 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion2Print: Deep Flash-Non-Flash Fusion for Contactless Fingerprint Matching
Jan 05, 2026Contactless fingerprint recognition offers a hygienic and convenient alternative to contact-based systems, enabling rapid acquisition without latent prints, pressure artifacts, or hygiene risks. However, contactless images often show degraded ridge clarity due to illumination variation, subcutaneous skin discoloration, and specular reflections. Flash captures preserve ridge detail but introduce noise, whereas non-flash captures reduce noise but lower ridge contrast. We propose Fusion2Print (F2P), the first framework to systematically capture and fuse paired flash-non-flash contactless fingerprints. We construct a custom paired dataset, FNF Database, and perform manual flash-non-flash subtraction to isolate ridge-preserving signals. A lightweight attention-based fusion network also integrates both modalities, emphasizing informative channels and suppressing noise, and then a U-Net enhancement module produces an optimally weighted grayscale image. Finally, a deep embedding model with cross-domain compatibility, generates discriminative and robust representations in a unified embedding space compatible with both contactless and contact-based fingerprints for verification. F2P enhances ridge clarity and achieves superior recognition performance (AUC=0.999, EER=1.12%) over single-capture baselines (Verifinger, DeepPrint).
PS-StyleGAN: Illustrative Portrait Sketching using Attention-Based Style Adaptation
Aug 31, 2024Portrait sketching involves capturing identity specific attributes of a real face with abstract lines and shades. Unlike photo-realistic images, a good portrait sketch generation method needs selective attention to detail, making the problem challenging. This paper introduces \textbf{Portrait Sketching StyleGAN (PS-StyleGAN)}, a style transfer approach tailored for portrait sketch synthesis. We leverage the semantic $W+$ latent space of StyleGAN to generate portrait sketches, allowing us to make meaningful edits, like pose and expression alterations, without compromising identity. To achieve this, we propose the use of Attentive Affine transform blocks in our architecture, and a training strategy that allows us to change StyleGAN's output without finetuning it. These blocks learn to modify style latent code by paying attention to both content and style latent features, allowing us to adapt the outputs of StyleGAN in an inversion-consistent manner. Our approach uses only a few paired examples ($\sim 100$) to model a style and has a short training time. We demonstrate PS-StyleGAN's superiority over the current state-of-the-art methods on various datasets, qualitatively and quantitatively.
Enhancement-Driven Pretraining for Robust Fingerprint Representation Learning
Feb 16, 2024



Fingerprint recognition stands as a pivotal component of biometric technology, with diverse applications from identity verification to advanced search tools. In this paper, we propose a unique method for deriving robust fingerprint representations by leveraging enhancement-based pre-training. Building on the achievements of U-Net-based fingerprint enhancement, our method employs a specialized encoder to derive representations from fingerprint images in a self-supervised manner. We further refine these representations, aiming to enhance the verification capabilities. Our experimental results, tested on publicly available fingerprint datasets, reveal a marked improvement in verification performance against established self-supervised training techniques. Our findings not only highlight the effectiveness of our method but also pave the way for potential advancements. Crucially, our research indicates that it is feasible to extract meaningful fingerprint representations from degraded images without relying on enhanced samples.
