 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeField-level simulation-based inference with galaxy catalogs: the impact of systematic effects
Oct 23, 2023It has been recently shown that a powerful way to constrain cosmological parameters from galaxy redshift surveys is to train graph neural networks to perform field-level likelihood-free inference without imposing cuts on scale. In particular, de Santi et al. (2023) developed models that could accurately infer the value of $\Omega_{\rm m}$ from catalogs that only contain the positions and radial velocities of galaxies that are robust to uncertainties in astrophysics and subgrid models. However, observations are affected by many effects, including 1) masking, 2) uncertainties in peculiar velocities and radial distances, and 3) different galaxy selections. Moreover, observations only allow us to measure redshift, intertwining galaxies' radial positions and velocities. In this paper we train and test our models on galaxy catalogs, created from thousands of state-of-the-art hydrodynamic simulations run with different codes from the CAMELS project, that incorporate these observational effects. We find that, although the presence of these effects degrades the precision and accuracy of the models, and increases the fraction of catalogs where the model breaks down, the fraction of galaxy catalogs where the model performs well is over 90 %, demonstrating the potential of these models to constrain cosmological parameters even when applied to real data.
The CAMELS project: Expanding the galaxy formation model space with new ASTRID and 28-parameter TNG and SIMBA suites
Apr 04, 2023We present CAMELS-ASTRID, the third suite of hydrodynamical simulations in the Cosmology and Astrophysics with MachinE Learning (CAMELS) project, along with new simulation sets that extend the model parameter space based on the previous frameworks of CAMELS-TNG and CAMELS-SIMBA, to provide broader training sets and testing grounds for machine-learning algorithms designed for cosmological studies. CAMELS-ASTRID employs the galaxy formation model following the ASTRID simulation and contains 2,124 hydrodynamic simulation runs that vary 3 cosmological parameters ($\Omega_m$, $\sigma_8$, $\Omega_b$) and 4 parameters controlling stellar and AGN feedback. Compared to the existing TNG and SIMBA simulation suites in CAMELS, the fiducial model of ASTRID features the mildest AGN feedback and predicts the least baryonic effect on the matter power spectrum. The training set of ASTRID covers a broader variation in the galaxy populations and the baryonic impact on the matter power spectrum compared to its TNG and SIMBA counterparts, which can make machine-learning models trained on the ASTRID suite exhibit better extrapolation performance when tested on other hydrodynamic simulation sets. We also introduce extension simulation sets in CAMELS that widely explore 28 parameters in the TNG and SIMBA models, demonstrating the enormity of the overall galaxy formation model parameter space and the complex non-linear interplay between cosmology and astrophysical processes. With the new simulation suites, we show that building robust machine-learning models favors training and testing on the largest possible diversity of galaxy formation models. We also demonstrate that it is possible to train accurate neural networks to infer cosmological parameters using the high-dimensional TNG-SB28 simulation set.
Robust field-level likelihood-free inference with galaxies
Feb 27, 2023We train graph neural networks to perform field-level likelihood-free inference using galaxy catalogs from state-of-the-art hydrodynamic simulations of the CAMELS project. Our models are rotationally, translationally, and permutation invariant and have no scale cutoff. By training on galaxy catalogs that only contain the 3D positions and radial velocities of approximately $1,000$ galaxies in tiny volumes of $(25~h^{-1}{\rm Mpc})^3$, our models achieve a precision of approximately $12$% when inferring the value of $\Omega_{\rm m}$. To test the robustness of our models, we evaluated their performance on galaxy catalogs from thousands of hydrodynamic simulations, each with different efficiencies of supernova and AGN feedback, run with five different codes and subgrid models, including IllustrisTNG, SIMBA, Astrid, Magneticum, and SWIFT-EAGLE. Our results demonstrate that our models are robust to astrophysics, subgrid physics, and subhalo/galaxy finder changes. Furthermore, we test our models on 1,024 simulations that cover a vast region in parameter space - variations in 5 cosmological and 23 astrophysical parameters - finding that the model extrapolates really well. Including both positions and velocities are key to building robust models, and our results indicate that our networks have likely learned an underlying physical relation that does not depend on galaxy formation and is valid on scales larger than, at least, $~\sim10~h^{-1}{\rm kpc}$.
