 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow many simulations do we need for simulation-based inference in cosmology?
Mar 17, 2025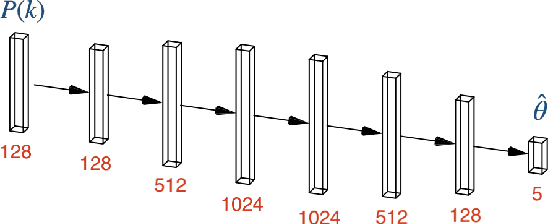
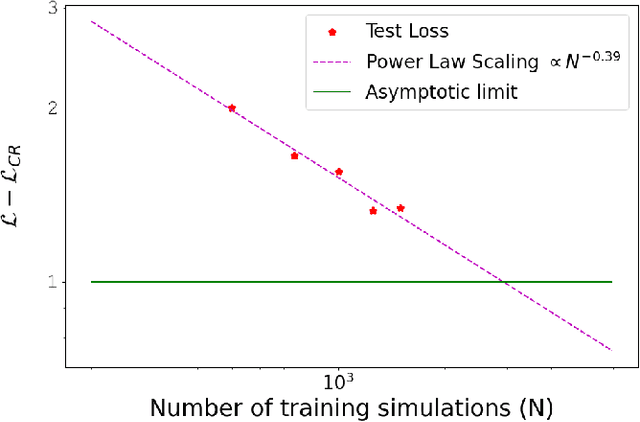
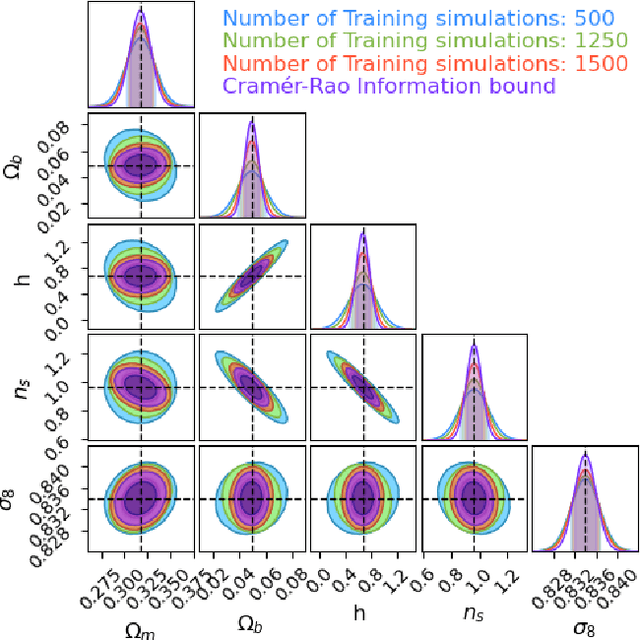
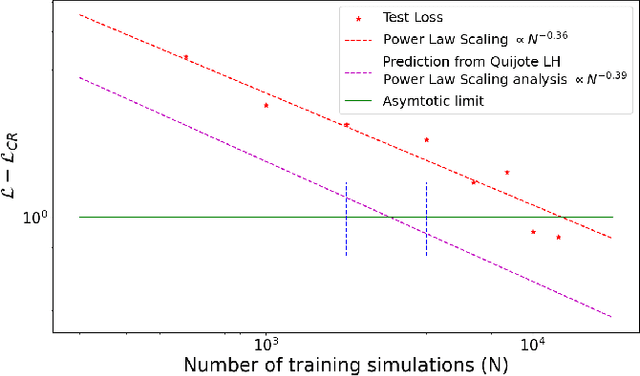
How many simulations do we need to train machine learning methods to extract information available from summary statistics of the cosmological density field? Neural methods have shown the potential to extract non-linear information available from cosmological data. Success depends critically on having sufficient simulations for training the networks and appropriate network architectures. In the first detailed convergence study of neural network training for cosmological inference, we show that currently available simulation suites, such as the Quijote Latin Hypercube(LH) with 2000 simulations, do not provide sufficient training data for a generic neural network to reach the optimal regime, even for the dark matter power spectrum, and in an idealized case. We discover an empirical neural scaling law that predicts how much information a neural network can extract from a highly informative summary statistic, the dark matter power spectrum, as a function of the number of simulations used to train the network, for a wide range of architectures and hyperparameters. We combine this result with the Cramer-Rao information bound to forecast the number of training simulations needed for near-optimal information extraction. To verify our method we created the largest publicly released simulation data set in cosmology, the Big Sobol Sequence(BSQ), consisting of 32,768 $\Lambda$CDM n-body simulations uniformly covering the $\Lambda$CDM parameter space. Our method enables efficient planning of simulation campaigns for machine learning applications in cosmology, while the BSQ dataset provides an unprecedented resource for studying the convergence behavior of neural networks in cosmological parameter inference. Our results suggest that new large simulation suites or new training approaches will be necessary to achieve information-optimal parameter inference from non-linear simulations.