* 8 pages, 4 figures, Accepted at 19th VISIGRAPP 2024: VISAPP conference
Finger-UNet: A U-Net based Multi-Task Architecture for Deep Fingerprint Enhancement
Oct 01, 2023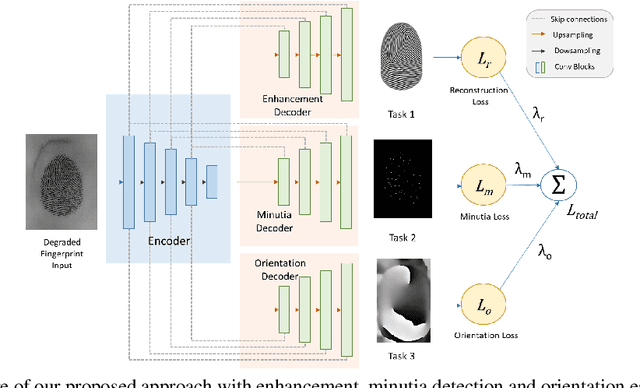



For decades, fingerprint recognition has been prevalent for security, forensics, and other biometric applications. However, the availability of good-quality fingerprints is challenging, making recognition difficult. Fingerprint images might be degraded with a poor ridge structure and noisy or less contrasting backgrounds. Hence, fingerprint enhancement plays a vital role in the early stages of the fingerprint recognition/verification pipeline. In this paper, we investigate and improvise the encoder-decoder style architecture and suggest intuitive modifications to U-Net to enhance low-quality fingerprints effectively. We investigate the use of Discrete Wavelet Transform (DWT) for fingerprint enhancement and use a wavelet attention module instead of max pooling which proves advantageous for our task. Moreover, we replace regular convolutions with depthwise separable convolutions, which significantly reduces the memory footprint of the model without degrading the performance. We also demonstrate that incorporating domain knowledge with fingerprint minutiae prediction task can improve fingerprint reconstruction through multi-task learning. Furthermore, we also integrate the orientation estimation task to propagate the knowledge of ridge orientations to enhance the performance further. We present the experimental results and evaluate our model on FVC 2002 and NIST SD302 databases to show the effectiveness of our approach compared to previous works.
* 8 pages, 5 figures, Accepted at 18th VISIGRAPP 2023: VISAPP conference
Face Cartoonisation For Various Poses Using StyleGAN
Sep 26, 2023This paper presents an innovative approach to achieve face cartoonisation while preserving the original identity and accommodating various poses. Unlike previous methods in this field that relied on conditional-GANs, which posed challenges related to dataset requirements and pose training, our approach leverages the expressive latent space of StyleGAN. We