 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotary Masked Autoencoders are Versatile Learners
May 26, 2025Applying Transformers to irregular time-series typically requires specializations to their baseline architecture, which can result in additional computational overhead and increased method complexity. We present the Rotary Masked Autoencoder (RoMAE), which utilizes the popular Rotary Positional Embedding (RoPE) method for continuous positions. RoMAE is an extension to the Masked Autoencoder (MAE) that enables representation learning with multidimensional continuous positional information while avoiding any time-series-specific architectural specializations. We showcase RoMAE's performance on a variety of modalities including irregular and multivariate time-series, images, and audio, demonstrating that RoMAE surpasses specialized time-series architectures on difficult datasets such as the DESC ELAsTiCC Challenge while maintaining MAE's usual performance across other modalities. In addition, we investigate RoMAE's ability to reconstruct the embedded continuous positions, demonstrating that including learned embeddings in the input sequence breaks RoPE's relative position property.
Detecting Localized Density Anomalies in Multivariate Data via Coin-Flip Statistics
Mar 31, 2025



Detecting localized density differences in multivariate data is a crucial task in computational science. Such anomalies can indicate a critical system failure, lead to a groundbreaking scientific discovery, or reveal unexpected changes in data distribution. We introduce EagleEye, an anomaly detection method to compare two multivariate datasets with the aim of identifying local density anomalies, namely over- or under-densities affecting only localised regions of the feature space. Anomalies are detected by modelling, for each point, the ordered sequence of its neighbours' membership label as a coin-flipping process and monitoring deviations from the expected behaviour of such process. A unique advantage of our method is its ability to provide an accurate, entirely unsupervised estimate of the local signal purity. We demonstrate its effectiveness through experiments on both synthetic and real-world datasets. In synthetic data, EagleEye accurately detects anomalies in multiple dimensions even when they affect a tiny fraction of the data. When applied to a challenging resonant anomaly detection benchmark task in simulated Large Hadron Collider data, EagleEye successfully identifies particle decay events present in just 0.3% of the dataset. In global temperature data, EagleEye uncovers previously unidentified, geographically localised changes in temperature fields that occurred in the most recent years. Thanks to its key advantages of conceptual simplicity, computational efficiency, trivial parallelisation, and scalability, EagleEye is widely applicable across many fields.
Cosmology with Persistent Homology: Parameter Inference via Machine Learning
Dec 19, 2024Building upon [2308.02636], this article investigates the potential constraining power of persistent homology for cosmological parameters and primordial non-Gaussianity amplitudes in a likelihood-free inference pipeline. We evaluate the ability of persistence images (PIs) to infer parameters, compared to the combined Power Spectrum and Bispectrum (PS/BS), and we compare two types of models: neural-based, and tree-based. PIs consistently lead to better predictions compared to the combined PS/BS when the parameters can be constrained (i.e., for $\{\Omega_{\rm m}, \sigma_8, n_{\rm s}, f_{\rm NL}^{\rm loc}\}$). PIs perform particularly well for $f_{\rm NL}^{\rm loc}$, showing the promise of persistent homology in constraining primordial non-Gaussianity. Our results show that combining PIs with PS/BS provides only marginal gains, indicating that the PS/BS contains little extra or complementary information to the PIs. Finally, we provide a visualization of the most important topological features for $f_{\rm NL}^{\rm loc}$ and for $\Omega_{\rm m}$. This reveals that clusters and voids (0-cycles and 2-cycles) are most informative for $\Omega_{\rm m}$, while $f_{\rm NL}^{\rm loc}$ uses the filaments (1-cycles) in addition to the other two types of topological features.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021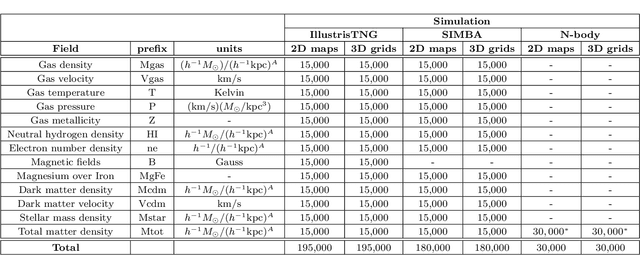

We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.
