 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Scientists as Engines of Discovery: A Case for Development within Reformed Institutions
Jun 22, 2026Agentic artificial intelligence (AI) systems are beginning to assist, accelerate, and partially automate scientific discovery, performing tasks that span literature synthesis, code generation, data analysis, hypothesis proposal, and model criticism. We argue that this transition is qualitative rather than incremental, and that suitably designed multi-agent systems may evolve from passive computational tools into ``AI scientists'' that can expand the hypothesis-generating and verification capacity of science. Such systems must be developed and deployed within a scientific ecosystem fit for purpose: institutions must be redesigned for verification, accountability, interpretability, and dual-use safety. We sketch how multi-agent architectures, illustrated by the prototype framework \textit{Denario}, accelerate the discovery cycle and traverse model spaces beyond human reach; examine what this implies for authorship, peer review, and the enduring role of human scientists; and close with recommendations for governing AI as an epistemic actor rather than a mere instrument.
Galaxy Phase-Space and Field-Level Cosmology: The Strength of Semi-Analytic Models
Dec 11, 2025Semi-analytic models are a widely used approach to simulate galaxy properties within a cosmological framework, relying on simplified yet physically motivated prescriptions. They have also proven to be an efficient alternative for generating accurate galaxy catalogs, offering a faster and less computationally expensive option compared to full hydrodynamical simulations. In this paper, we demonstrate that using only galaxy $3$D positions and radial velocities, we can train a graph neural network coupled to a moment neural network to obtain a robust machine learning based model capable of estimating the matter density parameters, $Ω_{\rm m}$, with a precision of approximately 10%. The network is trained on ($25 h^{-1}$Mpc)$^3$ volumes of galaxy catalogs from L-Galaxies and can successfully extrapolate its predictions to other semi-analytic models (GAEA, SC-SAM, and Shark) and, more remarkably, to hydrodynamical simulations (Astrid, SIMBA, IllustrisTNG, and SWIFT-EAGLE). Our results show that the network is robust to variations in astrophysical and subgrid physics, cosmological and astrophysical parameters, and the different halo-profile treatments used across simulations. This suggests that the physical relationships encoded in the phase-space of semi-analytic models are largely independent of their specific physical prescriptions, reinforcing their potential as tools for the generation of realistic mock catalogs for cosmological parameter inference.
The Denario project: Deep knowledge AI agents for scientific discovery
Oct 30, 2025We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud.
Open Source Planning & Control System with Language Agents for Autonomous Scientific Discovery
Jul 09, 2025We present a multi-agent system for automation of scientific research tasks, cmbagent. The system is formed by about 30 Large Language Model (LLM) agents and implements a Planning & Control strategy to orchestrate the agentic workflow, with no human-in-the-loop at any point. Each agent specializes in a different task (performing retrieval on scientific papers and codebases, writing code, interpreting results, critiquing the output of other agents) and the system is able to execute code locally. We successfully apply cmbagent to carry out a PhD level cosmology task (the measurement of cosmological parameters using supernova data) and evaluate its performance on two benchmark sets, finding superior performance over state-of-the-art LLMs. The source code is available on GitHub, demonstration videos are also available, and the system is deployed on HuggingFace and will be available on the cloud.
Evaluating Retrieval-Augmented Generation Agents for Autonomous Scientific Discovery in Astrophysics
Jul 09, 2025We evaluate 9 Retrieval Augmented Generation (RAG) agent configurations on 105 Cosmology Question-Answer (QA) pairs that we built specifically for this purpose.The RAG configurations are manually evaluated by a human expert, that is, a total of 945 generated answers were assessed. We find that currently the best RAG agent configuration is with OpenAI embedding and generative model, yielding 91.4\% accuracy. Using our human evaluation results we calibrate LLM-as-a-Judge (LLMaaJ) system which can be used as a robust proxy for human evaluation. These results allow us to systematically select the best RAG agent configuration for multi-agent system for autonomous scientific discovery in astrophysics (e.g., cmbagent presented in a companion paper) and provide us with an LLMaaJ system that can be scaled to thousands of cosmology QA pairs. We make our QA dataset, human evaluation results, RAG pipelines, and LLMaaJ system publicly available for further use by the astrophysics community.
How many simulations do we need for simulation-based inference in cosmology?