achieve this by introducing an encoder that captures both pose and identity information from images and generates a corresponding embedding within the StyleGAN latent space. By subsequently passing this embedding through a pre-trained generator, we obtain the desired cartoonised output. While many other approaches based on StyleGAN necessitate a dedicated and fine-tuned StyleGAN model, our method stands out by utilizing an already-trained StyleGAN designed to produce realistic facial images. We show by extensive experimentation how our encoder adapts the StyleGAN output to better preserve identity when the objective is cartoonisation.
Transformer based Fingerprint Feature Extraction
Sep 08, 2022
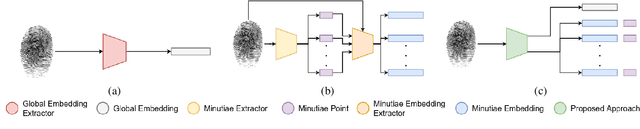
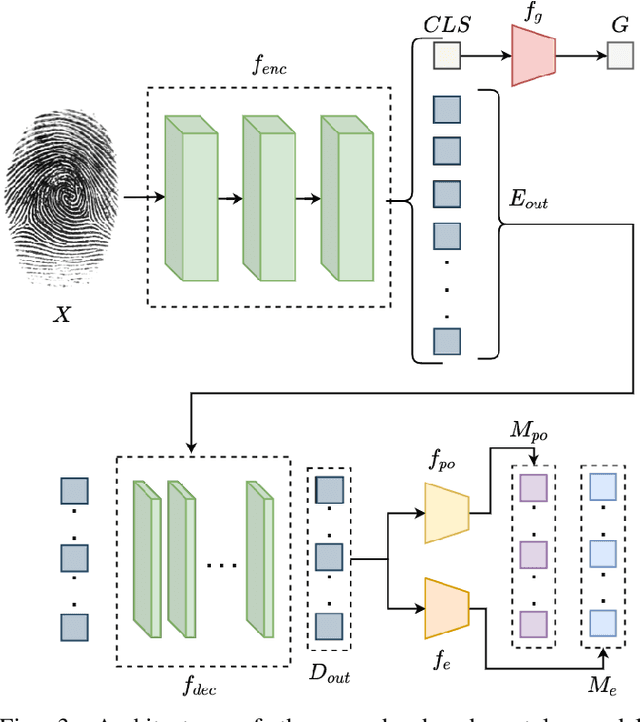
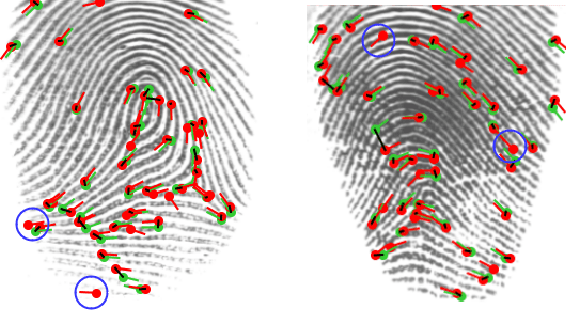
Fingerprint feature extraction is a task that is solved using either a global or a local representation. State-of-the-art global approaches use heavy deep learning models to process the full fingerprint image at once, which makes the corresponding approach memory intensive. On the other hand, local approaches involve minutiae based patch extraction, multiple feature extraction steps and an expensive matching stage, which make the corresponding approach time intensive. However, both these approaches provide useful and sometimes exclusive insights for solving the problem. Using both approaches together for extracting fingerprint representations is semantically useful but quite inefficient. Our convolutional transformer based approach with an in-built minutiae extractor provides a time and memory efficient solution to extract a global as well as a local representation of the fingerprint. The use of these representations along with a smart matching process gives us state-of-the-art performance across multiple databases. The project page can be found at https://saraansh1999.github.io/global-plus-local-fp-transformer.
A Unified Model for Fingerprint Authentication and Presentation Attack Detection
Apr 07, 2021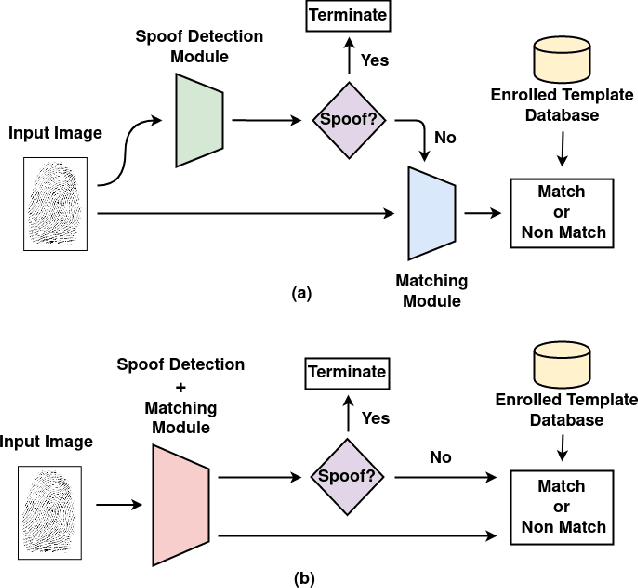

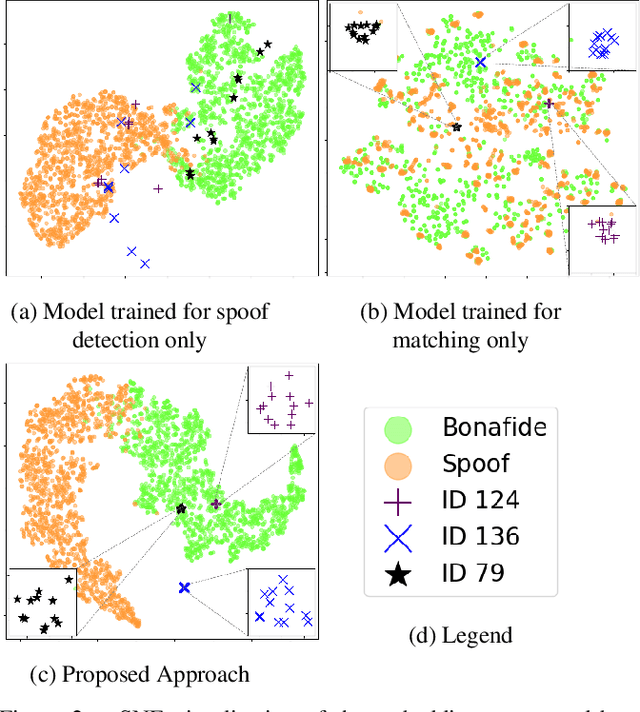
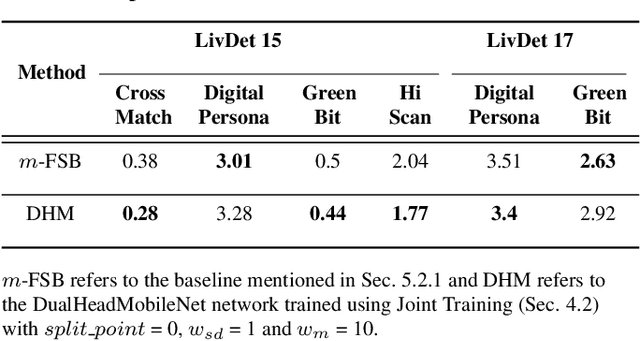
