 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotated Bitboards in FUSc# and Reinforcement Learning in Computer Chess and Beyond
Mar 13, 2025There exist several techniques for representing the chess board inside the computer. In the first part of this paper, the concepts of the bitboard-representation and the advantages of (rotated) bitboards in move generation are explained. In order to illustrate those ideas practice, the concrete implementation of the move-generator in FUSc# is discussed and we explain a technique how to verify the move-generator with the "perft"-command. We show that the move-generator of FUSc# works 100% correct. The second part of this paper deals with reinforcement learning in computer chess (and beyond). We exemplify the progress that has been made in this field in the last 15-20 years by comparing the "state of the art" from 2002-2008, when FUSc# was developed, with recent innovations connected to "AlphaZero". We discuss how a "FUSc#-Zero" could be implemented and what would be necessary to reduce the number of training games necessary to achieve a good performance. This can be seen as a test case to the general prblem of improving "sample effciency" in reinforcement learning. In the final part, we move beyond computer chess, as the importance of sample effciency extends far beyond board games into a wide range of applications where data is costly, diffcult to obtain, or time consuming to generate. We review some application of the ideas developed in AlphaZero in other domains, i.e. the "other Alphas" like AlphaFold, AlphaTensor, AlphaGeometry and AlphaProof. We also discuss future research and the potential for such methods for ecological economic planning.
PICZL: Image-based Photometric Redshifts for AGN
Nov 13, 2024



Computing photo-z for AGN is challenging, primarily due to the interplay of relative emissions associated with the SMBH and its host galaxy. SED fitting methods, effective in pencil-beam surveys, face limitations in all-sky surveys with fewer bands available, lacking the ability to capture the AGN contribution to the SED accurately. This limitation affects the many 10s of millions of AGN clearly singled out and identified by SRG/eROSITA. Our goal is to significantly enhance photometric redshift performance for AGN in all-sky surveys while avoiding the need to merge multiple data sets. Instead, we employ readily available data products from the 10th Data Release of the Imaging Legacy Survey for DESI, covering > 20,000 deg$^{2}$ with deep images and catalog-based photometry in the grizW1-W4 bands. We introduce PICZL, a machine-learning algorithm leveraging an ensemble of CNNs. Utilizing a cross-channel approach, the algorithm integrates distinct SED features from images with those obtained from catalog-level data. Full probability distributions are achieved via the integration of Gaussian mixture models. On a validation sample of 8098 AGN, PICZL achieves a variance $\sigma_{\textrm{NMAD}}$ of 4.5% with an outlier fraction $\eta$ of 5.6%, outperforming previous attempts to compute accurate photo-z for AGN using ML. We highlight that the model's performance depends on many variables, predominantly the depth of the data. A thorough evaluation of these dependencies is presented in the paper. Our streamlined methodology maintains consistent performance across the entire survey area when accounting for differing data quality. The same approach can be adopted for future deep photometric surveys such as LSST and Euclid, showcasing its potential for wide-scale realisation. With this paper, we release updated photo-z (including errors) for the XMM-SERVS W-CDF-S, ELAIS-S1 and LSS fields.
Probabilistic Dalek -- Emulator framework with probabilistic prediction for supernova tomography
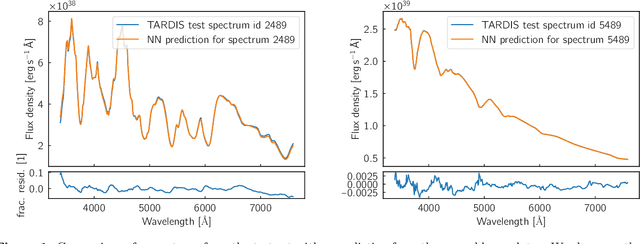
Sep 20, 2022

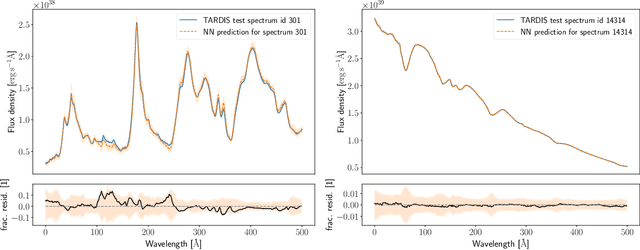

Supernova spectral time series can be used to reconstruct a spatially resolved explosion model known as supernova tomography. In addition to an observed spectral time series, a supernova tomography requires a radiative transfer model to perform the inverse problem with uncertainty quantification for a reconstruction. The smallest parametrizations of supernova tomography models are roughly a dozen parameters with a realistic one requiring more than 100. Realistic radiative transfer models require tens of CPU minutes for a single evaluation making the problem computationally intractable with traditional means requiring millions of MCMC samples for such a problem. A new method for accelerating simulations known as surrogate models or emulators using machine learning techniques offers a solution for such problems and a way to understand progenitors/explosions from spectral time series. There exist emulators for the TARDIS supernova radiative transfer code but they only perform well on simplistic low-dimensional models (roughly a dozen parameters) with a small number of applications for knowledge gain in the supernova field. In this work, we present a new emulator for the radiative transfer code TARDIS that not only outperforms existing emulators but also provides uncertainties in its prediction. It offers the foundation for a future active-learning-based machinery that will be able to emulate very high dimensional spaces of hundreds of parameters crucial for unraveling urgent questions in supernovae and related fields.
Dalek -- a deep-learning emulator for TARDIS
Jul 03, 2020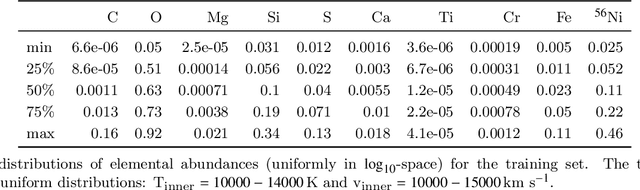

