 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust field-level likelihood-free inference with galaxies
Feb 27, 2023We train graph neural networks to perform field-level likelihood-free inference using galaxy catalogs from state-of-the-art hydrodynamic simulations of the CAMELS project. Our models are rotationally, translationally, and permutation invariant and have no scale cutoff. By training on galaxy catalogs that only contain the 3D positions and radial velocities of approximately $1,000$ galaxies in tiny volumes of $(25~h^{-1}{\rm Mpc})^3$, our models achieve a precision of approximately $12$% when inferring the value of $\Omega_{\rm m}$. To test the robustness of our models, we evaluated their performance on galaxy catalogs from thousands of hydrodynamic simulations, each with different efficiencies of supernova and AGN feedback, run with five different codes and subgrid models, including IllustrisTNG, SIMBA, Astrid, Magneticum, and SWIFT-EAGLE. Our results demonstrate that our models are robust to astrophysics, subgrid physics, and subhalo/galaxy finder changes. Furthermore, we test our models on 1,024 simulations that cover a vast region in parameter space - variations in 5 cosmological and 23 astrophysical parameters - finding that the model extrapolates really well. Including both positions and velocities are key to building robust models, and our results indicate that our networks have likely learned an underlying physical relation that does not depend on galaxy formation and is valid on scales larger than, at least, $~\sim10~h^{-1}{\rm kpc}$.
Robust field-level inference with dark matter halos
Sep 14, 2022
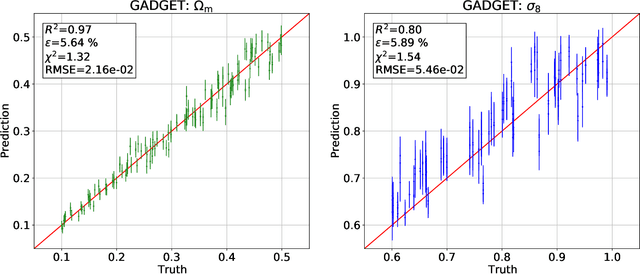
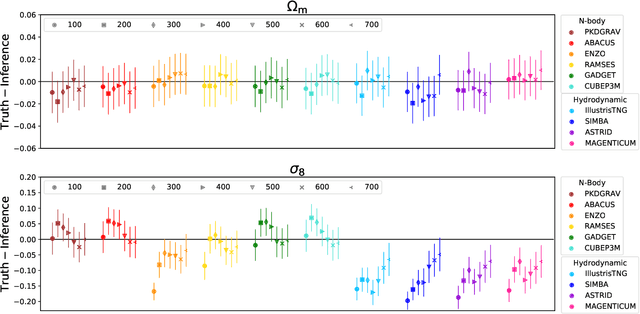

We train graph neural networks on halo catalogues from Gadget N-body simulations to perform field-level likelihood-free inference of cosmological parameters. The catalogues contain $\lesssim$5,000 halos with masses $\gtrsim 10^{10}~h^{-1}M_\odot$ in a periodic volume of $(25~h^{-1}{\rm Mpc})^3$; every halo in the catalogue is characterized by several properties such as position, mass, velocity, concentration, and maximum circular velocity. Our models, built to be permutationally, translationally, and rotationally invariant, do not impose a minimum scale on which to extract information and are able to infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a mean relative error of $\sim6\%$, when using positions plus velocities and positions plus masses, respectively. More importantly, we find that our models are very robust: they can infer the value of $\Omega_{\rm m}$ and $\sigma_8$ when tested using halo catalogues from thousands of N-body simulations run with five different N-body codes: Abacus, CUBEP$^3$M, Enzo, PKDGrav3, and Ramses. Surprisingly, the model trained to infer $\Omega_{\rm m}$ also works when tested on thousands of state-of-the-art CAMELS hydrodynamic simulations run with four different codes and subgrid physics implementations. Using halo properties such as concentration and maximum circular velocity allow our models to extract more information, at the expense of breaking the robustness of the models. This may happen because the different N-body codes are not converged on the relevant scales corresponding to these parameters.