 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CAMELS project: Expanding the galaxy formation model space with new ASTRID and 28-parameter TNG and SIMBA suites
Apr 04, 2023We present CAMELS-ASTRID, the third suite of hydrodynamical simulations in the Cosmology and Astrophysics with MachinE Learning (CAMELS) project, along with new simulation sets that extend the model parameter space based on the previous frameworks of CAMELS-TNG and CAMELS-SIMBA, to provide broader training sets and testing grounds for machine-learning algorithms designed for cosmological studies. CAMELS-ASTRID employs the galaxy formation model following the ASTRID simulation and contains 2,124 hydrodynamic simulation runs that vary 3 cosmological parameters ($\Omega_m$, $\sigma_8$, $\Omega_b$) and 4 parameters controlling stellar and AGN feedback. Compared to the existing TNG and SIMBA simulation suites in CAMELS, the fiducial model of ASTRID features the mildest AGN feedback and predicts the least baryonic effect on the matter power spectrum. The training set of ASTRID covers a broader variation in the galaxy populations and the baryonic impact on the matter power spectrum compared to its TNG and SIMBA counterparts, which can make machine-learning models trained on the ASTRID suite exhibit better extrapolation performance when tested on other hydrodynamic simulation sets. We also introduce extension simulation sets in CAMELS that widely explore 28 parameters in the TNG and SIMBA models, demonstrating the enormity of the overall galaxy formation model parameter space and the complex non-linear interplay between cosmology and astrophysical processes. With the new simulation suites, we show that building robust machine-learning models favors training and testing on the largest possible diversity of galaxy formation models. We also demonstrate that it is possible to train accurate neural networks to infer cosmological parameters using the high-dimensional TNG-SB28 simulation set.
Robust field-level likelihood-free inference with galaxies
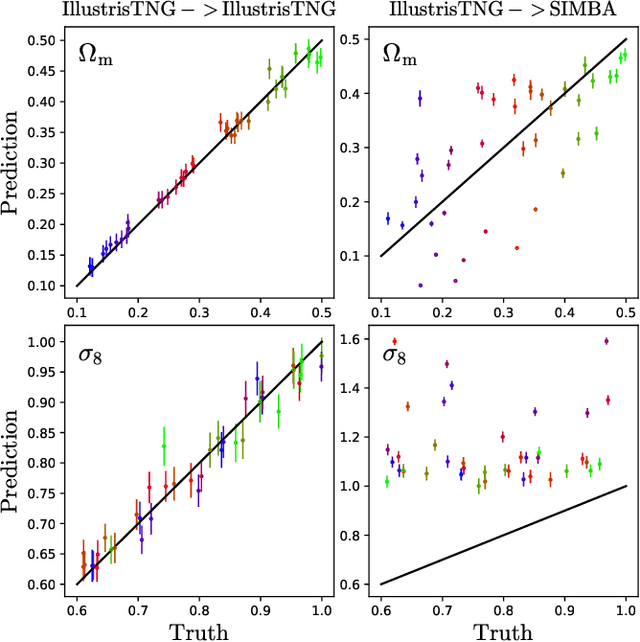
Feb 27, 2023We train graph neural networks to perform field-level likelihood-free inference using galaxy catalogs from state-of-the-art hydrodynamic simulations of the CAMELS project. Our models are rotationally, translationally, and permutation invariant and have no scale cutoff. By training on galaxy catalogs that only contain the 3D positions and radial velocities of approximately $1,000$ galaxies in tiny volumes of $(25~h^{-1}{\rm Mpc})^3$, our models achieve a precision of approximately $12$% when inferring the value of $\Omega_{\rm m}$. To test the robustness of our models, we evaluated their performance on galaxy catalogs from thousands of hydrodynamic simulations, each with different efficiencies of supernova and AGN feedback, run with five different codes and subgrid models, including IllustrisTNG, SIMBA, Astrid, Magneticum, and SWIFT-EAGLE. Our results demonstrate that our models are robust to astrophysics, subgrid physics, and subhalo/galaxy finder changes. Furthermore, we test our models on 1,024 simulations that cover a vast region in parameter space - variations in 5 cosmological and 23 astrophysical parameters - finding that the model extrapolates really well. Including both positions and velocities are key to building robust models, and our results indicate that our networks have likely learned an underlying physical relation that does not depend on galaxy formation and is valid on scales larger than, at least, $~\sim10~h^{-1}{\rm kpc}$.
