 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial Magic Wand: Material-Aware Grouping of 3D Parts in Untextured Meshes
Mar 18, 2026We introduce the problem of material-aware part grouping in untextured meshes. Many real-world shapes, such as scales of pinecones or windows of buildings, contain repeated structures that share the same material but exhibit geometric variations. When assigning materials to such meshes, these repeated parts often require piece-by-piece manual identification and selection, which is tedious and time-consuming. To address this, we propose Material Magic Wand, a tool that allows artists to select part groups based on their estimated material properties -- when one part is selected, our algorithm automatically retrieves all other parts likely to share the same material. The key component of our approach is a part encoder that generates a material-aware embedding for each 3D part, accounting for both local geometry and global context. We train our model with a supervised contrastive loss that brings embeddings of material-consistent parts closer while separating those of different materials; therefore, part grouping can be achieved by retrieving embeddings that are close to the embedding of the selected part. To benchmark this task, we introduce a curated dataset of 100 shapes with 241 part-level queries. We verify the effectiveness of our method through extensive experiments and demonstrate its practical value in an interactive material assignment application.
GaussianCut: Interactive segmentation via graph cut for 3D Gaussian Splatting
Nov 12, 2024



We introduce GaussianCut, a new method for interactive multiview segmentation of scenes represented as 3D Gaussians. Our approach allows for selecting the objects to be segmented by interacting with a single view. It accepts intuitive user input, such as point clicks, coarse scribbles, or text. Using 3D Gaussian Splatting (3DGS) as the underlying scene representation simplifies the extraction of objects of interest which are considered to be a subset of the scene's Gaussians. Our key idea is to represent the scene as a graph and use the graph-cut algorithm to minimize an energy function to effectively partition the Gaussians into foreground and background. To achieve this, we construct a graph based on scene Gaussians and devise a segmentation-aligned energy function on the graph to combine user inputs with scene properties. To obtain an initial coarse segmentation, we leverage 2D image/video segmentation models and further refine these coarse estimates using our graph construction. Our empirical evaluations show the adaptability of GaussianCut across a diverse set of scenes. GaussianCut achieves competitive performance with state-of-the-art approaches for 3D segmentation without requiring any additional segmentation-aware training.
Satellite Sunroof: High-res Digital Surface Models and Roof Segmentation for Global Solar Mapping
Aug 26, 2024



The transition to renewable energy, particularly solar, is key to mitigating climate change. Google's Solar API aids this transition by estimating solar potential from aerial imagery, but its impact is constrained by geographical coverage. This paper proposes expanding the API's reach using satellite imagery, enabling global solar potential assessment. We tackle challenges involved in building a Digital Surface Model (DSM) and roof instance segmentation from lower resolution and single oblique views using deep learning models. Our models, trained on aligned satellite and aerial datasets, produce 25cm DSMs and roof segments. With ~1m DSM MAE on buildings, ~5deg roof pitch error and ~56% IOU on roof segmentation, they significantly enhance the Solar API's potential to promote solar adoption.
Multimodal contrastive learning for remote sensing tasks
Sep 06, 2022
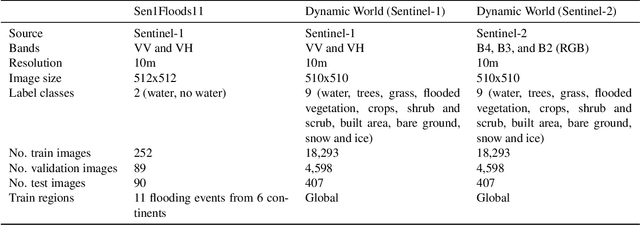

Self-supervised methods have shown tremendous success in the field of computer vision, including applications in remote sensing and medical imaging. Most popular contrastive-loss based methods like SimCLR, MoCo, MoCo-v2 use multiple views of the same image by applying contrived augmentations on the image to create positive pairs and contrast them with negative examples. Although these techniques work well, most of these techniques have been tuned on ImageNet (and similar computer vision datasets). While there have been some attempts to capture a richer set of deformations in the positive samples, in this work, we explore a promising alternative to generating positive examples for remote sensing data within the contrastive learning framework. Images captured from different sensors at the same location and nearby timestamps can be thought of as strongly augmented instances of the same scene, thus removing the need to explore and tune a set of hand crafted strong augmentations. In this paper, we propose a simple dual-encoder framework, which is pre-trained on a large unlabeled dataset (~1M) of Sentinel-1 and Sentinel-2 image pairs. We test the embeddings on two remote sensing downstream tasks: flood segmentation and land cover mapping, and empirically show that embeddings learnt from this technique outperform the conventional technique of collecting positive examples via aggressive data augmentations.
Predicting the success of Gradient Descent for a particular Dataset-Architecture-Initialization (DAI)
Nov 25, 2021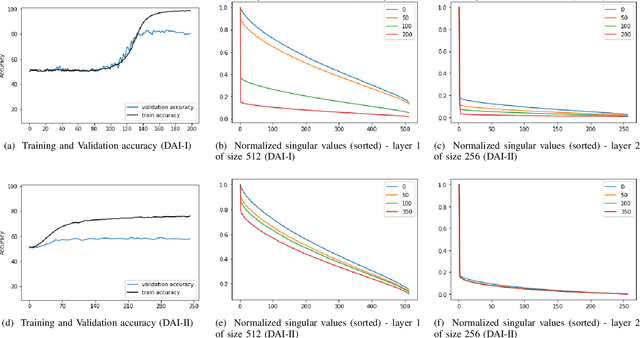
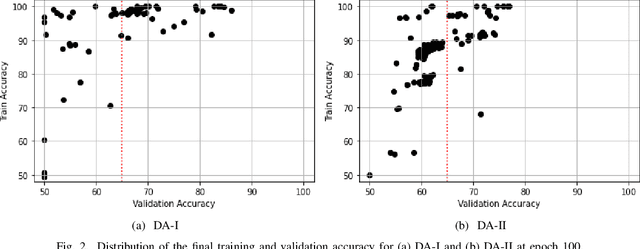
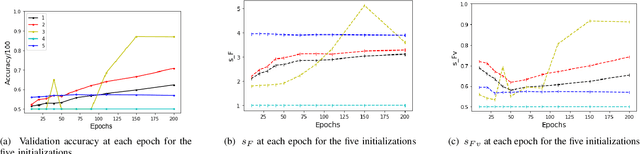
Despite their massive success, training successful deep neural networks still largely relies on experimentally choosing an architecture, hyper-parameters, initialization, and training mechanism. In this work, we focus on determining the success of standard gradient descent method for training deep neural networks on a specified dataset, architecture, and initialization (DAI) combination. Through extensive systematic experiments, we show that the evolution of singular values of the matrix obtained from the hidden layers of a DNN can aid in determining the success of gradient descent technique to train a DAI, even in the absence of validation labels in the supervised learning paradigm. This phenomenon can facilitate early give-up, stopping the training of neural networks which are predicted to not generalize well, early in the training process. Our experimentation across multiple datasets, architectures, and initializations reveals that the proposed scores can more accurately predict the success of a DAI than simply relying on the validation accuracy at earlier epochs to make a judgment.