Robust field-level inference with dark matter halos
Sep 14, 2022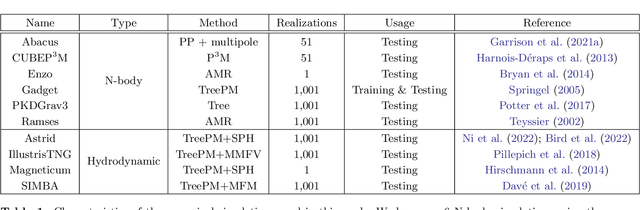
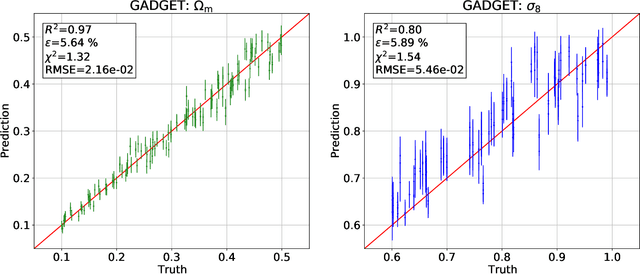
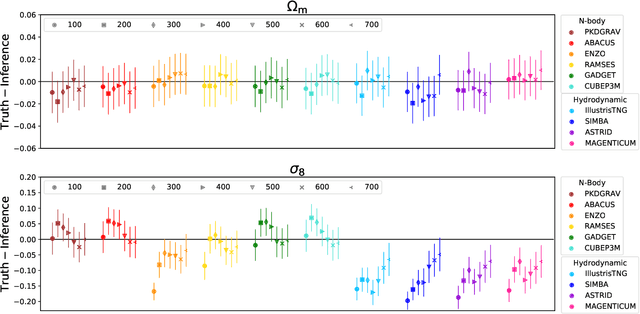

We train graph neural networks on halo catalogues from Gadget N-body simulations to perform field-level likelihood-free inference of cosmological parameters. The catalogues contain $\lesssim$5,000 halos with masses $\gtrsim 10^{10}~h^{-1}M_\odot$ in a periodic volume of $(25~h^{-1}{\rm Mpc})^3$; every halo in the catalogue is characterized by several properties such as position, mass, velocity, concentration, and maximum circular velocity. Our models, built to be permutationally, translationally, and rotationally invariant, do not impose a minimum scale on which to extract information and are able to infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a mean relative error of $\sim6\%$, when using positions plus velocities and positions plus masses, respectively. More importantly, we find that our models are very robust: they can infer the value of $\Omega_{\rm m}$ and $\sigma_8$ when tested using halo catalogues from thousands of N-body simulations run with five different N-body codes: Abacus, CUBEP$^3$M, Enzo, PKDGrav3, and Ramses. Surprisingly, the model trained to infer $\Omega_{\rm m}$ also works when tested on thousands of state-of-the-art CAMELS hydrodynamic simulations run with four different codes and subgrid physics implementations. Using