Mar 17, 2025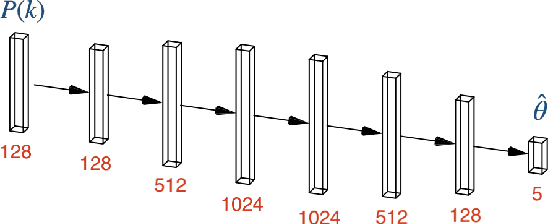
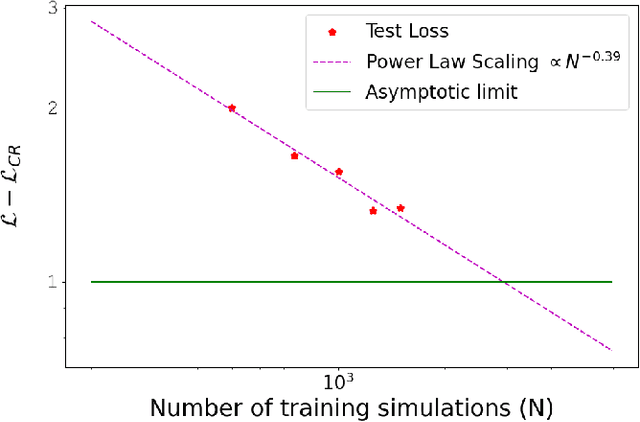
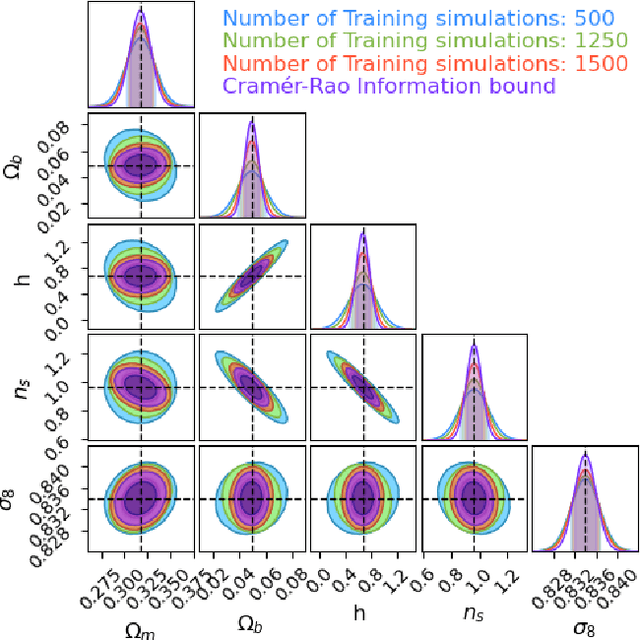
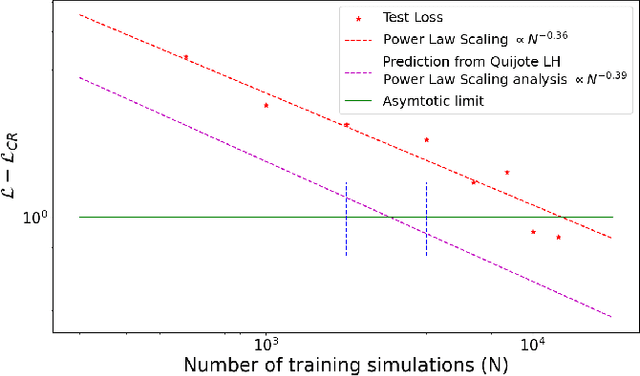
How many simulations do we need to train machine learning methods to extract information available from summary statistics of the cosmological density field? Neural methods have shown the potential to extract non-linear information available from cosmological data. Success depends critically on having sufficient simulations for training the networks and appropriate network architectures. In the first detailed convergence study of neural network training for cosmological inference, we show that currently available simulation suites, such as the Quijote Latin Hypercube(LH) with 2000 simulations, do not provide sufficient training data for a generic neural network to reach the optimal regime, even for the dark matter power spectrum, and in an idealized case. We discover an empirical neural scaling law that predicts how much information a neural network can extract from a highly informative summary statistic, the dark matter power spectrum, as a function of the number of simulations used to train the network, for a wide range of architectures and hyperparameters. We combine this result with the Cramer-Rao information bound to forecast the number of training simulations needed for near-optimal information extraction. To verify our method we created the largest publicly released simulation data set in cosmology, the Big Sobol Sequence(BSQ), consisting of 32,768 $\Lambda$CDM n-body simulations uniformly covering the $\Lambda$CDM parameter space. Our method enables efficient planning of simulation campaigns for machine learning applications in cosmology, while the BSQ dataset provides an unprecedented resource for studying the convergence behavior of neural networks in cosmological parameter inference. Our results suggest that new large simulation suites or new training approaches will be necessary to achieve information-optimal parameter inference from non-linear simulations.