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
Feb 06, 2024



This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schema, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable, designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterising progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
Optimal simulation-based Bayesian decisions
Nov 09, 2023We present a framework for the efficient computation of optimal Bayesian decisions under intractable likelihoods, by learning a surrogate model for the expected utility (or its distribution) as a function of the action and data spaces. We leverage recent advances in simulation-based inference and Bayesian optimization to develop active learning schemes to choose where in parameter and action spaces to simulate. This allows us to learn the optimal action in as few simulations as possible. The resulting framework is extremely simulation efficient, typically requiring fewer model calls than the associated posterior inference task alone, and a factor of $100-1000$ more efficient than Monte-Carlo based methods. Our framework opens up new capabilities for performing Bayesian decision making, particularly in the previously challenging regime where likelihoods are intractable, and simulations expensive.
Information-Ordered Bottlenecks for Adaptive Semantic Compression
May 18, 2023We present the information-ordered bottleneck (IOB), a neural layer designed to adaptively compress data into latent variables ordered by likelihood maximization. Without retraining, IOB nodes can be truncated at any bottleneck width, capturing the most crucial information in the first latent variables. Unifying several previous approaches, we show that IOBs achieve near-optimal compression for a given encoding architecture and can assign ordering to latent signals in a manner that is semantically meaningful. IOBs demonstrate a remarkable ability to compress embeddings of image and text data, leveraging the performance of SOTA architectures such as CNNs, transformers, and diffusion models. Moreover, we introduce a novel theory for estimating global intrinsic dimensionality with IOBs and show that they recover SOTA dimensionality estimates for complex synthetic data. Furthermore, we showcase the utility of these models for exploratory analysis through applications on heterogeneous datasets, enabling computer-aided discovery of dataset complexity.
The CAMELS project: public data release
Jan 04, 2022
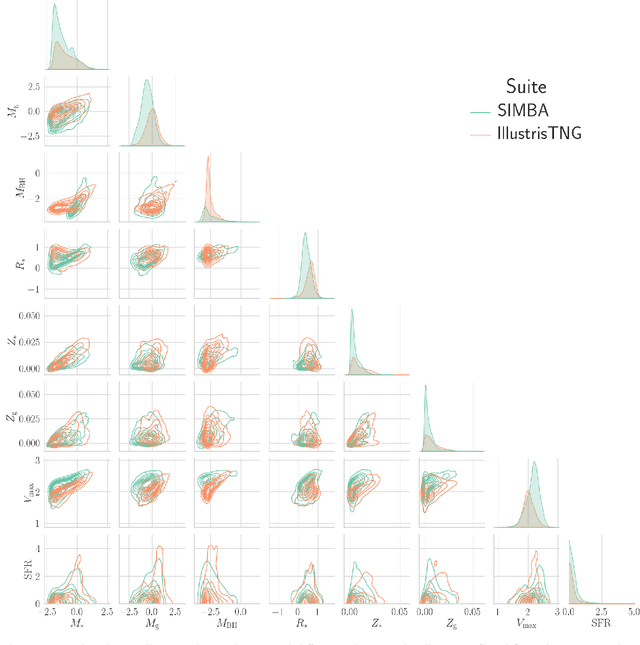
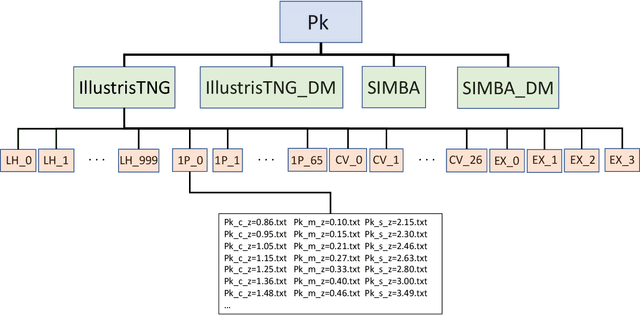
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021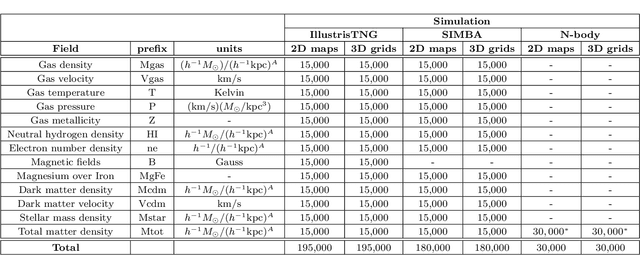

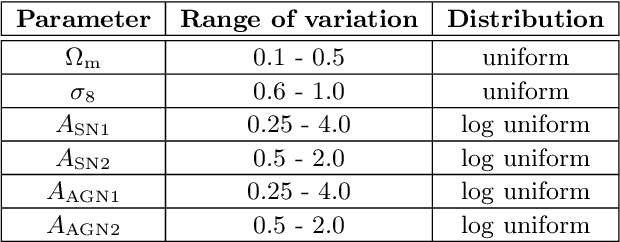
We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.