A Deep Learning Approach for Active Anomaly Detection of Extragalactic Transients
Mar 22, 2021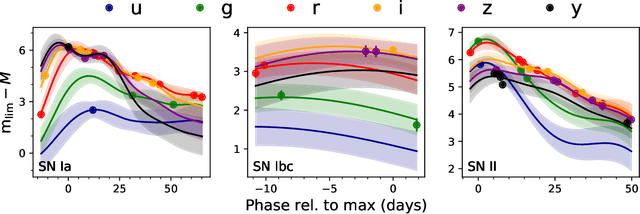
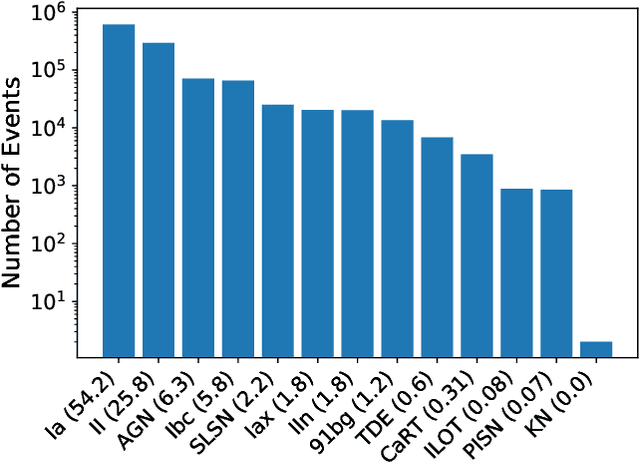
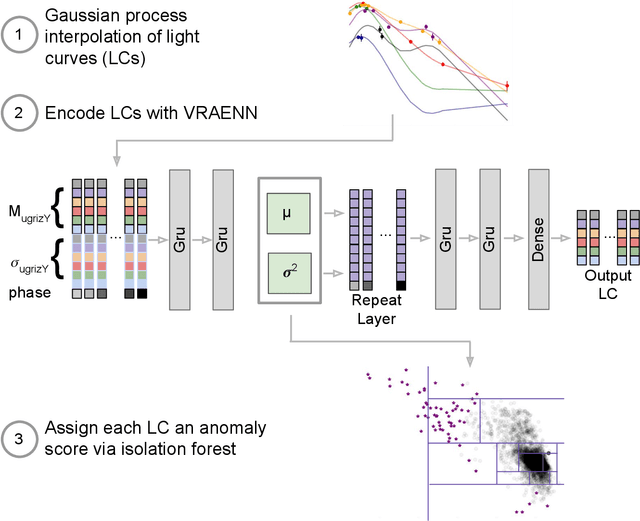
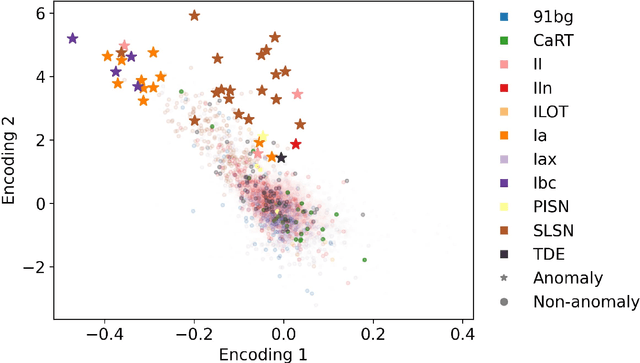
There is a shortage of multi-wavelength and spectroscopic followup capabilities given the number of transient and variable astrophysical events discovered through wide-field, optical surveys such as the upcoming Vera C. Rubin Observatory. From the haystack of potential science targets, astronomers must allocate scarce resources to study a selection of needles in real time. Here we present a variational recurrent autoencoder neural network to encode simulated Rubin Observatory extragalactic transient events using 1% of the PLAsTiCC dataset to train the autoencoder. Our unsupervised method uniquely works with unlabeled, real time, multivariate and aperiodic data. We rank 1,129,184 events based on an anomaly score estimated using an isolation forest. We find that our pipeline successfully ranks rarer classes of transients as more anomalous. Using simple cuts in anomaly score and uncertainty, we identify a pure (~95% pure) sample of rare transients (i.e., transients other than Type Ia, Type II and Type Ibc supernovae) including superluminous and pair-instability supernovae. Finally, our algorithm is able to identify these transients as anomalous well before peak, enabling real-time follow up studies in the era of the Rubin Observatory.