halo properties such as concentration and maximum circular velocity allow our models to extract more information, at the expense of breaking the robustness of the models. This may happen because the different N-body codes are not converged on the relevant scales corresponding to these parameters.
The CAMELS project: public data release
Jan 04, 2022
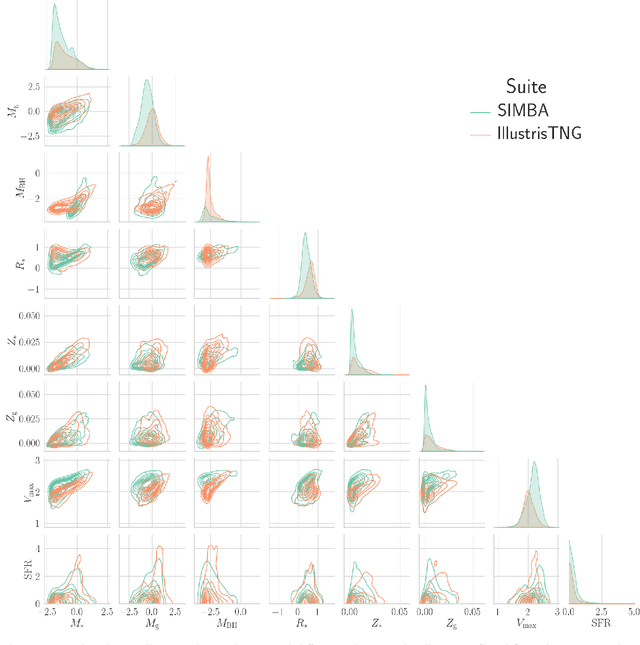
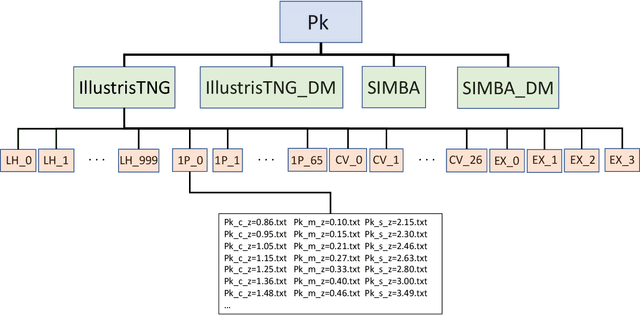
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021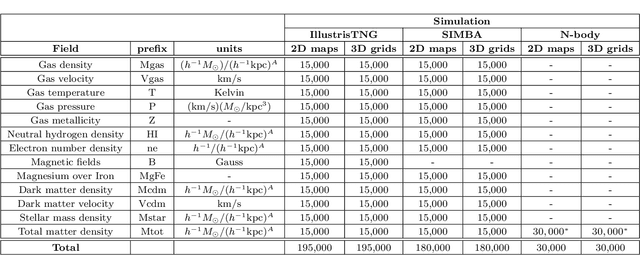

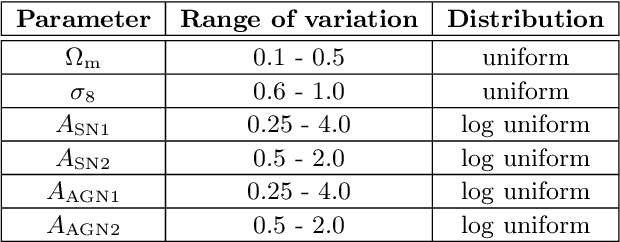
We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.
Robust marginalization of baryonic effects for cosmological inference at the field level
Sep 21, 2021
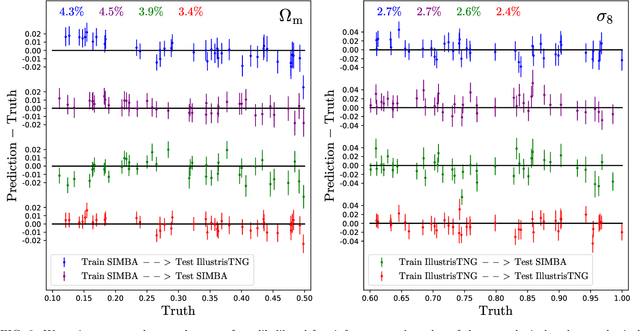
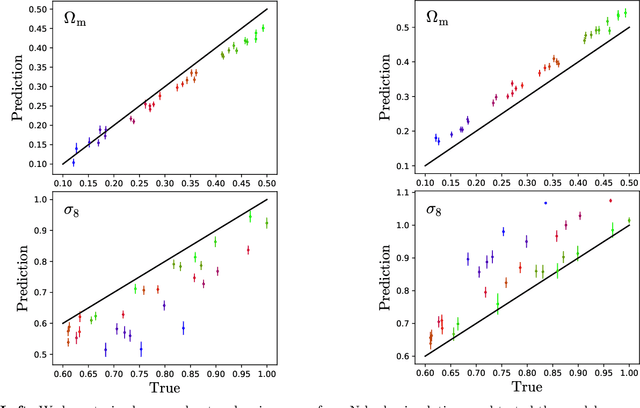
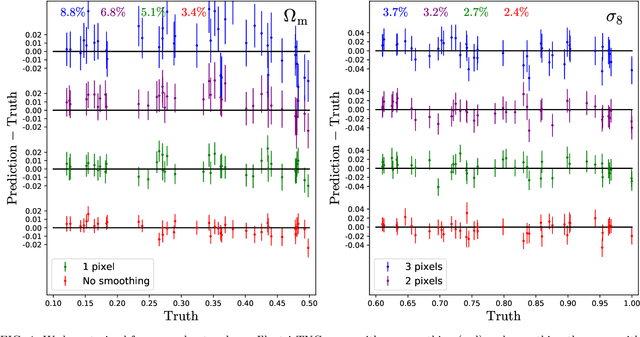
We train neural networks to perform likelihood-free inference from $(25\,h^{-1}{\rm Mpc})^2$ 2D maps containing the total mass surface density from thousands of hydrodynamic simulations of the CAMELS project. We show that the networks can extract information beyond one-point functions and power spectra from all resolved scales ($\gtrsim 100\,h^{-1}{\rm kpc}$) while performing a robust marginalization over baryonic physics at the field level: the model can infer the value of $\Omega_{\rm m} (\pm 4\%)$ and $\sigma_8 (\pm 2.5\%)$ from simulations completely different to the ones used to train it.