Robust marginalization of baryonic effects for cosmological inference at the field level
Sep 21, 2021
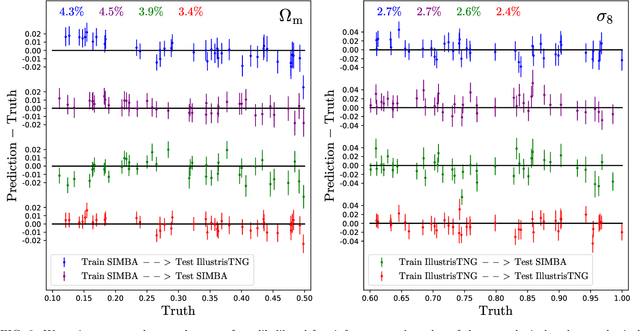
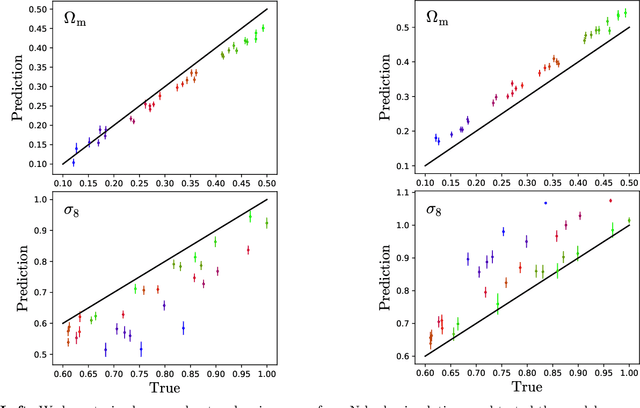
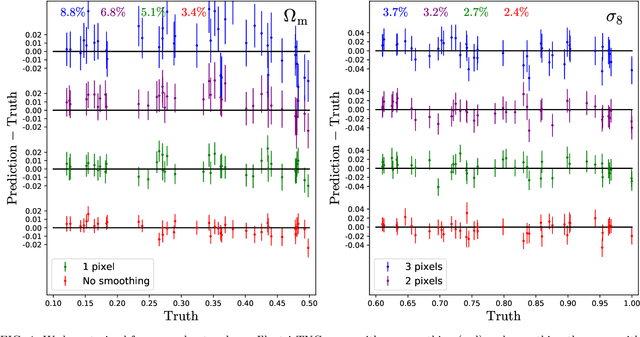
We train neural networks to perform likelihood-free inference from $(25\,h^{-1}{\rm Mpc})^2$ 2D maps containing the total mass surface density from thousands of hydrodynamic simulations of the CAMELS project. We show that the networks can extract information beyond one-point functions and power spectra from all resolved scales ($\gtrsim 100\,h^{-1}{\rm kpc}$) while performing a robust marginalization over baryonic physics at the field level: the model can infer the value of $\Omega_{\rm m} (\pm 4\%)$ and $\sigma_8 (\pm 2.5\%)$ from simulations completely different to the ones used to train it.