Anomaly Detection for Multivariate Time Series of Exotic Supernovae
Oct 21, 2020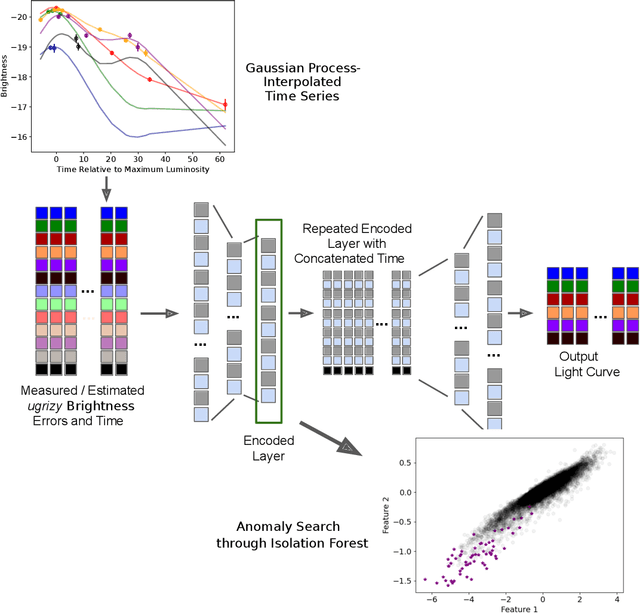
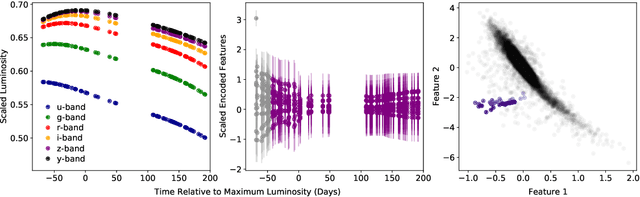
Supernovae mark the explosive deaths of stars and enrich the cosmos with heavy elements. Future telescopes will discover thousands of new supernovae nightly, creating a need to flag astrophysically interesting events rapidly for followup study. Ideally, such an anomaly detection pipeline would be independent of our current knowledge and be sensitive to unexpected phenomena. Here we present an unsupervised method to search for anomalous time series in real time for transient, multivariate, and aperiodic signals. We use a RNN-based variational autoencoder to encode supernova time series and an isolation forest to search for anomalous events in the learned encoded space. We apply this method to a simulated dataset of 12,159 supernovae, successfully discovering anomalous supernovae and objects with catastrophically incorrect redshift measurements. This work is the first anomaly detection pipeline for supernovae which works with online datastreams.
Meta-Learning One-Class Classification with DeepSets: Application in the Milky Way
Jul 08, 2020
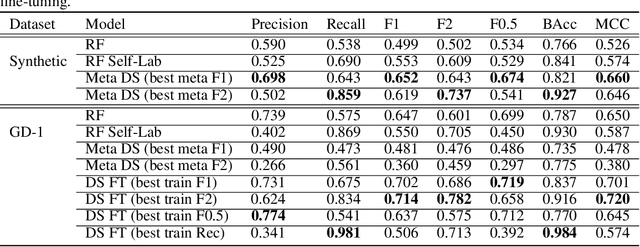

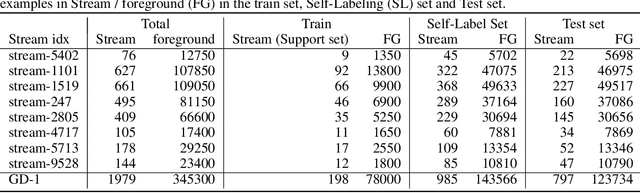
We explore in this paper the use of neural networks designed for point-clouds and sets on a new meta-learning task. We present experiments on the astronomical challenge of characterizing the stellar population of stellar streams. Stellar streams are elongated structures of stars in the outskirts of the Milky Way that form when a (small) galaxy breaks up under the Milky Way's gravitational force. We consider that we obtain, for each stream, a small 'support set' of stars that belongs to this stream. We aim to predict if the other stars in that region of the sky are from that stream or not, similar to one-class classification. Each "stream task" could also be transformed into a binary classification problem in a highly imbalanced regime (or supervised anomaly detection) by using the much bigger set of "other" stars and considering them as noisy negative examples. We propose to study the problem in the meta-learning regime: we expect that we can learn general information on characterizing a stream's stellar population by meta-learning across several streams in a fully supervised regime, and transfer it to new streams using only positive supervision. We present a novel use of Deep Sets, a model developed for point-cloud and sets, trained in a meta-learning fully supervised regime, and evaluated in a one-class classification setting. We compare it against Random Forests (with and without self-labeling) in the classic setting of binary classification, retrained for each task. We show that our method outperforms the Random-Forests even though the Deep Sets is not retrained on the new tasks, and accesses only a small part of the data compared to the Random Forest. We also show that the model performs well on a real-life stream when including additional fine-tuning.