Typical fingerprint recognition systems are comprised of a spoof detection module and a subsequent recognition module, running one after the other. In this paper, we reformulate the workings of a typical fingerprint recognition system. In particular, we posit that both spoof detection and fingerprint recognition are correlated tasks. Therefore, rather than performing the two tasks separately, we propose a joint model for spoof detection and matching to simultaneously perform both tasks without compromising the accuracy of either task. We demonstrate the capability of our joint model to obtain an authentication accuracy (1:1 matching) of TAR = 100% @ FAR = 0.1% on the FVC 2006 DB2A dataset while achieving a spoof detection ACE of 1.44% on the LiveDet 2015 dataset, both maintaining the performance of stand-alone methods. In practice, this reduces the time and memory requirements of the fingerprint recognition system by 50% and 40%, respectively; a significant advantage for recognition systems running on resource-constrained devices and communication channels.
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Nov 17, 2020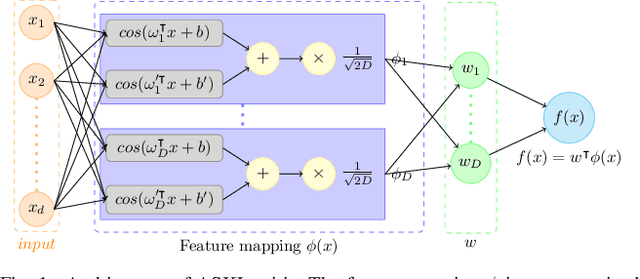
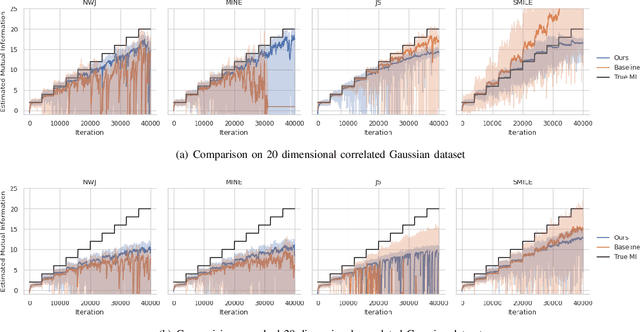
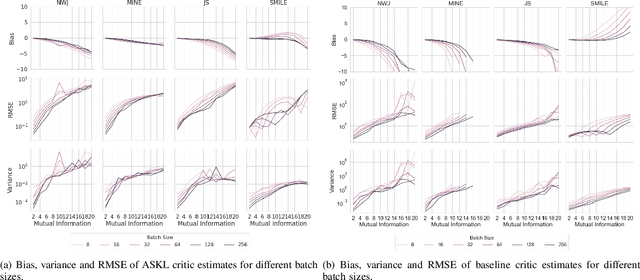
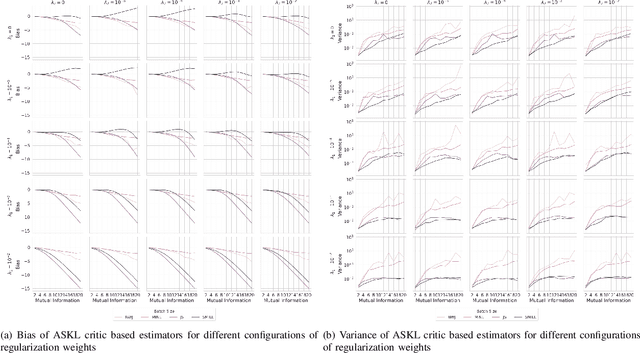
Mutual information (MI) is an information-theoretic measure of dependency between two random variables. Several methods to estimate MI, from samples of two random variables with unknown underlying probability distributions have been proposed in the literature. Recent methods realize parametric probability distributions or critic as a neural network to approximate unknown density ratios. The approximated density ratios are used to estimate different variational lower bounds of MI. While these methods provide reliable estimation when the true MI is low, they produce high variance estimates in cases of high MI. We argue that the high variance characteristic is due to the uncontrolled complexity of the critic's hypothesis space. In support of this argument, we use the data-driven Rademacher complexity of the hypothesis space associated with the critic's architecture