Multifield Cosmology with Artificial Intelligence
Sep 20, 2021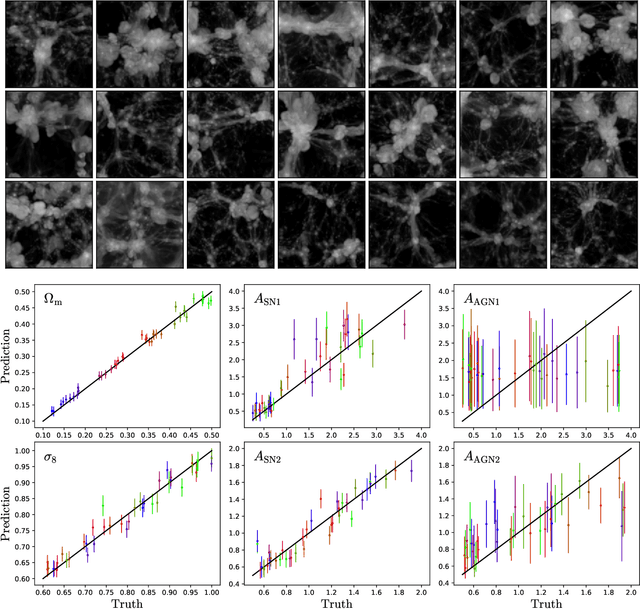
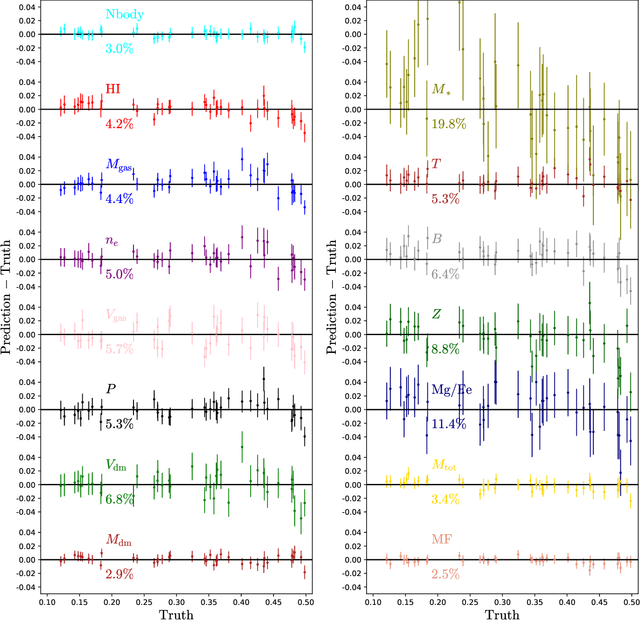
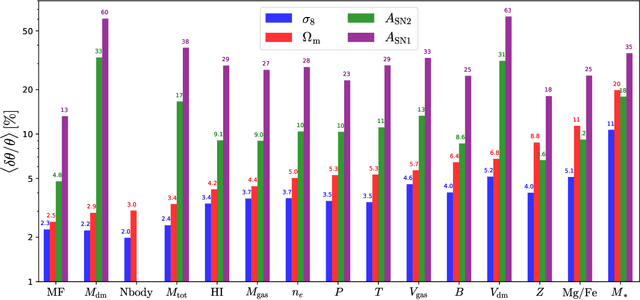
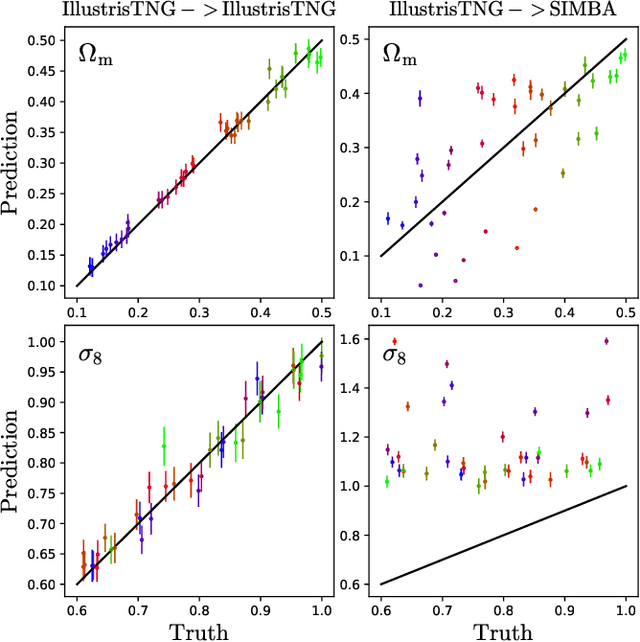
Astrophysical processes such as feedback from supernovae and active galactic nuclei modify the properties and spatial distribution of dark matter, gas, and galaxies in a poorly understood way. This uncertainty is one of the main theoretical obstacles to extract information from cosmological surveys. We use 2,000 state-of-the-art hydrodynamic simulations from the CAMELS project spanning a wide variety of cosmological and astrophysical models and generate hundreds of thousands of 2-dimensional maps for 13 different fields: from dark matter to gas and stellar properties. We use these maps to train convolutional neural networks to extract the maximum amount of cosmological information while marginalizing over astrophysical effects at the field level. Although our maps only cover a small area of $(25~h^{-1}{\rm Mpc})^2$, and the different fields are contaminated by astrophysical effects in very different ways, our networks can infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a few percent level precision for most of the fields. We find that the marginalization performed by the network retains a wealth of cosmological information compared to a model trained on maps from gravity-only N-body simulations that are not contaminated by astrophysical effects. Finally, we train our networks on multifields -- 2D maps that contain several fields as different colors or channels -- and find that not only they can infer the value of all parameters with higher accuracy than networks trained on individual fields, but they can constrain the value of $\Omega_{\rm m}$ with higher accuracy than the maps from the N-body simulations.
