 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgricultural Landscape Understanding At Country-Scale
Nov 08, 2024Agricultural landscapes are quite complex, especially in the Global South where fields are smaller, and agricultural practices are more varied. In this paper we report on our progress in digitizing the agricultural landscape (natural and man-made) in our study region of India. We use high resolution imagery and a UNet style segmentation model to generate the first of its kind national-scale multi-class panoptic segmentation output. Through this work we have been able to identify individual fields across 151.7M hectares, and delineating key features such as water resources and vegetation. We share how this output was validated by our team and externally by downstream users, including some sample use cases that can lead to targeted data driven decision making. We believe this dataset will contribute towards digitizing agriculture by generating the foundational baselayer.
Satellite Sunroof: High-res Digital Surface Models and Roof Segmentation for Global Solar Mapping
Aug 26, 2024



The transition to renewable energy, particularly solar, is key to mitigating climate change. Google's Solar API aids this transition by estimating solar potential from aerial imagery, but its impact is constrained by geographical coverage. This paper proposes expanding the API's reach using satellite imagery, enabling global solar potential assessment. We tackle challenges involved in building a Digital Surface Model (DSM) and roof instance segmentation from lower resolution and single oblique views using deep learning models. Our models, trained on aligned satellite and aerial datasets, produce 25cm DSMs and roof segments. With ~1m DSM MAE on buildings, ~5deg roof pitch error and ~56% IOU on roof segmentation, they significantly enhance the Solar API's potential to promote solar adoption.
Cross Modal Distillation for Flood Extent Mapping
Feb 16, 2023The increasing intensity and frequency of floods is one of the many consequences of our changing climate. In this work, we explore ML techniques that improve the flood detection module of an operational early flood warning system. Our method exploits an unlabelled dataset of paired multi-spectral and Synthetic Aperture Radar (SAR) imagery to reduce the labeling requirements of a purely supervised learning method. Prior works have used unlabelled data by creating weak labels out of them. However, from our experiments we noticed that such a model still ends up learning the label mistakes in those weak labels. Motivated by knowledge distillation and semi supervised learning, we explore the use of a teacher to train a student with the help of a small hand labelled dataset and a large unlabelled dataset. Unlike the conventional self distillation setup, we propose a cross modal distillation framework that transfers supervision from a teacher trained on richer modality (multi-spectral images) to a student model trained on SAR imagery. The trained models are then tested on the Sen1Floods11 dataset. Our model outperforms the Sen1Floods11 baseline model trained on the weak labeled SAR imagery by an absolute margin of 6.53% Intersection-over-Union (IoU) on the test split.