Dalek -- a deep-learning emulator for TARDIS
Jul 03, 2020
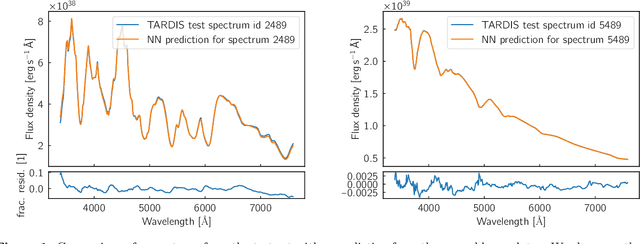

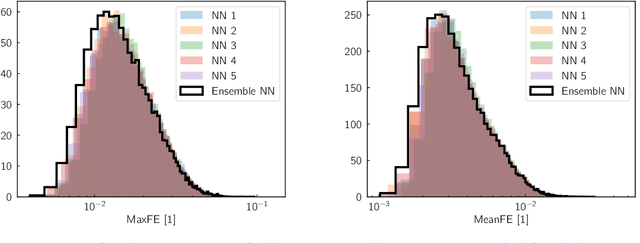
Supernova spectral time series contain a wealth of information about the progenitor and explosion process of these energetic events. The modeling of these data requires the exploration of very high dimensional posterior probabilities with expensive radiative transfer codes. Even modest parametrizations of supernovae contain more than ten parameters and a detailed exploration demands at least several million function evaluations. Physically realistic models require at least tens of CPU minutes per evaluation putting a detailed reconstruction of the explosion out of reach of traditional methodology. The advent of widely available libraries for the training of neural networks combined with their ability to approximate almost arbitrary functions with high precision allows for a new approach to this problem. Instead of evaluating the radiative transfer model itself, one can build a neural network proxy trained on the simulations but evaluating orders of magnitude faster. Such a framework is called an emulator or surrogate model. In this work, we present an emulator for the TARDIS supernova radiative transfer code applied to Type Ia supernova spectra. We show that we can train an emulator for this problem given a modest training set of a hundred thousand spectra (easily calculable on modern supercomputers). The results show an accuracy on the percent level (that are dominated by the Monte Carlo nature of TARDIS and not the emulator) with a speedup of several orders of magnitude. This method has a much broader set of applications and is not limited to the presented problem.
From Dark Matter to Galaxies with Convolutional Neural Networks
Oct 17, 2019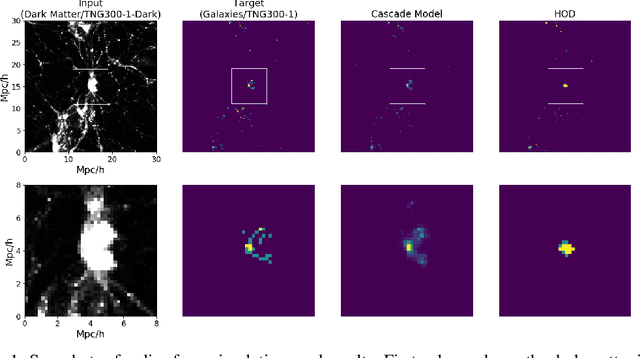
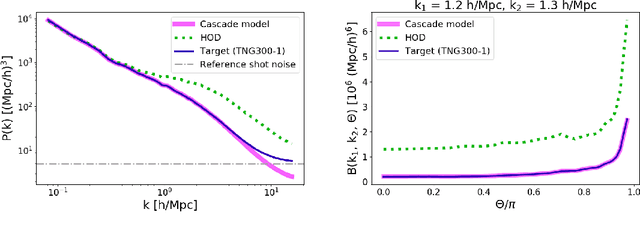
Cosmological simulations play an important role in the interpretation of astronomical data, in particular in comparing observed data to our theoretical expectations. However, to compare data with these simulations, the simulations in principle need to include gravity, magneto-hydrodyanmics, radiative transfer, etc. These ideal large-volume simulations (gravo-magneto-hydrodynamical) are incredibly computationally expensive which can cost tens of millions of CPU hours to run. In this paper, we propose a deep learning approach to map from the dark-matter-only simulation (computationally cheaper) to the galaxy distribution (from the much costlier cosmological simulation). The main challenge of this task is the high sparsity in the target galaxy distribution: space is mainly empty. We propose a cascade architecture composed of a classification filter followed by a regression procedure. We show that our result outperforms a state-of-the-art model used in the astronomical community, and provides a good trade-off between computational cost and prediction accuracy.