Fast likelihood-free cosmology with neural density estimators and active learning
Feb 28, 2019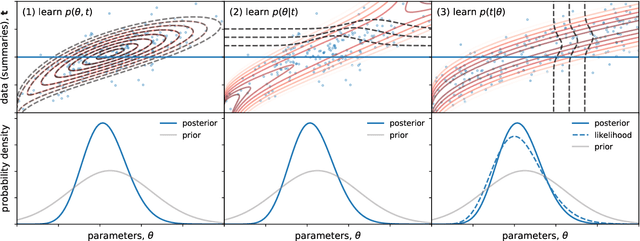
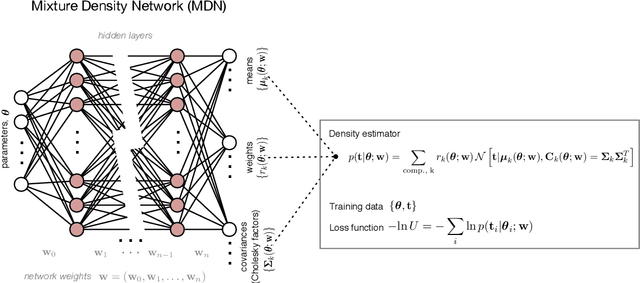
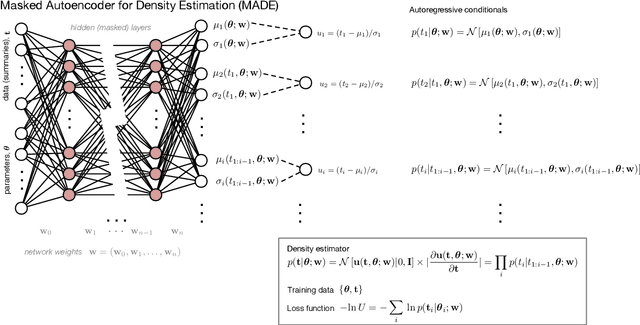
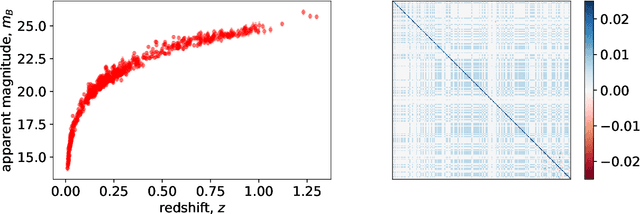
Likelihood-free inference provides a framework for performing rigorous Bayesian inference using only forward simulations, properly accounting for all physical and observational effects that can be successfully included in the simulations. The key challenge for likelihood-free applications in cosmology, where simulation is typically expensive, is developing methods that can achieve high-fidelity posterior inference with as few simulations as possible. Density-estimation likelihood-free inference (DELFI) methods turn inference into a density estimation task on a set of simulated data-parameter pairs, and give orders of magnitude improvements over traditional Approximate Bayesian Computation approaches to likelihood-free inference. In this paper we use neural density estimators (NDEs) to learn the likelihood function from a set of simulated datasets, with active learning to adaptively acquire simulations in the most relevant regions of parameter space on-the-fly. We demonstrate the approach on a number of cosmological case studies, showing that for typical problems high-fidelity posterior inference can be achieved with just $\mathcal{O}(10^3)$ simulations or fewer. In addition to enabling efficient simulation-based inference, for simple problems where the form of the likelihood is known, DELFI offers a fast alternative to MCMC sampling, giving orders of magnitude speed-up in some cases. Finally, we introduce \textsc{pydelfi} -- a flexible public implementation of DELFI with NDEs and active learning -- available at \url{https://github.com/justinalsing/pydelfi}.