 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks for Generating Better Local Optima in Topology Optimization
Jul 25, 2024



Neural networks have recently been employed as material discretizations within adjoint optimization frameworks for inverse problems and topology optimization. While advantageous regularization effects and better optima have been found for some inverse problems, the benefit for topology optimization has been limited -- where the focus of investigations has been the compliance problem. We demonstrate how neural network material discretizations can, under certain conditions, find better local optima in more challenging optimization problems, where we here specifically consider acoustic topology optimization. The chances of identifying a better optimum can significantly be improved by running multiple partial optimizations with different neural network initializations. Furthermore, we show that the neural network material discretization's advantage comes from the interplay with the Adam optimizer and emphasize its current limitations when competing with constrained and higher-order optimization techniques. At the moment, this discretization has only been shown to be beneficial for unconstrained first-order optimization.
Dalek -- a deep-learning emulator for TARDIS
Jul 03, 2020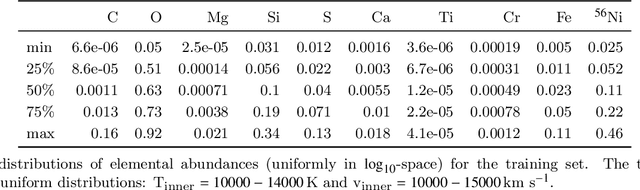
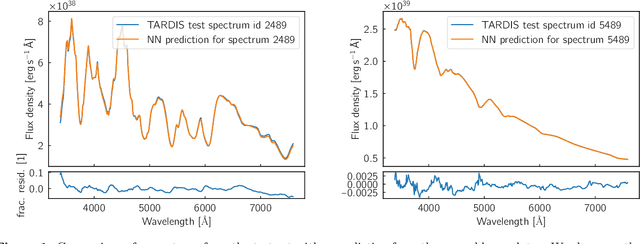

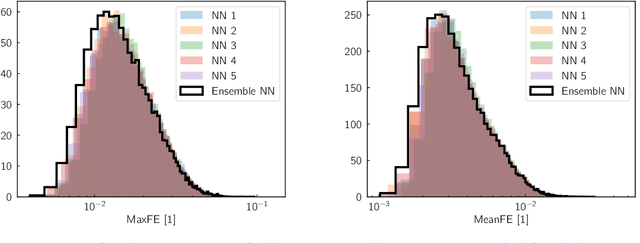
Supernova spectral time series contain a wealth of information about the progenitor and explosion process of these energetic events. The modeling of these data requires the exploration of very high dimensional posterior probabilities with expensive radiative transfer codes. Even modest parametrizations of supernovae contain more than ten parameters and a detailed exploration demands at least several million function evaluations. Physically realistic models require at least tens of CPU minutes per evaluation putting a detailed reconstruction of the explosion out of reach of traditional methodology. The advent of widely available libraries for the training of neural networks combined with their ability to approximate almost arbitrary functions with high precision allows for a new approach to this problem. Instead of evaluating the radiative transfer model itself, one can build a neural network proxy trained on the simulations but evaluating orders of magnitude faster. Such a framework is called an emulator or surrogate model. In this work, we present an emulator for the TARDIS supernova radiative transfer code applied to Type Ia supernova spectra. We show that we can train an emulator for this problem given a modest training set of a hundred thousand spectra (easily calculable on modern supercomputers). The results show an accuracy on the percent level (that are dominated by the Monte Carlo nature of TARDIS and not the emulator) with a speedup of several orders of magnitude. This method has a much broader set of applications and is not limited to the presented problem.