The CAMELS project: public data release
Jan 04, 2022
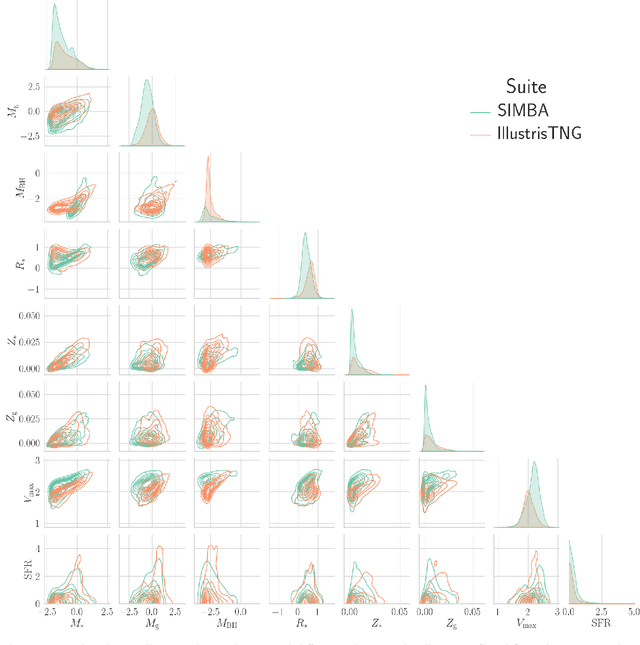
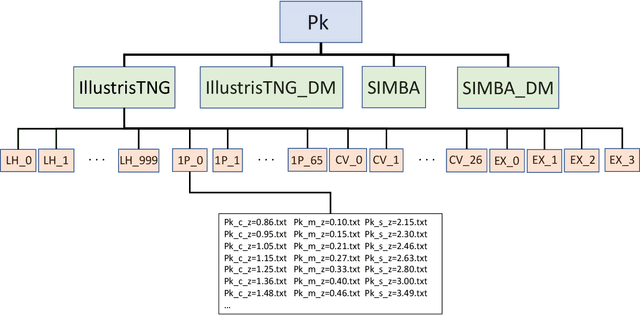
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
Weighing the Milky Way and Andromeda with Artificial Intelligence
Nov 29, 2021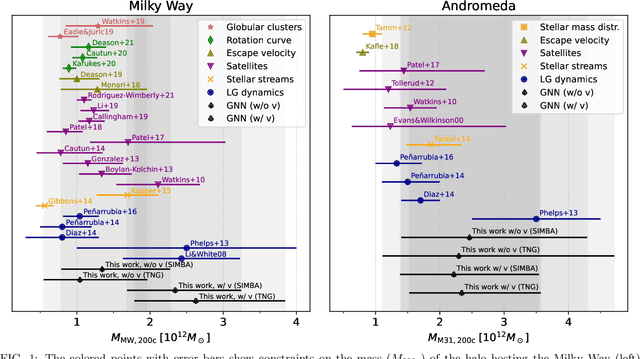
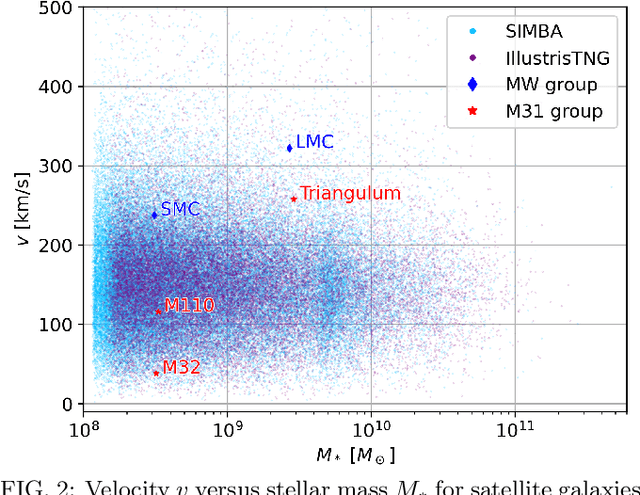


We present new constraints on the masses of the halos hosting the Milky Way and Andromeda galaxies derived using graph neural networks. Our models, trained on thousands of state-of-the-art hydrodynamic simulations of the CAMELS project, only make use of the positions, velocities and stellar masses of the galaxies belonging to the halos, and are able to perform likelihood-free inference on halo masses while accounting for both cosmological and astrophysical uncertainties. Our constraints are in agreement with estimates from other traditional methods.