to analyse generalization error bound of variational lower bound estimates of MI. In the proposed work, we show that it is possible to negate the high variance characteristics of these estimators by constraining the critic's hypothesis space to Reproducing Hilbert Kernel Space (RKHS), which corresponds to a kernel learned using Automated Spectral Kernel Learning (ASKL). By analysing the aforementioned generalization error bounds, we augment the overall optimisation objective with effective regularisation term. We empirically demonstrate the efficacy of this regularization in enforcing proper bias variance tradeoff on four variational lower bounds, namely NWJ, MINE, JS and SMILE.
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Nov 17, 2020
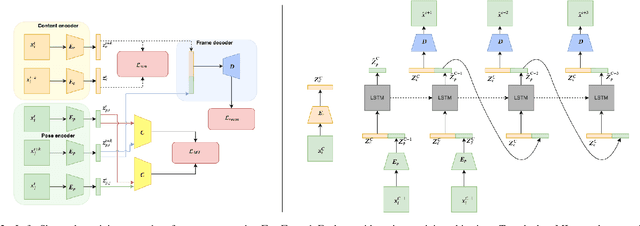
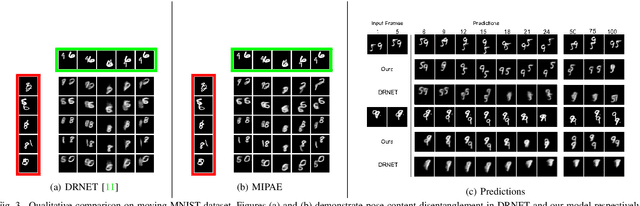

Video Prediction is an interesting and challenging task of predicting future frames from a given set context frames that belong to a video sequence. Video prediction models have found prospective applications in Maneuver Planning, Health care, Autonomous Navigation and Simulation. One of the major challenges in future frame generation is due to the high dimensional nature of visual data. In this work, we propose Mutual Information Predictive Auto-Encoder (MIPAE) framework, that reduces the task of predicting high dimensional video frames by factorising video representations into content and low dimensional pose latent variables that are easy to predict. A standard LSTM network is used to predict these low dimensional pose representations. Content and the predicted pose representations are decoded to generate future frames. Our approach leverages the temporal structure of the latent generative factors of a video and a novel mutual information loss to learn disentangled video representations. We also propose a metric based on mutual information gap (MIG) to quantitatively access the effectiveness of disentanglement on DSprites and MPI3D-real datasets. MIG scores corroborate with the visual superiority of frames predicted by MIPAE. We also compare our method quantitatively on evaluation metrics LPIPS, SSIM and PSNR.
