 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAXCEL: Automated eXplainable Consistency Evaluation using LLMs
Sep 25, 2024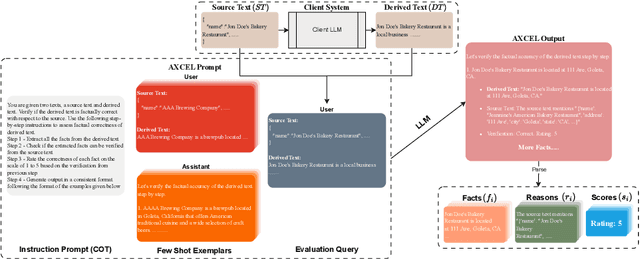
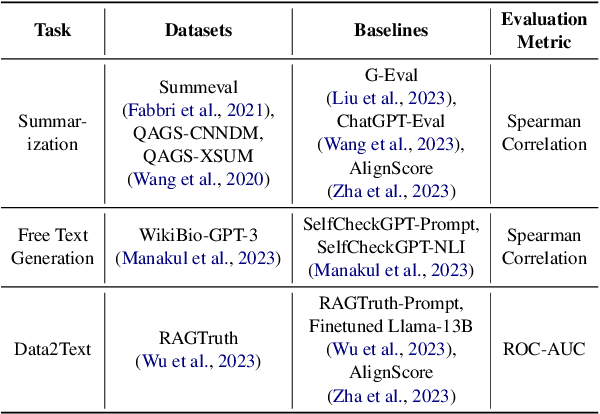
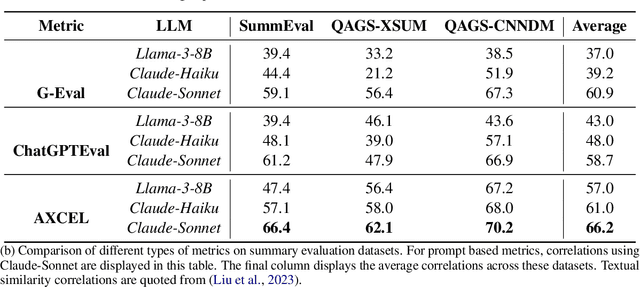
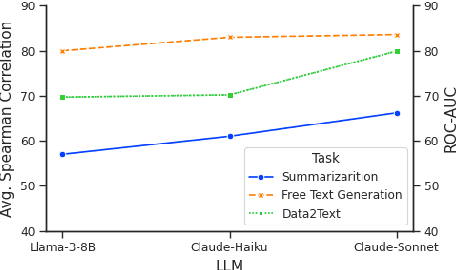
Large Language Models (LLMs) are widely used in both industry and academia for various tasks, yet evaluating the consistency of generated text responses continues to be a challenge. Traditional metrics like ROUGE and BLEU show a weak correlation with human judgment. More sophisticated metrics using Natural Language Inference (NLI) have shown improved correlations but are complex to implement, require domain-specific training due to poor cross-domain generalization, and lack explainability. More recently, prompt-based metrics using LLMs as evaluators have emerged; while they are easier to implement, they still lack explainability and depend on task-specific prompts, which limits their generalizability. This work introduces Automated eXplainable Consistency Evaluation using LLMs (AXCEL), a prompt-based consistency metric which offers explanations for the consistency scores by providing detailed reasoning and pinpointing inconsistent text spans. AXCEL is also a generalizable metric which can be adopted to multiple tasks without changing the prompt. AXCEL outperforms both non-prompt and prompt-based state-of-the-art (SOTA) metrics in detecting inconsistencies across summarization by 8.7%, free text generation by 6.2%, and data-to-text conversion tasks by 29.4%. We also evaluate the influence of underlying LLMs on prompt based metric performance and recalibrate the SOTA prompt-based metrics with the latest LLMs for fair comparison. Further, we show that AXCEL demonstrates strong performance using open source LLMs.
Unveiling the Power of Self-Attention for Shipping Cost Prediction: The Rate Card Transformer
Nov 20, 2023Amazon ships billions of packages to its customers annually within the United States. Shipping cost of these packages are used on the day of shipping (day 0) to estimate profitability of sales. Downstream systems utilize these days 0 profitability estimates to make financial decisions, such as pricing strategies and delisting loss-making products. However, obtaining accurate shipping cost estimates on day 0 is complex for reasons like delay in carrier invoicing or fixed cost components getting recorded at monthly cadence. Inaccurate shipping cost estimates can lead to bad decision, such as pricing items too low or high, or promoting the wrong product to the customers. Current solutions for estimating shipping costs on day 0 rely on tree-based models that require extensive manual engineering efforts. In this study, we propose a novel architecture called the Rate Card Transformer (RCT) that uses self-attention to encode all package shipping information such as package attributes, carrier information and route plan. Unlike other transformer-based tabular models, RCT has the ability to encode a variable list of one-to-many relations of a shipment, allowing it to capture more information about a shipment. For example, RCT can encode properties of all products in a package. Our results demonstrate that cost predictions made by the RCT have 28.82% less error compared to tree-based GBDT model. Moreover, the RCT outperforms the state-of-the-art transformer-based tabular model, FTTransformer, by 6.08%. We also illustrate that the RCT learns a generalized manifold of the rate card that can improve the performance of tree-based models.
