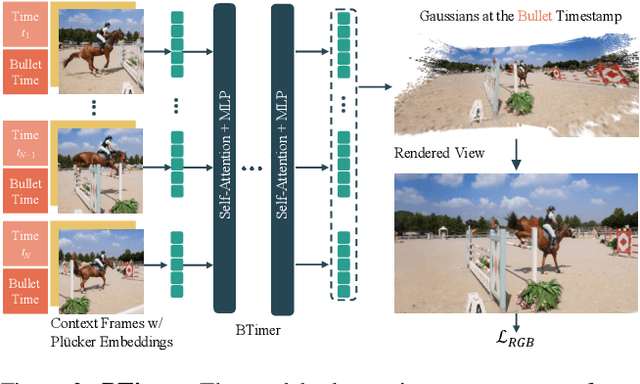
Recent advancements in static feed-forward scene reconstruction have demonstrated significant progress in high-quality novel view synthesis. However, these models often struggle with generalizability across diverse environments and fail to effectively handle dynamic content. We present BTimer (short for BulletTimer), the first motion-aware feed-forward model for real-time reconstruction and novel view synthesis of dynamic scenes. Our approach reconstructs the full scene in a 3D Gaussian Splatting representation at a given target ('bullet') timestamp by aggregating information from all the context frames. Such a formulation allows BTimer to gain scalability and generalization by leveraging both static and dynamic scene datasets. Given a casual monocular dynamic video, BTimer reconstructs a bullet-time scene within 150ms while reaching state-of-the-art performance on both static and dynamic scene datasets, even compared with optimization-based approaches.
GaussianCut: Interactive segmentation via graph cut for 3D Gaussian Splatting
Nov 12, 2024



We introduce GaussianCut, a new method for interactive multiview segmentation of scenes represented as 3D Gaussians. Our approach allows for selecting the objects to be segmented by interacting with a single view. It accepts intuitive user input, such as point clicks, coarse scribbles, or text. Using 3D Gaussian Splatting (3DGS) as the underlying scene representation simplifies the extraction of objects of interest which are considered to be a subset of the scene's Gaussians. Our key idea is to represent the scene as a graph and use the graph-cut algorithm to minimize an energy function to effectively partition the Gaussians into foreground and background. To achieve this, we construct a graph based on scene Gaussians and devise a segmentation-aligned energy function on the graph to combine user inputs with scene properties. To obtain an initial coarse segmentation, we leverage 2D image/video segmentation models and further refine these coarse estimates using our graph construction. Our empirical evaluations show the adaptability of GaussianCut across a diverse set of scenes. GaussianCut achieves competitive performance with state-of-the-art approaches for 3D segmentation without requiring any additional segmentation-aware training.
3D Gaussian Ray Tracing: Fast Tracing of Particle Scenes
Jul 10, 2024



Particle-based representations of radiance fields such as 3D Gaussian Splatting have found great success for reconstructing and re-rendering of complex scenes. Most existing methods render particles via rasterization, projecting them to screen space tiles for processing in a sorted order. This work instead considers ray tracing the particles, building a bounding volume hierarchy and casting a ray for each pixel using high-performance GPU ray tracing hardware. To efficiently handle large numbers of semi-transparent particles, we describe a specialized rendering algorithm which encapsulates particles with bounding meshes to leverage fast ray-triangle intersections, and shades batches of intersections in depth-order. The benefits of ray tracing are well-known in computer graphics: processing incoherent rays for secondary lighting effects such as shadows and reflections, rendering from highly-distorted cameras common in robotics, stochastically sampling rays, and more. With our renderer, this flexibility comes at little cost compared to rasterization. Experiments demonstrate the speed and accuracy of our approach, as well as several applications in computer graphics and vision. We further propose related improvements to the basic Gaussian representation, including a simple use of generalized kernel functions which significantly reduces particle hit counts.
L4GM: Large 4D Gaussian Reconstruction Model
Jun 14, 2024
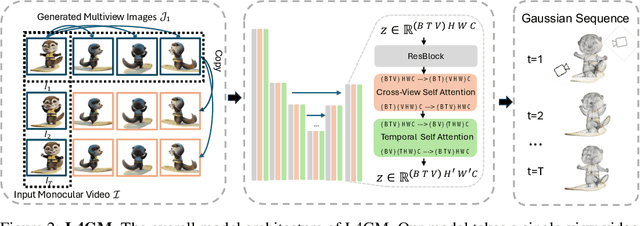
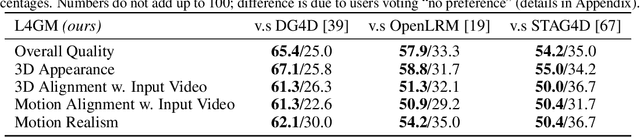
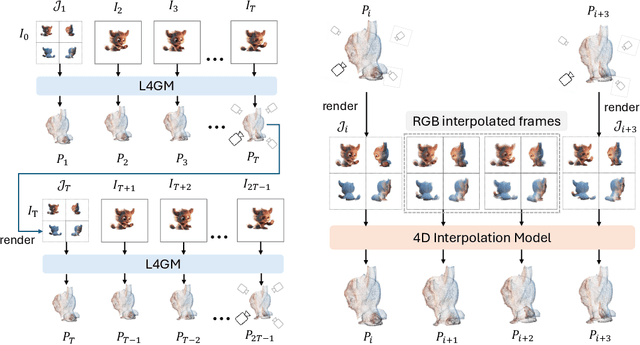
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
RefFusion: Reference Adapted Diffusion Models for 3D Scene Inpainting
Apr 16, 2024


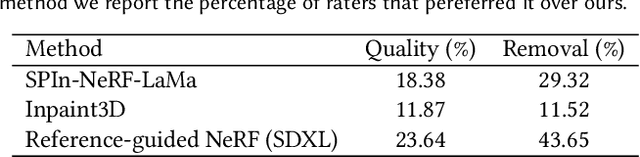
Neural reconstruction approaches are rapidly emerging as the preferred representation for 3D scenes, but their limited editability is still posing a challenge. In this work, we propose an approach for 3D scene inpainting -- the task of coherently replacing parts of the reconstructed scene with desired content. Scene inpainting is an inherently ill-posed task as there exist many solutions that plausibly replace the missing content. A good inpainting method should therefore not only enable high-quality synthesis but also a high degree of control. Based on this observation, we focus on enabling explicit control over the inpainted content and leverage a reference image as an efficient means to achieve this goal. Specifically, we introduce RefFusion, a novel 3D inpainting method based on a multi-scale personalization of an image inpainting diffusion model to the given reference view. The personalization effectively adapts the prior distribution to the target scene, resulting in a lower variance of score distillation objective and hence significantly sharper details. Our framework achieves state-of-the-art results for object removal while maintaining high controllability. We further demonstrate the generality of our formulation on other downstream tasks such as object insertion, scene outpainting, and sparse view reconstruction.