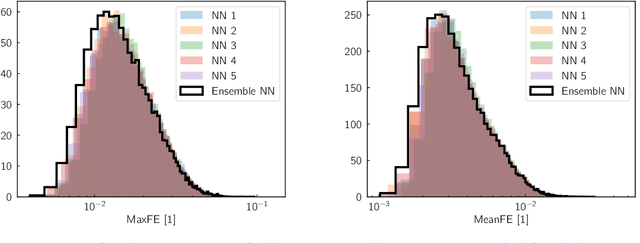
Supernova spectral time series contain a wealth of information about the progenitor and explosion process of these energetic events. The modeling of these data requires the exploration of very high dimensional posterior probabilities with expensive radiative transfer codes. Even modest parametrizations of supernovae contain more than ten parameters and a detailed exploration demands at least several million function evaluations. Physically realistic models require at least tens of CPU minutes per evaluation putting a detailed reconstruction of the explosion out of reach of traditional methodology. The advent of widely available libraries for the training of neural networks combined with their ability to approximate almost arbitrary functions with high precision allows for a new approach to this problem. Instead of evaluating the radiative transfer model itself, one can build a neural network proxy trained on the simulations but evaluating orders of magnitude faster. Such a framework is called an emulator or surrogate model. In this work, we present an emulator for the TARDIS supernova radiative transfer code applied to Type Ia supernova spectra. We show that we can train an emulator for this problem given a modest training set of a hundred thousand spectra (easily calculable on modern supercomputers). The results show an accuracy on the percent level (that are dominated by the Monte Carlo nature of TARDIS and not the emulator) with a speedup of several orders of magnitude. This method has a much broader set of applications and is not limited to the presented problem.
Collaborative Nested Sampling: Big Data vs. complex physical models
Oct 02, 2018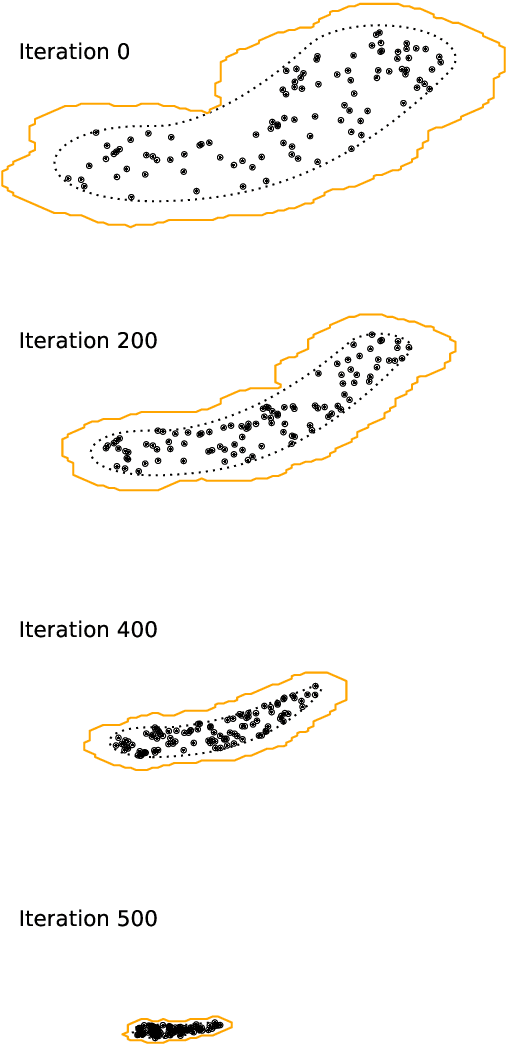
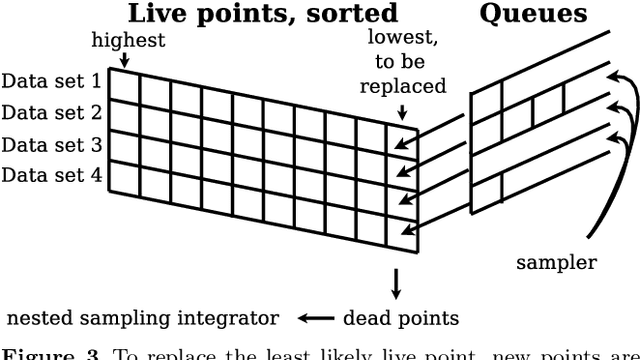

The data torrent unleashed by current and upcoming astronomical surveys demands scalable analysis methods. Many machine learning approaches scale well, but separating the instrument measurement from the physical effects of interest, dealing with variable errors, and deriving parameter uncertainties is often an after-thought. Classic forward-folding analyses with Markov Chain Monte Carlo or Nested Sampling enable parameter estimation and model comparison, even for complex and slow-to-evaluate physical models. However, these approaches require independent runs for each data set, implying an unfeasible number of model evaluations in the Big Data regime. Here I present a new algorithm, collaborative nested sampling, for deriving parameter probability distributions for each observation. Importantly, the number of physical model evaluations scales sub-linearly with the number of data sets, and no assumptions about homogeneous errors, Gaussianity, the form of the model or heterogeneity/completeness of the observations need to be made. Collaborative nested sampling has immediate application in speeding up analyses of large surveys, integral-field-unit observations, and Monte Carlo simulations.