From Dark Matter to Galaxies with Convolutional Networks
Apr 01, 2019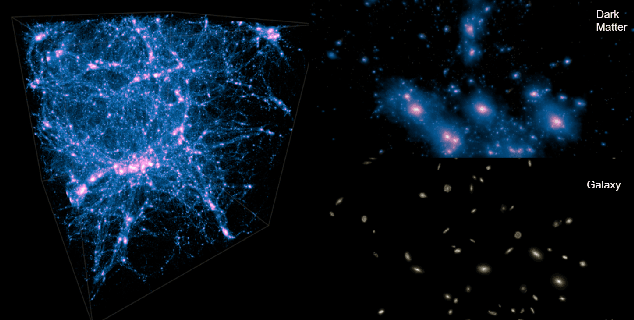
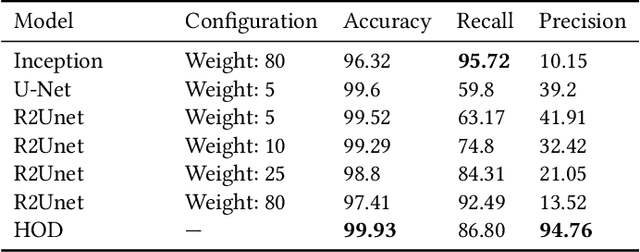
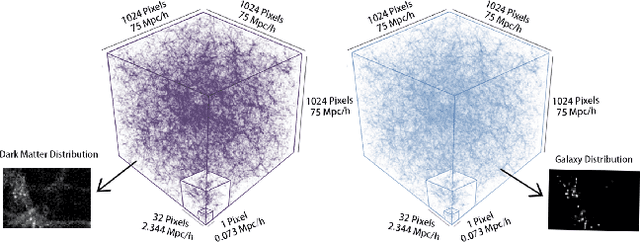
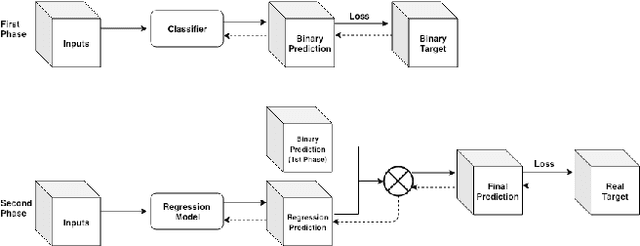
Cosmological surveys aim at answering fundamental questions about our Universe, including the nature of dark matter or the reason of unexpected accelerated expansion of the Universe. In order to answer these questions, two important ingredients are needed: 1) data from observations and 2) a theoretical model that allows fast comparison between observation and theory. Most of the cosmological surveys observe galaxies, which are very difficult to model theoretically due to the complicated physics involved in their formation and evolution; modeling realistic galaxies over cosmological volumes requires running computationally expensive hydrodynamic simulations that can cost millions of CPU hours. In this paper, we propose to use deep learning to establish a mapping between the 3D galaxy distribution in hydrodynamic simulations and its underlying dark matter distribution. One of the major challenges in this pursuit is the very high sparsity in the predicted galaxy distribution. To this end, we develop a two-phase convolutional neural network architecture to generate fast galaxy catalogues, and compare our results against a standard cosmological technique. We find that our proposed approach either outperforms or is competitive with traditional cosmological techniques. Compared to the common methods used in cosmology, our approach also provides a nice trade-off between time-consumption (comparable to fastest benchmark in the literature) and the quality and accuracy of the predicted simulation. In combination with current and upcoming data from cosmological observations, our method has the potential to answer fundamental questions about our Universe with the highest accuracy.