CHARM: Creating Halos with Auto-Regressive Multi-stage networks
Sep 13, 2024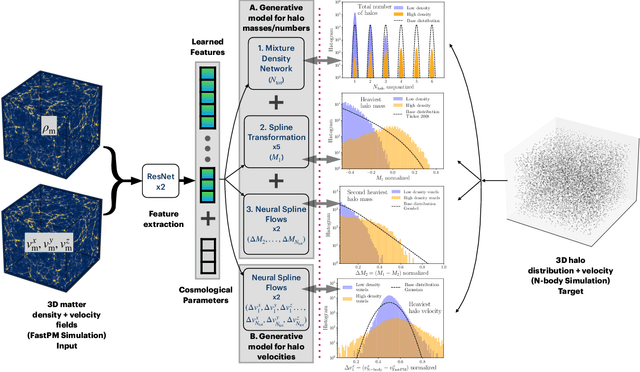
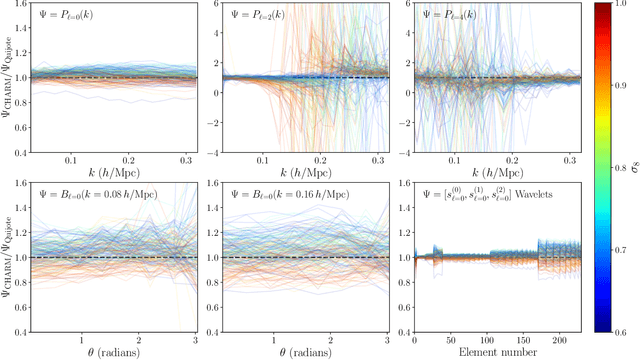
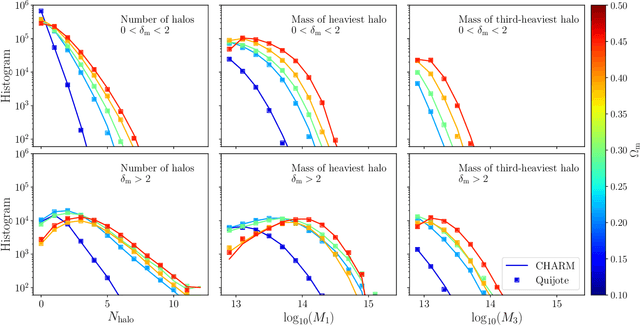
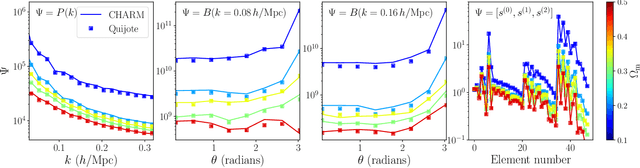
To maximize the amount of information extracted from cosmological datasets, simulations that accurately represent these observations are necessary. However, traditional simulations that evolve particles under gravity by estimating particle-particle interactions (N-body simulations) are computationally expensive and prohibitive to scale to the large volumes and resolutions necessary for the upcoming datasets. Moreover, modeling the distribution of galaxies typically involves identifying virialized dark matter halos, which is also a time- and memory-consuming process for large N-body simulations, further exacerbating the computational cost. In this study, we introduce CHARM, a novel method for creating mock halo catalogs by matching the spatial, mass, and velocity statistics of halos directly from the large-scale distribution of the dark matter density field. We develop multi-stage neural spline flow-based networks to learn this mapping at redshift z=0.5 directly with computationally cheaper low-resolution particle mesh simulations instead of relying on the high-resolution N-body simulations. We show that the mock halo catalogs and painted galaxy catalogs have the same statistical properties as obtained from $N$-body simulations in both real space and redshift space. Finally, we use these mock catalogs for cosmological inference using redshift-space galaxy power spectrum, bispectrum, and wavelet-based statistics using simulation-based inference, performing the first inference with accelerated forward model simulations and finding unbiased cosmological constraints with well-calibrated posteriors. The code was developed as part of the Simons Collaboration on Learning the Universe and is publicly available at \url{https://github.com/shivampcosmo/CHARM}.
How DREAMS are made: Emulating Satellite Galaxy and Subhalo Populations with Diffusion Models and Point Clouds
Sep 04, 2024



The connection between galaxies and their host dark matter (DM) halos is critical to our understanding of cosmology, galaxy formation, and DM physics. To maximize the return of upcoming cosmological surveys, we need an accurate way to model this complex relationship. Many techniques have been developed to model this connection, from Halo Occupation Distribution (HOD) to empirical and semi-analytic models to hydrodynamic. Hydrodynamic simulations can incorporate more detailed astrophysical processes but are computationally expensive; HODs, on the other hand, are computationally cheap but have limited accuracy. In this work, we present NeHOD, a generative framework based on variational diffusion model and Transformer, for painting galaxies/subhalos on top of DM with an accuracy of hydrodynamic simulations but at a computational cost similar to HOD. By modeling galaxies/subhalos as point clouds, instead of binning or voxelization, we can resolve small spatial scales down to the resolution of the simulations. For each halo, NeHOD predicts the positions, velocities, masses, and concentrations of its central and satellite galaxies. We train NeHOD on the TNG-Warm DM suite of the DREAMS project, which consists of 1024 high-resolution zoom-in hydrodynamic simulations of Milky Way-mass halos with varying warm DM mass and astrophysical parameters. We show that our model captures the complex relationships between subhalo properties as a function of the simulation parameters, including the mass functions, stellar-halo mass relations, concentration-mass relations, and spatial clustering. Our method can be used for a large variety of downstream applications, from galaxy clustering to strong lensing studies.