A Machine Learning Data Fusion Model for Soil Moisture Retrieval
Jun 20, 2022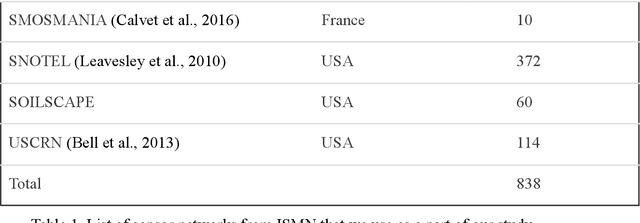
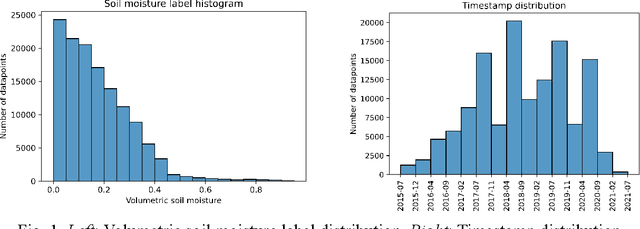
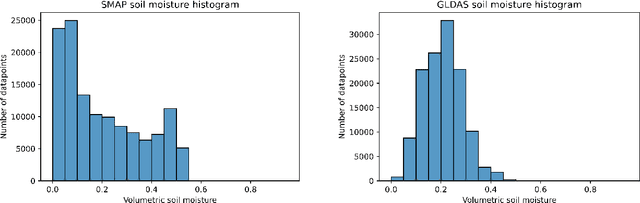
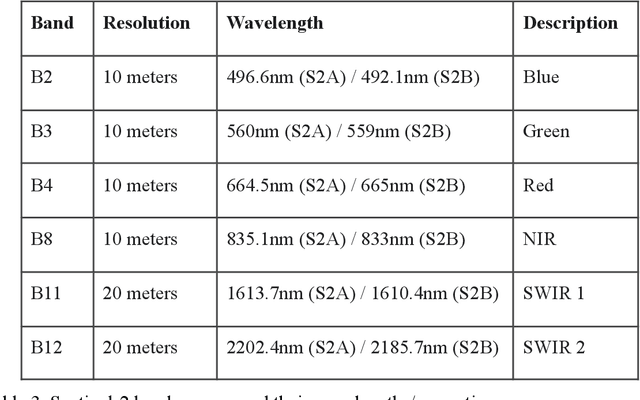
We develop a deep learning based convolutional-regression model that estimates the volumetric soil moisture content in the top ~5 cm of soil. Input predictors include Sentinel-1 (active radar), Sentinel-2 (optical imagery), and SMAP (passive radar) as well as geophysical variables from SoilGrids and modelled soil moisture fields from GLDAS. The model was trained and evaluated on data from ~1300 in-situ sensors globally over the period 2015 - 2021 and obtained an average per-sensor correlation of 0.727 and ubRMSE of 0.054, and can be used to produce a soil moisture map at a nominal 320m resolution. These results are benchmarked against 13 other soil moisture works at different locations, and an ablation study was used to identify important predictors.
"How to rate a video game?" - A prediction system for video games based on multimodal information
May 29, 2018



Video games have become an integral part of most people's lives in recent times. This led to an abundance of data related to video games being shared online. However, this comes with issues such as incorrect ratings, reviews or anything that is being shared. Recommendation systems are powerful tools that help users by providing them with meaningful recommendations. A straightforward approach would be to predict the scores of video games based on other information related to the game. It could be used as a means to validate user-submitted ratings as well as provide recommendations. This work provides a method to predict the G-Score, that defines how good a video game is, from its trailer (video) and summary (text). We first propose models to predict the G-Score based on the trailer alone (unimodal). Later on, we show that considering information from multiple modalities helps the models perform better compared to using information from videos alone. Since we couldn't find any suitable multimodal video game dataset, we created our own dataset named VGD (Video Game Dataset) and provide it along with this work. The approach mentioned here can be generalized to other multimodal datasets such as movie trailers and summaries etc. Towards the end, we talk about the shortcomings of the work and some methods to overcome them.
Hybrid Binary Networks: Optimizing for Accuracy, Efficiency and Memory
Apr 11, 2018
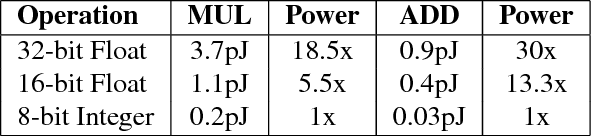
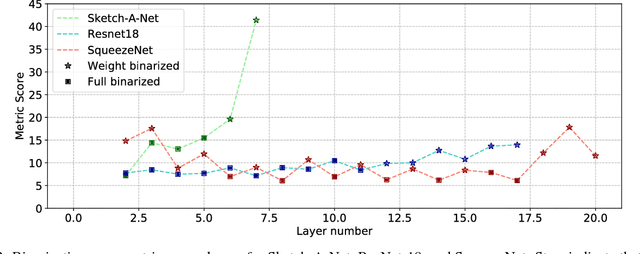
