 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Denario project: Deep knowledge AI agents for scientific discovery
Oct 30, 2025We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud.
Open Source Planning & Control System with Language Agents for Autonomous Scientific Discovery
Jul 09, 2025We present a multi-agent system for automation of scientific research tasks, cmbagent. The system is formed by about 30 Large Language Model (LLM) agents and implements a Planning & Control strategy to orchestrate the agentic workflow, with no human-in-the-loop at any point. Each agent specializes in a different task (performing retrieval on scientific papers and codebases, writing code, interpreting results, critiquing the output of other agents) and the system is able to execute code locally. We successfully apply cmbagent to carry out a PhD level cosmology task (the measurement of cosmological parameters using supernova data) and evaluate its performance on two benchmark sets, finding superior performance over state-of-the-art LLMs. The source code is available on GitHub, demonstration videos are also available, and the system is deployed on HuggingFace and will be available on the cloud.
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Nov 17, 2020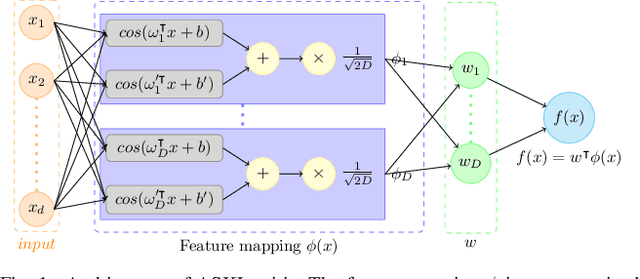
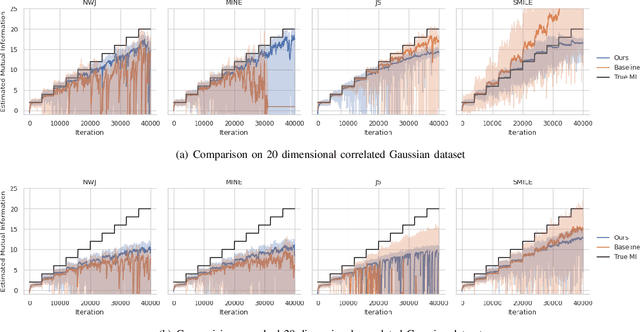
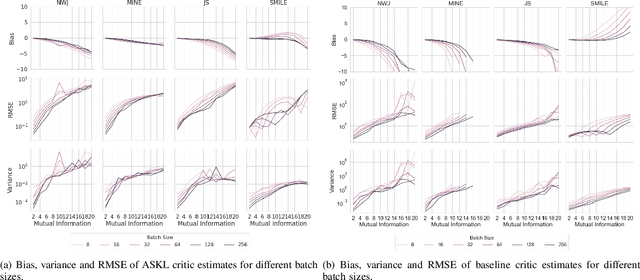
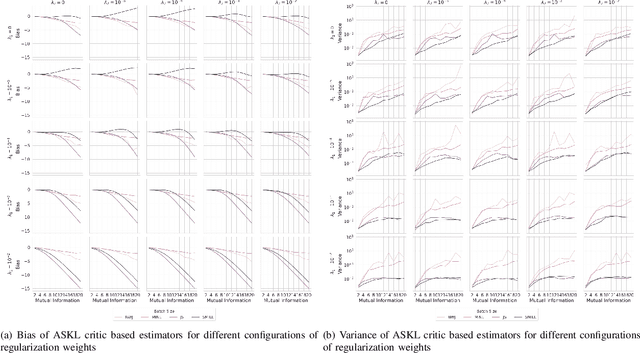
Mutual information (MI) is an information-theoretic measure of dependency between two random variables. Several methods to estimate MI, from samples of two random variables with unknown underlying probability distributions have been proposed in the literature. Recent methods realize parametric probability distributions or critic as a neural network to approximate unknown density ratios. The approximated density ratios are used to estimate different variational lower bounds of MI. While these methods provide reliable estimation when the true MI is low, they produce high variance estimates in cases of high MI. We argue that the high variance characteristic is due to the uncontrolled complexity of the critic's hypothesis space. In support of this argument, we use the data-driven Rademacher complexity of the hypothesis space associated with the critic's architecture to analyse generalization error bound of variational lower bound estimates of MI. In the proposed work, we show that it is possible to negate the high variance characteristics of these estimators by constraining the critic's hypothesis space to Reproducing Hilbert Kernel Space (RKHS), which corresponds to a kernel learned using Automated Spectral Kernel Learning (ASKL). By analysing the aforementioned generalization error bounds, we augment the overall optimisation objective with effective regularisation term. We empirically demonstrate the efficacy of this regularization in enforcing proper bias variance tradeoff on four variational lower bounds, namely NWJ, MINE, JS and SMILE.
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Nov 17, 2020
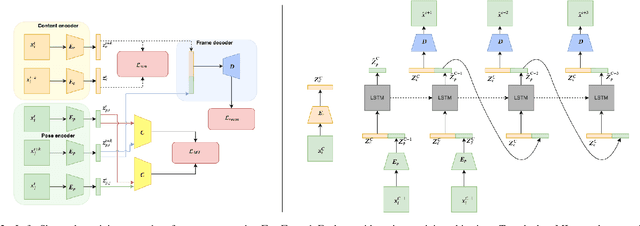
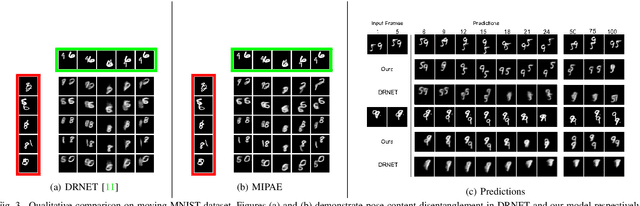

Video Prediction is an interesting and challenging task of predicting future frames from a given set context frames that belong to a video sequence. Video prediction models have found prospective applications in Maneuver Planning, Health care, Autonomous Navigation and Simulation. One of the major challenges in future frame generation is due to the high dimensional nature of visual data. In this work, we propose Mutual Information Predictive Auto-Encoder (MIPAE) framework, that reduces the task of predicting high dimensional video frames by factorising video representations into content and low dimensional pose latent variables that are easy to predict. A standard LSTM network is used to predict these low dimensional pose representations. Content and the predicted pose representations are decoded to generate future frames. Our approach leverages the temporal structure of the latent generative factors of a video and a novel mutual information loss to learn disentangled video representations. We also propose a metric based on mutual information gap (MIG) to quantitatively access the effectiveness of disentanglement on DSprites and MPI3D-real datasets. MIG scores corroborate with the visual superiority of frames predicted by MIPAE. We also compare our method quantitatively on evaluation metrics LPIPS, SSIM and PSNR.