Understanding Dynamic Scenes using Graph Convolution Networks
May 15, 2020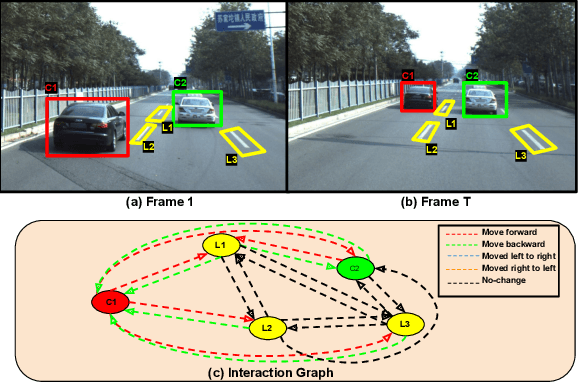
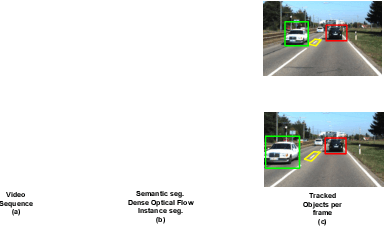
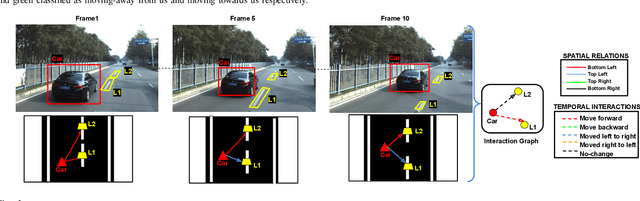
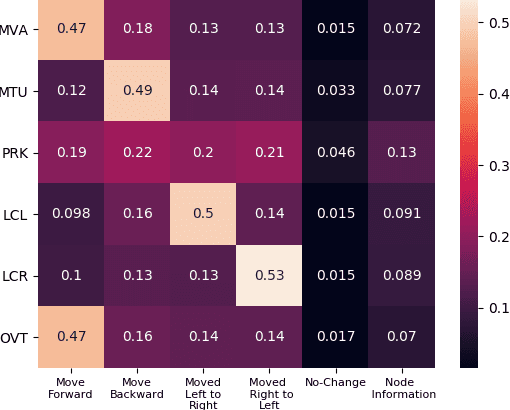
We present a novel Multi Relational Graph Convolutional Network (MRGCN) to model on-road vehicle behaviours from a sequence of temporally ordered frames as grabbed by a moving monocular camera. The input to MRGCN is a Multi Relational Graph (MRG) where the nodes of the graph represent the active and passive participants/agents in the scene while the bidrectional edges that connect every pair of nodes are encodings of the spatio-temporal relations. The bidirectional edges of the graph encode the temporal interactions between the agents that constitute the two nodes of the edge. The proposed method of obtaining his encoding is shown to be specifically suited for the problem at hand as it outperforms more complex end to end learning methods that do not use such intermediate representations of evolved spatio-temporal relations between agent pairs. We show significant performance gain in the form of behaviour classification accuracy on a variety of datasets from different parts of the globe over prior methods as well as show seamless transfer without any resort to fine-tuning across multiple datasets. Such behaviour prediction methods find immediate relevance in a variety of navigation tasks such as behaviour planning, state estimation as well as in applications relating to detection of traffic violations over videos.