Domain Adaptive Graph Neural Networks for Constraining Cosmological Parameters Across Multiple Data Sets
Nov 02, 2023
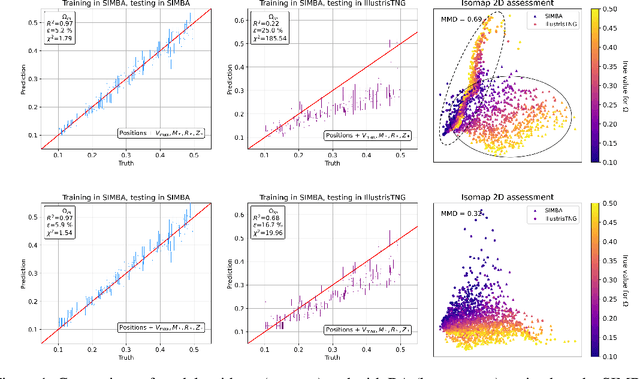
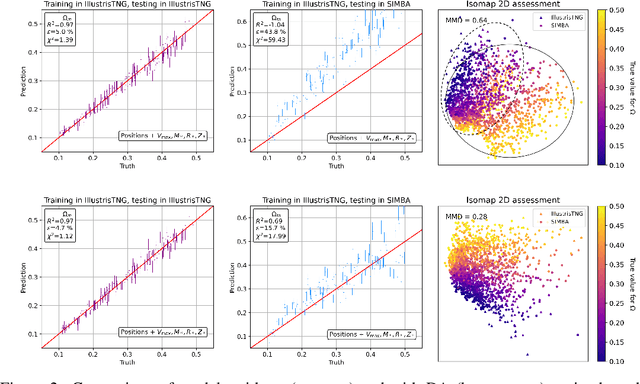
Deep learning models have been shown to outperform methods that rely on summary statistics, like the power spectrum, in extracting information from complex cosmological data sets. However, due to differences in the subgrid physics implementation and numerical approximations across different simulation suites, models trained on data from one cosmological simulation show a drop in performance when tested on another. Similarly, models trained on any of the simulations would also likely experience a drop in performance when applied to observational data. Training on data from two different suites of the CAMELS hydrodynamic cosmological simulations, we examine the generalization capabilities of Domain Adaptive Graph Neural Networks (DA-GNNs). By utilizing GNNs, we capitalize on their capacity to capture structured scale-free cosmological information from galaxy distributions. Moreover, by including unsupervised domain adaptation via Maximum Mean Discrepancy (MMD), we enable our models to extract domain-invariant features. We demonstrate that DA-GNN achieves higher accuracy and robustness on cross-dataset tasks (up to $28\%$ better relative error and up to almost an order of magnitude better $\chi^2$). Using data visualizations, we show the effects of domain adaptation on proper latent space data alignment. This shows that DA-GNNs are a promising method for extracting domain-independent cosmological information, a vital step toward robust deep learning for real cosmic survey data.
Field-level simulation-based inference with galaxy catalogs: the impact of systematic effects
Oct 23, 2023It has been recently shown that a powerful way to constrain cosmological parameters from galaxy redshift surveys is to train graph neural networks to perform field-level likelihood-free inference without imposing cuts on scale. In particular, de Santi et al. (2023) developed models that could accurately infer the value of $\Omega_{\rm m}$ from catalogs that only contain the positions and radial velocities of galaxies that are robust to uncertainties in astrophysics and subgrid models. However, observations are affected by many effects, including 1) masking, 2) uncertainties in peculiar velocities and radial distances, and 3) different galaxy selections. Moreover, observations only allow us to measure redshift, intertwining galaxies' radial positions and velocities. In this paper we train and test our models on galaxy catalogs, created from thousands of state-of-the-art hydrodynamic simulations run with different codes from the CAMELS project, that incorporate these observational effects. We find that, although the presence of these effects degrades the precision and accuracy of the models, and increases the fraction of catalogs where the model breaks down, the fraction of galaxy catalogs where the model performs well is over 90 %, demonstrating the potential of these models to constrain cosmological parameters even when applied to real data.