Inferring halo masses with Graph Neural Networks
Nov 16, 2021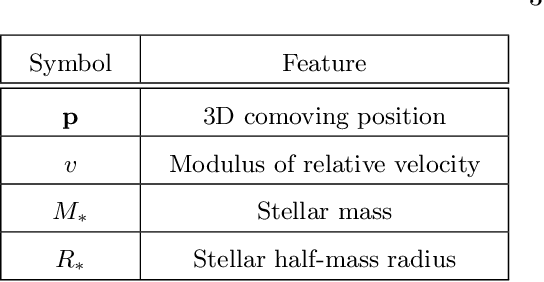
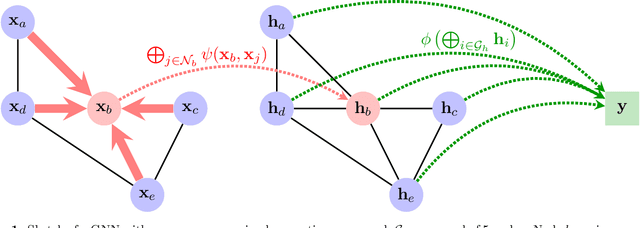
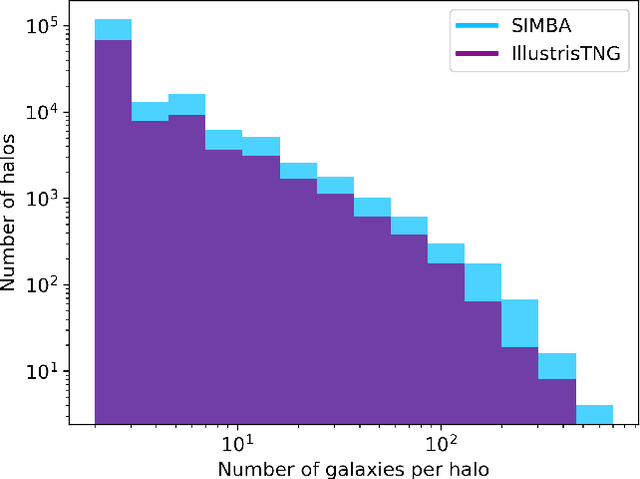
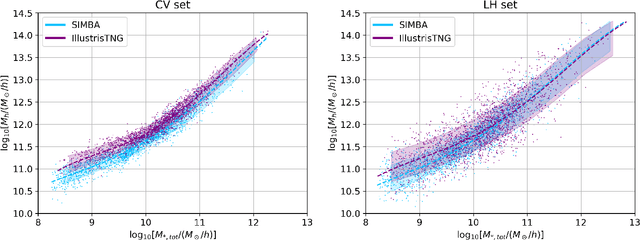
Understanding the halo-galaxy connection is fundamental in order to improve our knowledge on the nature and properties of dark matter. In this work we build a model that infers the mass of a halo given the positions, velocities, stellar masses, and radii of the galaxies it hosts. In order to capture information from correlations among galaxy properties and their phase-space, we use Graph Neural Networks (GNNs), that are designed to work with irregular and sparse data. We train our models on galaxies from more than 2,000 state-of-the-art simulations from the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project. Our model, that accounts for cosmological and astrophysical uncertainties, is able to constrain the masses of the halos with a $\sim$0.2 dex accuracy. Furthermore, a GNN trained on a suite of simulations is able to preserve part of its accuracy when tested on simulations run with a different code that utilizes a distinct subgrid physics model, showing the robustness of our method. The PyTorch Geometric implementation of the GNN is publicly available on Github at https://github.com/PabloVD/HaloGraphNet
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021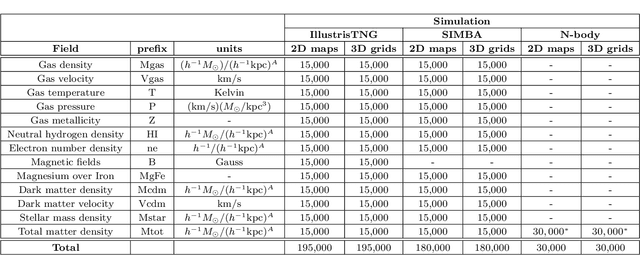

We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.