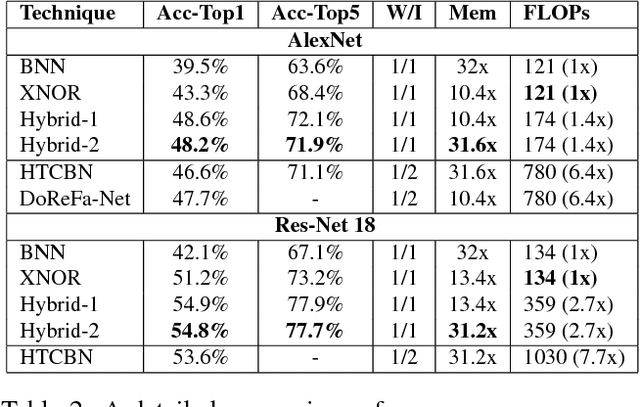
Binarization is an extreme network compression approach that provides large computational speedups along with energy and memory savings, albeit at significant accuracy costs. We investigate the question of where to binarize inputs at layer-level granularity and show that selectively binarizing the inputs to specific layers in the network could lead to significant improvements in accuracy while preserving most of the advantages of binarization. We analyze the binarization tradeoff using a metric that jointly models the input binarization-error and computational cost and introduce an efficient algorithm to select layers whose inputs are to be binarized. Practical guidelines based on insights obtained from applying the algorithm to a variety of models are discussed. Experiments on Imagenet dataset using AlexNet and ResNet-18 models show 3-4% improvements in accuracy over fully binarized networks with minimal impact on compression and computational speed. The improvements are even more substantial on sketch datasets like TU-Berlin, where we match state-of-the-art accuracy as well, getting over 8% increase in accuracies. We further show that our approach can be applied in tandem with other forms of compression that deal with individual layers or overall model compression (e.g., SqueezeNets). Unlike previous quantization approaches, we are able to binarize the weights in the last layers of a network, which often have a large number of parameters, resulting in significant improvement in accuracy over fully binarized models.
Distribution-Aware Binarization of Neural Networks for Sketch Recognition
Apr 09, 2018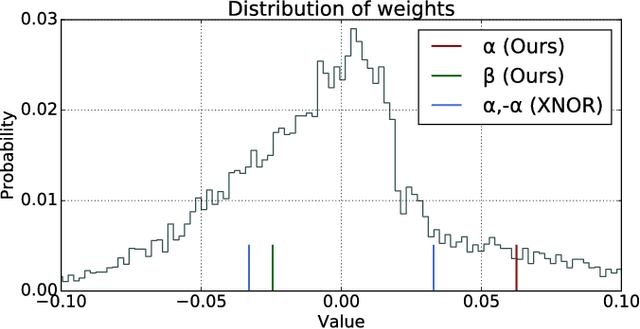

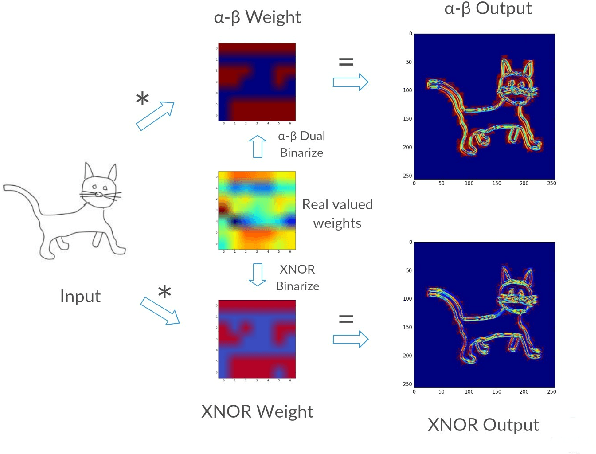

Deep neural networks are highly effective at a range of computational tasks. However, they tend to be computationally expensive, especially in vision-related problems, and also have large memory requirements. One of the most effective methods to achieve significant improvements in computational/spatial efficiency is to binarize the weights and activations in a network. However, naive binarization results in accuracy drops when applied to networks for most tasks. In this work, we present a highly generalized, distribution-aware approach to binarizing deep networks that allows us to retain the advantages of a binarized network, while reducing accuracy drops. We also develop efficient implementations for our proposed approach across different architectures. We present a theoretical analysis of the technique to show the effective representational power of the resulting layers, and explore the forms of data they model best. Experiments on popular datasets show that our technique offers better accuracies than naive binarization, while retaining the same benefits that binarization provides - with respect to run-time compression, reduction of computational costs, and power consumption.