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Nov 17, 2020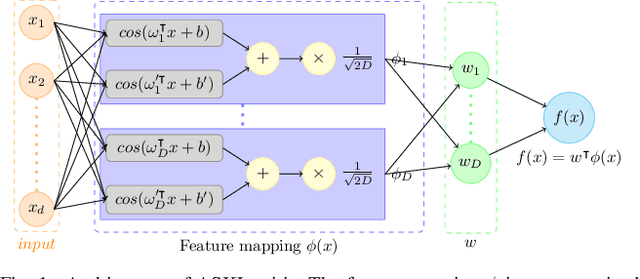
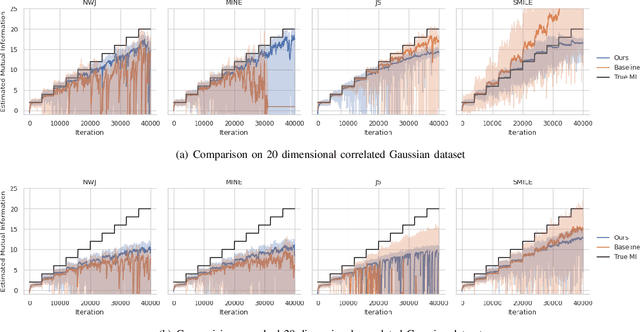
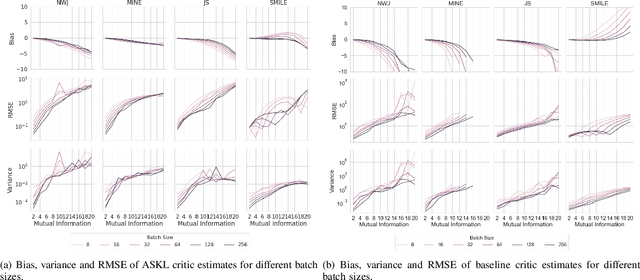
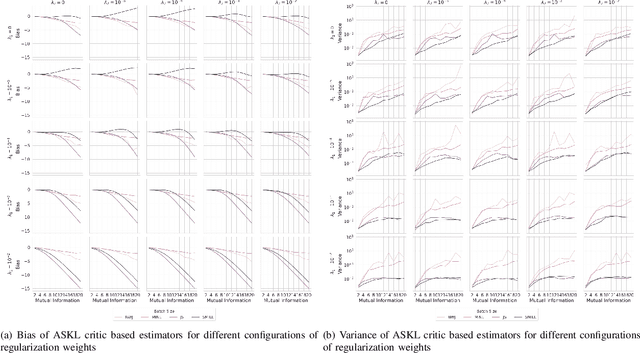
Mutual information (MI) is an information-theoretic measure of dependency between two random variables. Several methods to estimate MI, from samples of two random variables with unknown underlying probability distributions have been proposed in the literature. Recent methods realize parametric probability distributions or critic as a neural network to approximate unknown density ratios. The approximated density ratios are used to estimate different variational lower bounds of MI. While these methods provide reliable estimation when the true MI is low, they produce high variance estimates in cases of high MI. We argue that the high variance characteristic is due to the uncontrolled complexity of the critic's hypothesis space. In support of this argument, we use the data-driven Rademacher complexity of the hypothesis space associated with the critic's architecture to analyse generalization error bound of variational lower bound estimates of MI. In the proposed work, we show that it is possible to negate the high variance characteristics of these estimators by constraining the critic's hypothesis space to Reproducing Hilbert Kernel Space (RKHS), which corresponds to a kernel learned using Automated Spectral Kernel Learning (ASKL). By analysing the aforementioned generalization error bounds, we augment the overall optimisation objective with effective regularisation term. We empirically demonstrate the efficacy of this regularization in enforcing proper bias variance tradeoff on four variational lower bounds, namely NWJ, MINE, JS and SMILE.
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Nov 17, 2020
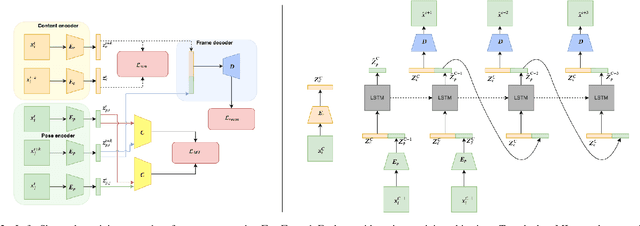
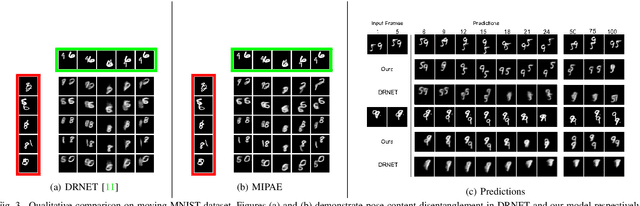

Video Prediction is an interesting and challenging task of predicting future frames from a given set context frames that belong to a video sequence. Video prediction models have found prospective applications in Maneuver Planning, Health care, Autonomous Navigation and Simulation. One of the major challenges in future frame generation is due to the high dimensional nature of visual data. In this work, we propose Mutual Information Predictive Auto-Encoder (MIPAE) framework, that reduces the task of predicting high dimensional video frames by factorising video representations into content and low dimensional pose latent variables that are easy to predict. A standard LSTM network is used to predict these low dimensional pose representations. Content and the predicted pose representations are decoded to generate future frames. Our approach leverages the temporal structure of the latent generative factors of a video and a novel mutual information loss to learn disentangled video representations. We also propose a metric based on mutual information gap (MIG) to quantitatively access the effectiveness of disentanglement on DSprites and MPI3D-real datasets. MIG scores corroborate with the visual superiority of frames predicted by MIPAE. We also compare our method quantitatively on evaluation metrics LPIPS, SSIM and PSNR.