Robust marginalization of baryonic effects for cosmological inference at the field level
Sep 21, 2021
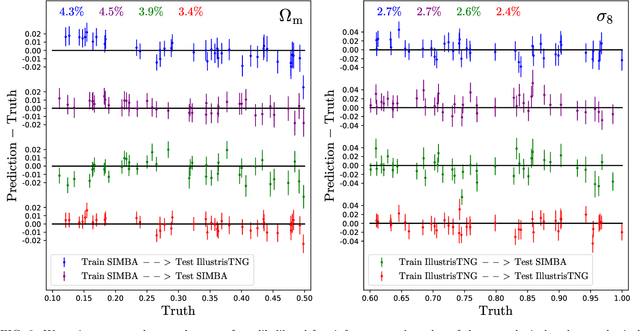
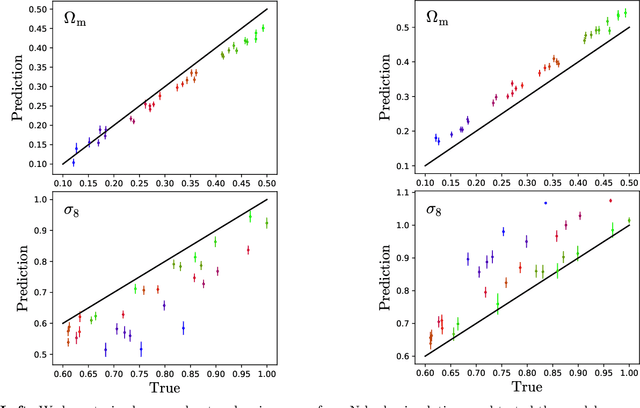
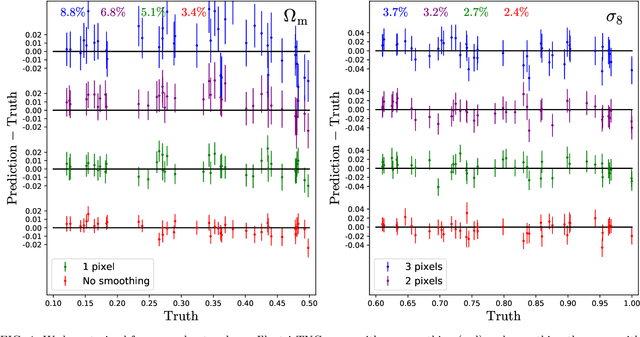
We train neural networks to perform likelihood-free inference from $(25\,h^{-1}{\rm Mpc})^2$ 2D maps containing the total mass surface density from thousands of hydrodynamic simulations of the CAMELS project. We show that the networks can extract information beyond one-point functions and power spectra from all resolved scales ($\gtrsim 100\,h^{-1}{\rm kpc}$) while performing a robust marginalization over baryonic physics at the field level: the model can infer the value of $\Omega_{\rm m} (\pm 4\%)$ and $\sigma_8 (\pm 2.5\%)$ from simulations completely different to the ones used to train it.
Multifield Cosmology with Artificial Intelligence
Sep 20, 2021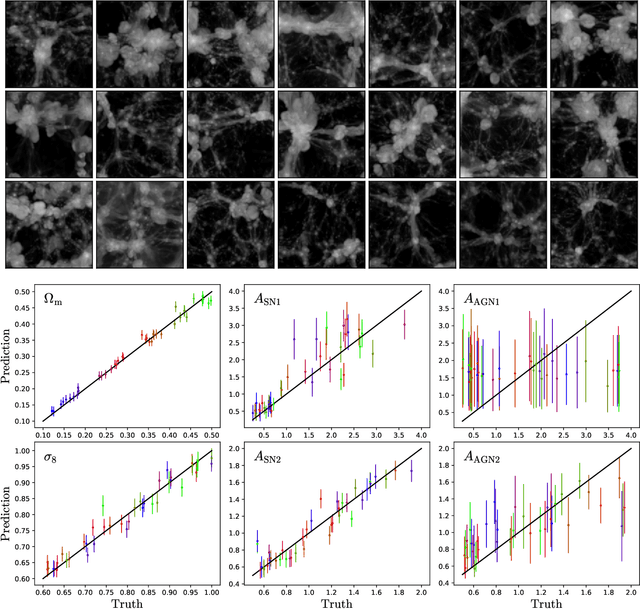
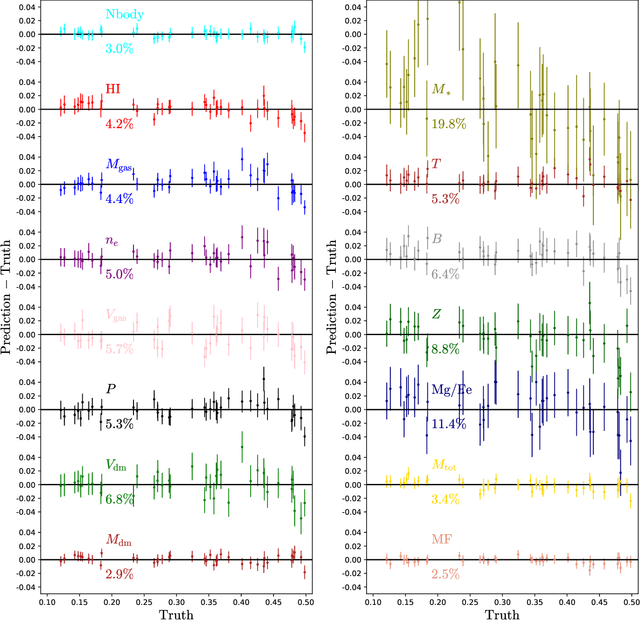
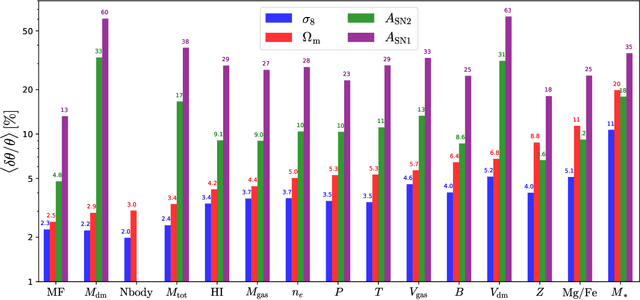
Astrophysical processes such as feedback from supernovae and active galactic nuclei modify the properties and spatial distribution of dark matter, gas, and galaxies in a poorly understood way. This uncertainty is one of the main theoretical obstacles to extract information from cosmological surveys. We use 2,000 state-of-the-art hydrodynamic simulations from the CAMELS project spanning a wide variety of cosmological and astrophysical models and generate hundreds of thousands of 2-dimensional maps for 13 different fields: from dark matter to gas and stellar properties. We use these maps to train convolutional neural networks to extract the maximum amount of cosmological information while marginalizing over astrophysical effects at the field level. Although our maps only cover a small area of $(25~h^{-1}{\rm Mpc})^2$, and the different fields are contaminated by astrophysical effects in very different ways, our networks can infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a few percent level precision for most of the fields. We find that the marginalization performed by the network retains a wealth of cosmological information compared to a model trained on maps from gravity-only N-body simulations that are not contaminated by astrophysical effects. Finally, we train our networks on multifields -- 2D maps that contain several fields as different colors or channels -- and find that not only they can infer the value of all parameters with higher accuracy than networks trained on individual fields, but they can constrain the value of $\Omega_{\rm m}$ with higher accuracy than the maps from the N-body simulations.
From Dark Matter to Galaxies with Convolutional Neural Networks
Oct 17, 2019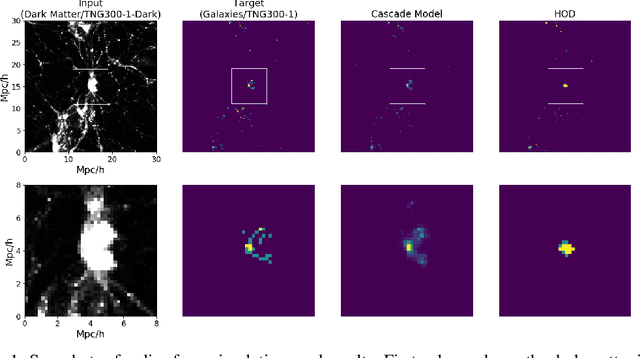
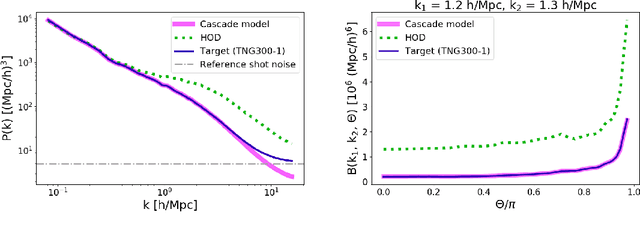
Cosmological simulations play an important role in the interpretation of astronomical data, in particular in comparing observed data to our theoretical expectations. However, to compare data with these simulations, the simulations in principle need to include gravity, magneto-hydrodyanmics, radiative transfer, etc. These ideal large-volume simulations (gravo-magneto-hydrodynamical) are incredibly computationally expensive which can cost tens of millions of CPU hours to run. In this paper, we propose a deep learning approach to map from the dark-matter-only simulation (computationally cheaper) to the galaxy distribution (from the much costlier cosmological simulation). The main challenge of this task is the high sparsity in the target galaxy distribution: space is mainly empty. We propose a cascade architecture composed of a classification filter followed by a regression procedure. We show that our result outperforms a state-of-the-art model used in the astronomical community, and provides a good trade-off between computational cost and prediction accuracy.